
嵌入式C
嵌入式C
CPU介绍
提醒
背景:CPU的运行速度收到内存带宽的严重限制。
方法有二:好的内存条、使用Cache机制
Cache
Static Random Access Memory :SRAM,叫做高速缓冲存储器,利用时空局部性,通过缓存一部分内存的指令和数据,减少CPU访问内存的次数。
缓存里面每块空间一般有一个特殊的标记位,叫做DIrty Bit ,用来记录这种变化,当Cache需要刷新,若此时Cache空间满了,会检查DIrty BIt 的变化把这些变化的数据写入到RAM里面。(这个简单概述,详细要看操作系统导论)
多级缓存的机制,综合考虑造价以及效率而诞生。
但是有一些处理器也是没有缓存的,比如C51单片机,cortex-M0等ARM处理器是没有cache的:
- 低功耗、低成本
- 处理器的工作频率不高
- Cache不能保证实时性
流水线提高CPU性能
一条指令的执行要经过取指令、翻译指令、执行指令三个基本流程。CPU内部的电路分为不同单元:取指单元、译码单元、执行单元。

提醒
每条指令执行的时间还是没有改变,改变的是单元的空闲时间就是压榨。
从整体上看以及接近于一个时钟时间执行一条指令。
超流水技术
5级以上的流水线称为超流水线结构。
想要提升CPU的主频关键在于减少流水线中每一级流水的执行时间,消除木桶短板。
- 优化流水线各级流水线性能,受限于当前集成电路的设计水平
- 依靠半导体的制造工艺,面积越小,发热越小更容易提升主频
- 增加流水线深度(流水线越深电路越复杂,增大芯片面积,增大功耗;也可能导致,第一条指令还没有执行完毕就开始执行第二条,当程序指令中存在跳转和分支结构的时候,下面预取的指令就会失效,需要到跳转的地方重新取指令执行。——流水线冒险)
现在经典的CPU指令一般分为5级:取指、译码、执行、访问内存、写回。
还可以通过乱序执行,解决流水线冲突,或者可以重排指令执行的顺序。
@ SIMD和NEON
一般指令由操作码和操作数构成,不同类型的指令,其操作数的数量可能不一样。
SIMD:单指令多数据,SISD:单指令单数据
MMX、SSE、FMA
提示
单发射处理器:每个时钟周期只能从存储器取出一条指令
多发射处理器:一个时钟周期内可以执行多条指令。处理器内部一般由多个执行单元,多发射的处理器可以做到同时分发多条指令到不同的执行单元。
静态发射:可以在编译阶段将并行的指令打包,合并到一个64位的长指令中,如果找不到配对的指令,采用空指令进行补充-》这种方式称为超长指令集架构。(VLIW)
动态发射:SuperScalar:超标量处理器,在多发射的实现过程中会增加额外的取指单元、译码单元、逻辑控制单元等硬件电路,在指令运行时候,将串行的指令序列转换为并行的指令序列。(代价是增大的芯片的面积以及功耗。
新架构的处理器没有指令集兼容的历史包袱,一般采用显式并行指令计算(EPIC)。原理就是在指令中使用三个比特位来表示相邻的两条指令有无相关性、当前指令要不要等上一条指令运行结束之后才能执行。
多核与单核
片上多核互联技术:
早期的计算机,cpu与内存,i/o模块直接相连(星形连接),通信效率高,但是资源浪费大,扩展性不好。
在单核的时代,总线的方式是最理想最经济的做法,但是多核时代下,某一时刻只允许一对设备进行通讯成为了缺陷。
解决办法:
采用线性阵列,分段采用总线。
采用交叉开关,会导致芯片面积和功耗急剧上升,为了缓解这一矛盾马,可以采用层次化叫交叉开关,在局部构件一个节点的集群,然后在上一层将每个局部的集群看成一个节点,再通过合适的方式进行链接。(层次化交叉开关一般在4核以下的cpu上面使用)
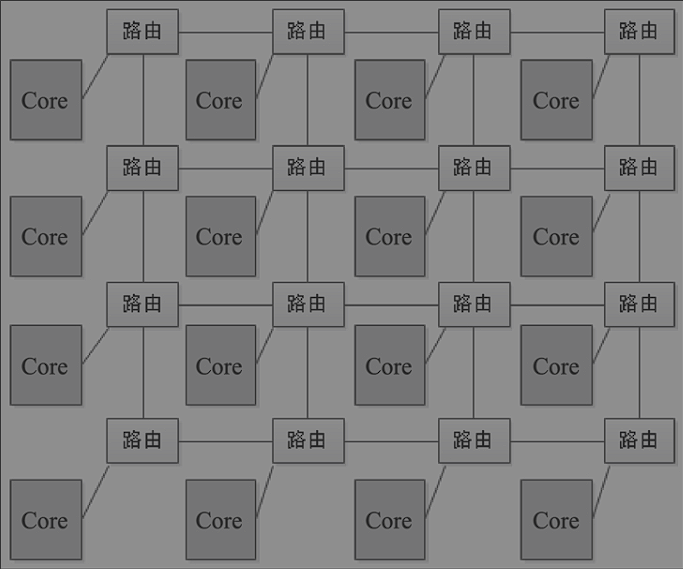
RIng Bus 结构: 将总线和交叉开关结合起来,形成环状,远离的两个core之间可以通过开关路由通信,八核常用。
当环上的core很多的时候,延迟上升,此时采用一种比较流行的片上交互技术之:片上网络NOC,
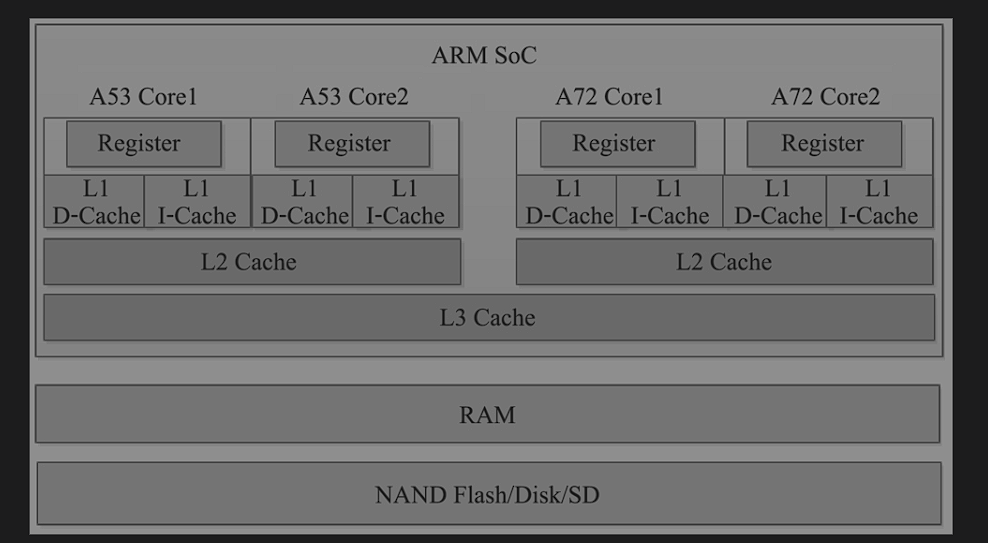
image-20250331220631916 当多个core集成到一个处理器上的时候,当cpu的负载很大的时候,多个core一起确实可以提高效率,但是当任务不多的时候,一核工作其他围观空转,为了避免这种情况ARM推出了big.LITTLE架构,也就是大小核架构。
ARM处理器针对多核采用了分层设计,将所有的高性能的核心放到了一个簇里卖弄,构成了big Clusster ,将多个低功耗的核心放到了另一个Cluster里里面构成了LITTLE CLuster ,处理器每个core都有自己的独立数据cache,和指令cache ,每个Cluster 共享L2 Cache 。为了保证多个core运行的时候Cache和RAM的数据相同,两个Cluster 之间通过缓存一致性接口相连,不仅保证多个Core之间的高效通信,还通过检测电路,保证多个Cache之间、Cache 与RAM之间的数据一致性。
image-20250331221550331

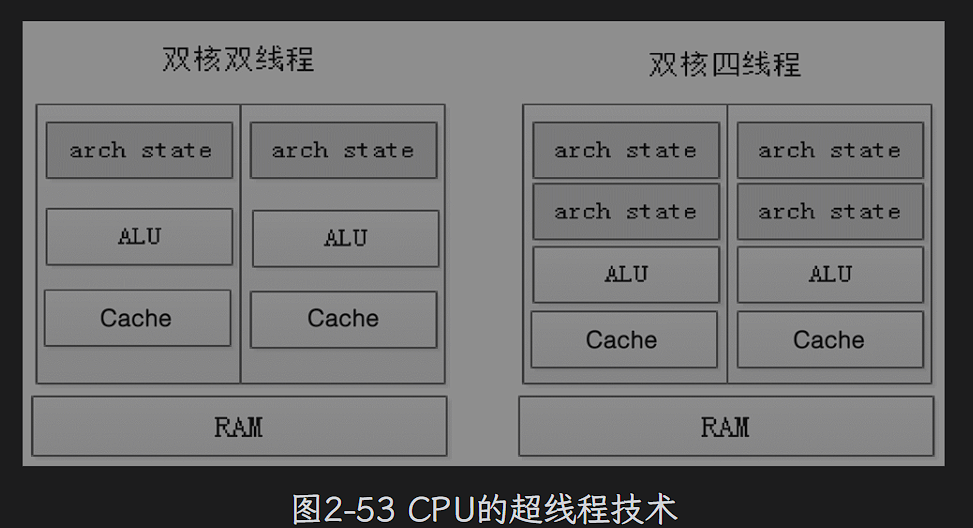
超线程技术:
通过增加一定的控制逻辑电路,使用特殊的指令可以将一个物理处理器当作;两个逻辑处理器使用,每个逻辑处理器可以分配一个线程运行,从而最大限度提升cpu的资源利用率。
image-20250331221953292
异构计算
what is?
简而言之就是集成不同架构的core,协同工作,都有什么?
总线和地址
地址:
计算机的内存就是将一系列的存储单元和译码器组装在一起。每个存储单元对应一个编号,当CPU想要访问一个存储单元时,可通过CPU管脚发出一组信号,经过译码器译码,选中与这个信号对应的存储单元。在有MMU的CPU平台下,程序运行一般使用的是虚拟地址,MMU会把虚拟地址转换为物理地址,然后通过CPU管脚发送出去。
总线:
CPU与内存RAM直接相连的话,每个存储单元的地址就可以直接确定。
现在的CPU不是直接相连而是通过总线链接。
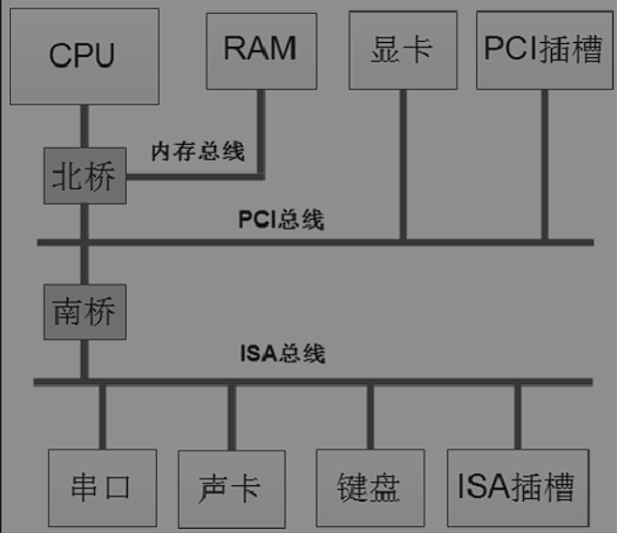
总线是各种数字信号的集合,包括地址信号、数据信号、控制信号,有些总线可以为某些总线上的设备提供电源。不同的总线通过桥来链接。桥一般是一个芯片组电路,将总线的电子信号翻译成另一种总线的电子信号。
**总线的编址方式:**统一编址、独立编址
统一编址模式下,内存RAM、外部设备控制器的寄存器、集成在外部设备控制器内部的RAM共享CPU的可寻址空间。
独立编址,内存RAM与外部设备的寄存器独立编址,分别占用不同的地址模式
指令集和微架构
指令集:
计算机体系架构的一部分,指令集一个标准规范,指令集的最终实现就是微架构,就是CPU内部的各种译码和执行电路。
微架构:
MIcroarchitecture ,处理器架构,集成电路工程师在设计处理器时,会按照指令集规定的指令,指令集在CPU处理器内部的具体硬件电路的实现,就是微架构。可以针对相同指令集,设计出不同的微架构。在嵌入式处理器中,微架构不等于SOC,微架构一般称为CPU内核。
内核授权,又称为微架构授权,使用AMBA总线和各种IP模型链接就可以搭建一个片上系统,即SoC芯片。
汇编语言:
为二级制指令定义了各种助记符,这种助记符就是汇编指令。
ARM体系结构与汇编语言
计算机的指令集可以分为:复杂指令集(CISC)、精简指令集(RISC)、显式并行指令集(EPIC)、超长指令字指令集(VLIW)
RISC指令集有以下特点: 要用寄存器、固定、用寄存器而不是堆栈
助记
CPU不能直接操作内存的数据,需要寄存器配合
有固定的指令长度和、单指令的周期固定
更偏向于寄存器的使用
Load/Store架构,CPU不能直接处理内存中的数据,要先将内存中的数据load到寄存器里面,然后将结果store到内存里面。
固定的指令长度、单周期指令
倾向于使用更多的寄存器来存储数据,而不是使用内存里面的堆栈,效率更高
与原本的RISC的差异:桶型移位寄存器、有特例
ARM有桶型移位寄存器,单周期内可以完成数据的各种移位操作
并不是所有的ARM指令都是单周期的
ARM有16的Thumb指令集,是32位ARM指令集的压缩形式,提高了代码密度
条件执行:通过指令组合,减少分支指令数目
增加DSP、SIMD/NENON等指令
注
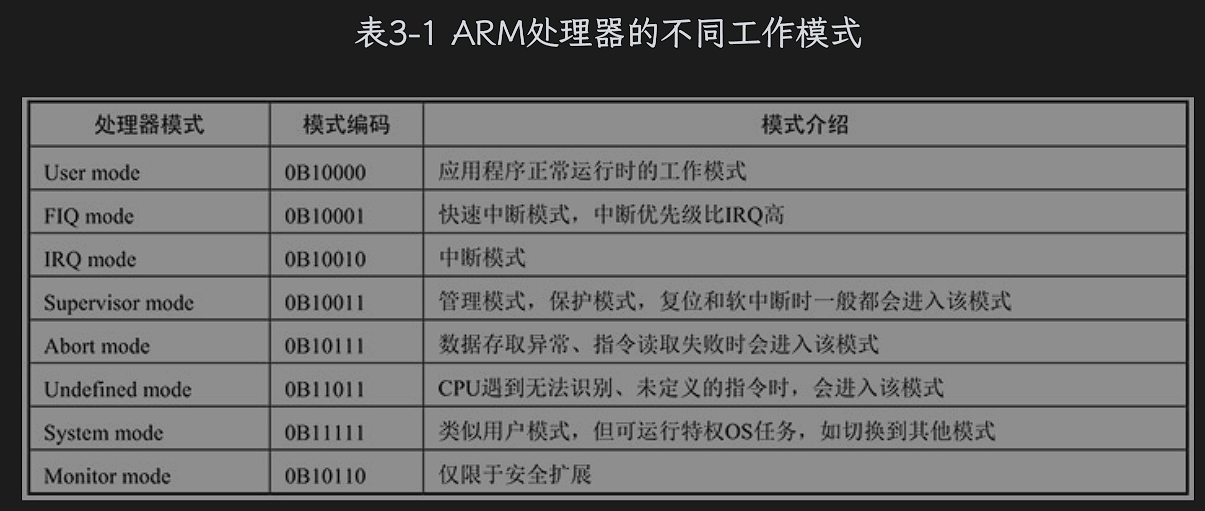
在ARM处理器内部,除了基本的算术运算单元、逻辑运算单元、浮点运算单元和控制单元还有一些列寄存器,包括各种通用寄存器、状态寄存器、控制寄存器。
ARM处理器的寄存器可以分为通用寄存器和专用寄存器两种。
ARM里面有一个当前处理器状态寄存器CPSR。
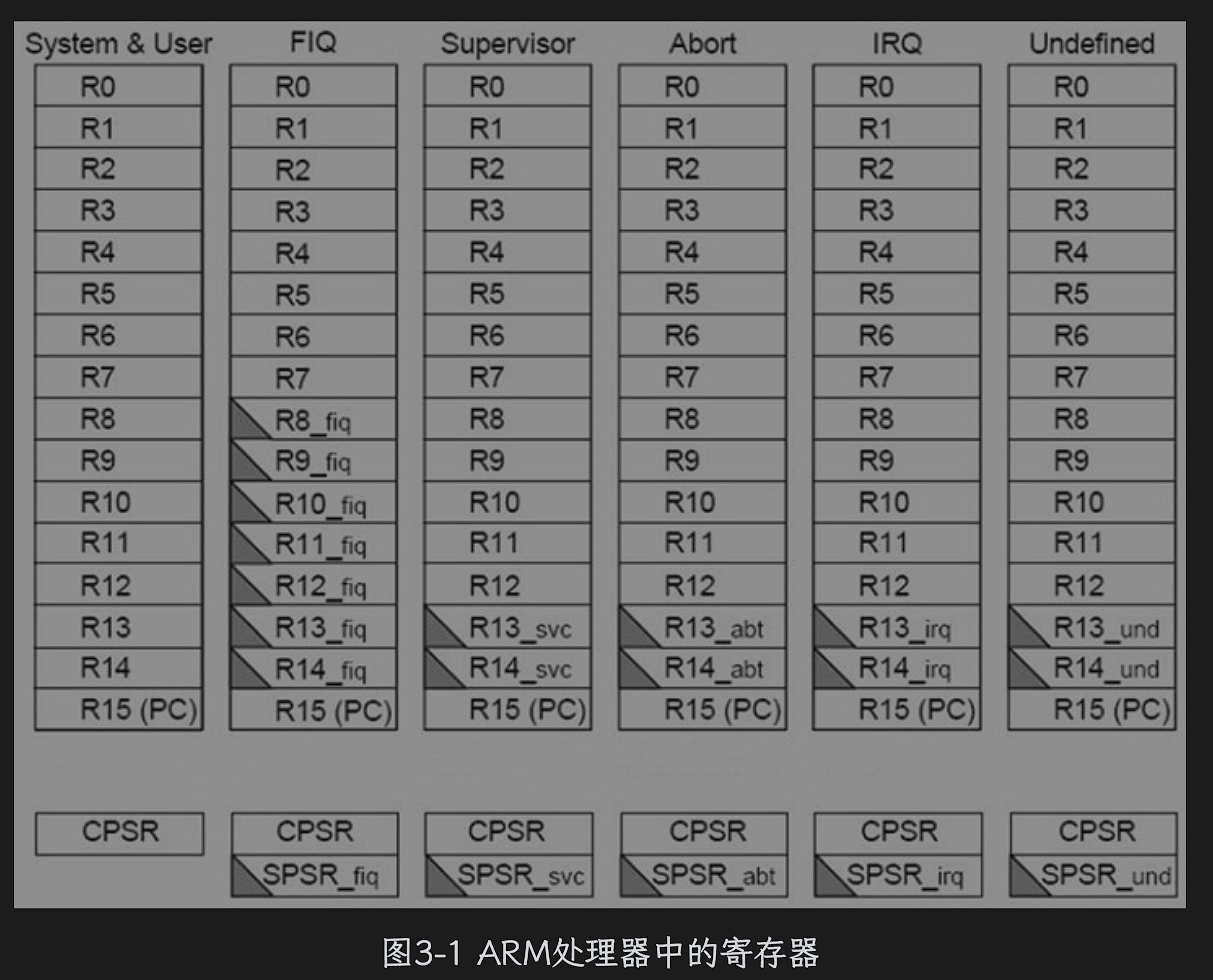
注
R0~R3用来传递函数参数,R4 ~ R11 用来保存程序运算的中间结果和函数的局部变量,R12通常作为函数调用过程中的临时寄存器。
ARM处理器有多种工作模式,除了这些在各个模式下通用的寄存器,还有一些寄存器在各自的工作模式下是独立存在的,如R13、R14、R15、CPSP、SPSR寄存器,在每个工作模式下都有自己单独的寄存器。R13寄存器又称为堆栈指针寄存器(Stack Pointer,SP),用来维护和管理函数调用过程中的栈帧变化,R13总是指向当前正在运行的函数的栈帧,一般不能再用作其他用途。R14寄存器又称为链接寄存器(Link Register,LR),在函数调用过程中主要用来保存上一级函数调用者的返回地址。寄存器R15又称为程序计数器(Program Counter,PC),CPU从内存取指令执行,就是默认从PC保存的地址中取的,每取一次指令,PC寄存器的地址值自动增加。
CPSR寄存器的标志位、控制位的详细说明
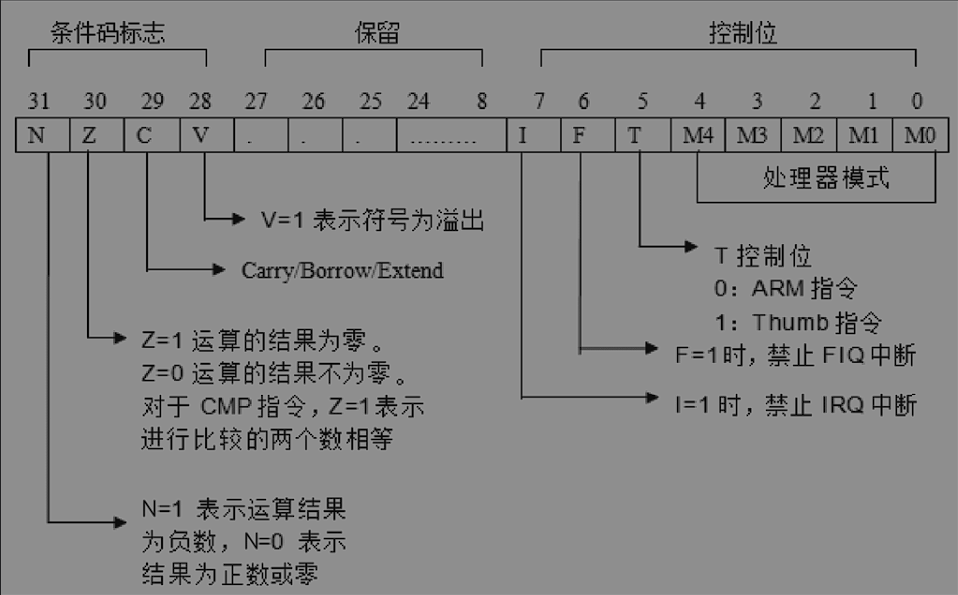
在每种工作模式下面都有一个单独的程序状态保存寄存器SPSR,当处理器切换工作模式或者发生异常的时候SPSR用来保存当前工作模式下的处理器现场。便于ARM处理器从异常返回可以通过寄存器恢复。
FIQ模式:为了快速响应中断,减少中断现场保护带来的时间开销。
ARM汇编
注
一个完整的ARM指令通常由操作码+操作数组成
<opcode> {<cond> {s} <Rd> ,<Rn> {,<operand2}}<>括起来是表示必选,{}表示可选<opcode>是二进制机器指令的操作码助记符,如MOV、ADD这些汇编指令都是操作码的指令助记符。- cond:执行条件,ARM为减少分支跳转指令个数,允许类似BEQ、BNE等形式的组合指令。
- S:是否影响CPSR寄存器中的标志位,如SUBS指令会影响CPSR寄存器中的N、Z、C、V标志位,而SUB指令不会。
- Rd:目标寄存器
- Rn:第一个操作数的寄存器
- operand2:第二个可选操作数,灵活使用第二个操作数可以提高代码效率。
前面提到过ARM的指令集属于RISC指令集,所以由load/store的过程
存储访问指令:
所以常用的Load/Store指令的使用有:
LDR R1,[R0] ;//将R0值作为地址,将该地址上的数据保存到R1
STR R1,[R0] ;//将R0做地址,将R1的值写到这个地址
LDRB/STRB ;//每次读写一个字节,LDR/STR默认每次读写4字节
LSM/STM ;//批量加载/存储指令,在一组寄存器和一片内存之间传输数据
SWP R1,R1,[R0];//将R1与R0中地址指向的内存数据进行交换
SWP R1,R2,[R0];//将[R0]存储到R1,将R2写入[R0]这个地方在存储访问指令里面常用的是LDR/STR 和LDM/STM,后者通常用来加载活存储一组寄存器到一片连续的内存,通过和堆栈格式符组合使用,这个还可以模拟堆栈操作。
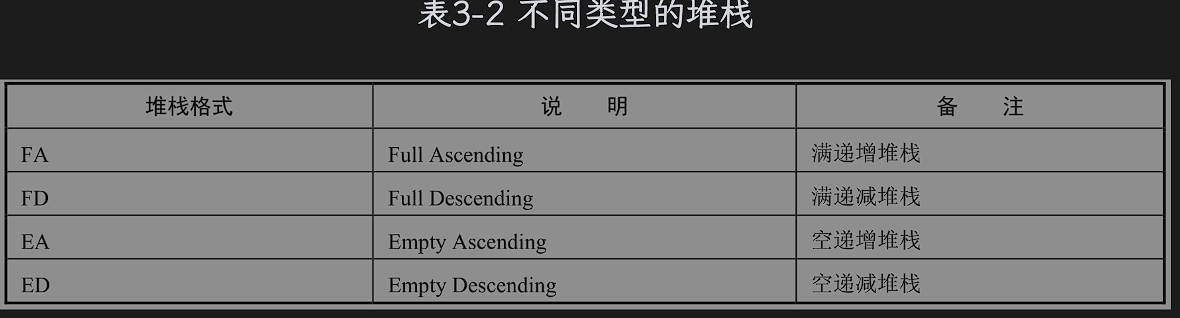
如果栈指针从高地址向低地址那么就是递减栈、如果从低地址往高地址就是递增栈;ARM处理器一般都是满递减堆栈。
eg:将一组寄存器入栈或者从栈中弹出一组寄存器
LDMFD SP!,{R0-R2,R14} ;//将栈里面的元素弹出到寄存器,R14,R0,R1,R2
STMFD SP!,{R0-R2,R14} ;//将上述四个压入内存栈栈的特点是先入先出,栈元素在入栈操作时,STMFD会根据大括号{}中寄存器列表中各个寄存器的顺序,从左往右依次压入堆栈。ARM还专门提供右PUSH和POP指令来执行栈元素的入栈和出栈操作。
PUSH {R0-R2 ,R14} ;//从R0开始依次入栈
POP {R0-R2 ,R14} ;//从R14开始依次出栈数据传送指令:
LDR/STR用来在寄存器和内存之间传输数据,如果要在寄存器之间传输数据可以使用MOV指令
MOV {cond} {S} Rd ,operand2
MVN {cond} {S} Rd ,operand2
//{cond}:条件指令可选项
//{S}:表示是否影响CPSR寄存器的值
//MOVS指令会影响寄存器CPSR的值,而MOV不会
//MVN指令可用来将操作数operand2按位取反后传送到目标寄存器Rd,operand2 可以是一个立即数,也可以是一个寄存器
//eg:
MOV R1,#1; //传1到寄存器R1
MOV R1,R0; //传寄存器R0里面的值到R1
MOV PC,LR; //子程序返回
MVN R0,#0XFF; //将0XFF取反赋值给R0
MVN R0,R1; //将R1寄存器值取反赋值给R0算术逻辑运算指令
算术运算符包括基本的加减乘除、逻辑运算符:与、或、非、异或、清楚等
ADD {cond} {S} Rd ,Rn ,operand2 ;//+
ADC {cond} {S} Rd ,Rn ,operand2 ;//带进位加法
SUB {cond} {S} Rd ,Rn ,operand2 ;//减法
AND ....;//逻辑与
ORR ....;//逻辑或
EOR ....;//异或
BIC ....;//位清除一些示例:
ADD R2 ,R1 ,#1; //R2= R1+1;
ADC R1 ,R1 ,#1; //R1= R1+1+C;(其中C是CPSR寄存器中进位)
SUB R1,R1,R2 ;//R1= R1-R2;
SBC R1,R1,R2 ;//R1= R1-R2-C;
AND R0,R0,#3 ;//保留RO的bit0和1,其余位清除
ORR R0,R0,#3 ;//置位R0的bit0和bit1
EOR R0,R0,#3 ;//反转R0的bit0和bit1
BIC R0,R0,#3 ;//清除R0中的bit0和Bit1operand2操作数详解
#constant //ADD R2,R1, #1;
Rm{,shift}//#constant, n;将立即数constant循环右移n位
ASR #n;//算术右移n位,n∈[1,32]
LSL #n;//逻辑左移n位,n∈[0.31]
LSR #n;//逻辑右移n位
ROR #N;//向右循环移动n位,n∈[1,31]
RRX ;//向右循环移动一位,带扩展
type Rs;//在ARM中可用,其中type指的ASP、LSL、LSR、ROR、Rs 是提供位移量的寄存器的名称
/*eg :*/
ADD R3,R2,R1,LSL #3;//先左移再相加
ADD R3,R2,R1, LSL RO;
ADD IP,IP,#16,20;//先相加再右移比较指令:
比较指令会影响CPSR寄存器的N、Z、C、V标志位
CMP {cond} Rn,operand2;//比较两个数大小
CMN {cond} Rn,operand2;//取负比较CPSR:Z=1表示运算结果为0,N=1表示运算结果为负,N=0表示运算结果非负
条件执行指令
为了提高代码密度,几乎所有的ARM指令都可以根据CPSR寄存器的标志位,通过指令组合实现条件执行。
ARM的条件码:
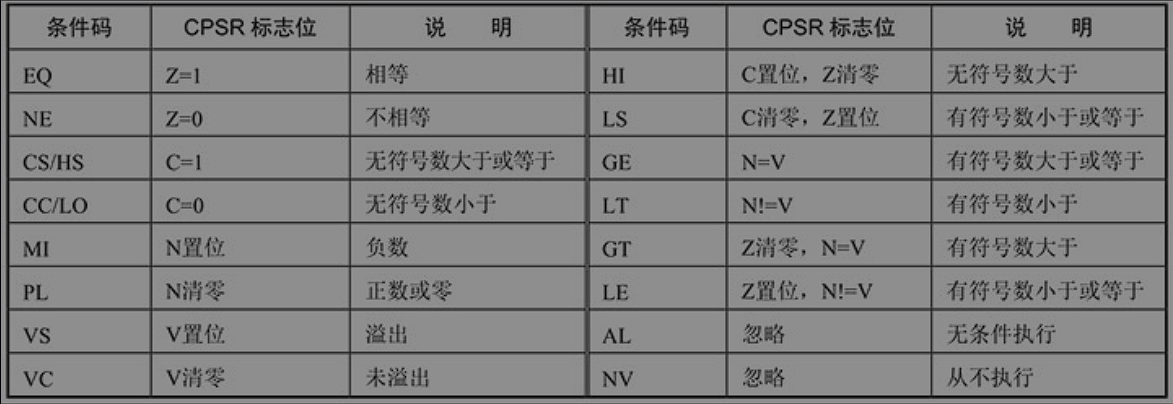
可以集合B跳转指令实现一些组合BNE:组成循环。
AREA COPY, CODE, READONLY ; 定义一个只读的代码段
ENTRY ; 程序入口点
START ; 标号,表示程序开始
LDR R0, =SRC ; 将 SRC 的地址加载到 R0
LDR R1, =DST ; 将 DST 的地址加载到 R1
MOV R2, #10 ; 设置循环次数
LOOP
LDR R3, [R0], #4 ; 从 R0 地址加载数据到 R3,然后 R0 +=4
STR R3, [R1], #4 ; 将 R3 的值存入 R1 地址,然后 R1 +=4
SUBS R2, R2, #1 ; 循环计数器减 1,并更新条件标志
BNE LOOP ; 如果计数器不为零,跳回 LOOP
AREA COPYDATA, DATA, READWRITE ; 定义一个可读可写的数据段
SRC DCD 1,2,3,4,5,6,7,8,9,0 ; 定义源数组 SRC(10 个 32 位字)
DST DCD 0,0,0,0,0,0,0,0,0,0 ; 定义目标数组 DST(10 个 32 位字)跳转指令
ARM指令集提供了B、BL、BX、BLX等跳转指令
B {cond} label ;跳转到标号 label 处执行
B {cond} Rm ;寄存器Rm中保存的是跳转地址
BL {cond} label;
//跳转指令表示带链接跳转,跳转前,BL会先将当前指令的下一指令保存到LR寄存器
//带切换的跳转0:ARM状态,1:Thumb状态
BX {cond} label;
BLX {cond} label;注
LR寄存器是ARM架构一个专用寄存器,核心作用就是保存函数调用的返回地址。
ARM寻址方式
ARM是RISC体系架构,一个ARM汇编程序中大部分汇编指令都和数据传输相关
内存-寄存器
内存-内存
寄存器-寄存器
寻址方式:
- 寄存器寻址
MOV R1,R2;
ADD R1,R2,R3;- 立即寻址
ADD R1,R1,#1;//将 == R1 +=1;
MOV R1,#0XFF;//把后面的数写到前面的寄存器;里面- 寄存器偏移寻址
//是寄存器寻址的一种特殊情况,采用了operand2的操作数就行左移和右移的移位操作
MOV R2,R1,LSL,#3;//把R1左逻辑移三位的值拿到R2;
ADD R3,R2,R1, LSL #3;
//逻辑移位和算术移位的区别在于,逻辑移位始终填充0,算术移位始左移填充0,右移填充符号位。- 寄存器间接寻址
//简介寻址主要用来在内存和寄存器之间传输数据,寄存器保存的是数据在内存中的地址,通过地址在寄存器和内存之间传输数据==c的指针
LDR R1,[R2];
STR R1,[R2];- 基址寻址
//类似于寄存器间接寻址,二者不同不在,基址寻址将寄存器中的地址于与一个偏移量相加,生成一个新地址,然后基于新地址访问内存
LDR R1, [FP,#2] ;//将FP中的值加2作为新地址,然后把地址值保存到R1
LDR R1, [FP,#2]! ;//FP =FP+2;将FP指定的内存单元数据保存到R1中
LDR R1, [FP,R0] ;//将FP + R0作为新地址,取该地址上的值保存到R1
LDR R1, [FP,R0,LSL #2];//将FP + R0 <<2作为新地址
LDR R1 ,[FP],#2;//FP值作为地址,读取地址保存到R1,然后把FP的值加二
STR R1, [FP,# -2];//将FP中的值减2,作为新地址,将R1的值写到这个地址
STR R1,[FP],#-2;- 多寄存器寻址
STM/LDM就是多寄存器寻址
LDMIA SP! ,{R0-R2,R14};//从右到左依次弹出到对应栈
STMDB SP! ,{R0-R2,R14};//从左到右依次入栈
LDMFD SP! ,{R0-R2,R14};//也是右到左弹出
STMFD SP! ,{R0-R2,R14};//左到右压入
//{}这个叫寄存器列表,如果是连续的可以直接用-链接,
IA: increase after
IB: increae before
DA: Decrease After
DB: Decrease before栈是C语言运行基础,函数内的局部变量、函数调用过程中要传递的参数、函数的返回值一般都是保存在栈中的。
一般来说有四种栈:A:递增栈、D:递减栈、F:满栈、E:空栈
- 相对寻址
//相对寻址其实也是基址寻址,以PC指针作为基址寻址,以指令中的地址差作为偏移,二者结合可以得到一个新的地址,然后可以对这个地址进行读写操作。像很多与位置无关的代码,比如动态库,汇编层次的实现就是采用的相对寻址,通过记录从当前执行的指令地址到想要去的指令地址之间的偏移就可以计算。
ARM伪指令
常见的伪指令一般有ADR\ADRL\LDR\NOP
伪指令就是各厂商为了方便定义的一些辅助指令
ADR R0 ,LOOP ;//将标号LOOP的地址保存到R0里面
ADRL R0,LOOP ;//中等范围的地址读取
LDR R0,=0X3008000 ; //将内存地址 0想0080000赋值给R0
NOP ;//空操作,用于延时或插入流水线中暂停指令的执行 VLIW:超长指令集架构LDR伪指令
ARM属于RISC架构(简单指令集),不能对内存数据直接操作
需要LDR/STR或者STM-LDM
区分LDR伪指令和加载指令LDR:
LDR伪指令的主要作用是将一个32位的内存地址保存到寄存器里面
MOV不能处理处理一个内存地址是32的立即数,因为系统32位的,处理指令本身一般32位里还要包含操作码和操作数等等。
LDR R0, =0X3008000此处的LDR不是加载指令而是伪指令,伪指令的操作数前面一般有一个=,伪指令可以处理32位立即数无法编码的问题。
当操作数小于八位的时候就等价于MOV ,大于8位的时候伪指令会被编译器转换位LDR标准指令+文字池的形式。_采用类似于相对寻址的方式来找到这个定义的32位立即_数
ADR伪指令
ADR其实功能类似于LDR将基于PC相对偏移的地址读取到寄存器里面,也是基于相对寻址。
识别到ADR,计算出正在执行的ADR指令地址于标号LOOP之间的地址偏移OFFEST,然后使用ARM中一个标准指令集替换。
与LDR伪指令的区别在于LAR常常翻译为LDR或者MOV,而ADR伪指令通常被ADD或者SUB代替。用途上LDR主要用来操作外部设备的寄存器、而ADR指令主要通过相对寻址,生成位置无关的代码,寻址方式上LDR使用绝对地址,ADR使用相对地址,LDR使用地址范围(0,32GB),ADR则要去必须在同一个段里面,地址偏移范围也比较小,地址对齐时偏移范围是(0,1020),没有对齐就是(0,4096)。
汇编程序设计
编程格式
ARM汇编以段(section)进行组织,汇编文件分为多个段像代码段、数据段,等等。
AREA COPY ,CODE ,READONLY ;
ENTRY
START
LDR R0,=SRC;
LDR R1,=DST;
MOV R2,#10;
LOOP
LDR R3,[R0],#4;
STR R3,[R1],#4;
SUBS R2,R2,#1
BNE LOOP
AREA COPYDATA ,DATA,READWRITE;
SRC DCD 1,2,3,4,5,6,7,8,9,0
DST DCD 0,0,0,0,0,0,0,0,0,0
END这个汇编是数据块复制,先初始化了寄存器,两个用于地址,一个用于计算循环次数。
ARM汇编一般从ENTRY这个伪操作标识入口,ARM里面使用分号来注释代码
符号和标号
符号可以标示一个地址、变量或数字常量,当符号标示地址的时候,符号又可以叫做标号。
符号命名与C类似但是标号要宽松一些。
符号在作用域的命名必须唯一,而且不能和系统预定义的符号、指令助记符、伪指令同名。
一般符号的作用域就是整个汇编源文件,有时直接通过数字【0,99】进行地址引用,这种数字叫做局部标号,局部标号的作用域是当前段。
%{F|B|A|T} N{routename}
%:引用符号,对一个局部标号产生引用
F:指示编译器只向前搜索
B:指示编译器只向后搜索
A:指示编译器搜索宏的所有宏命令层
T:指示编译器搜索宏的当前层
N:局部标号的名字
routename:局部标号的作用范围名称
不指明B和F,编译器默认先向后搜索再向前搜索,A和T没有指定,汇编程序默认搜索从当前层到最顶层的所有宏命令,但是低层不搜索。routename指定之后,汇编将它和前一个ROUTE指令名称进行比较,不匹配就汇编失败。
伪操作
位操作用来指示块、程序入口等等
GBLA a ;定义一全局算术变量a,并初始化为0
a SETA 10 ; 给a赋值10
GBLL b ;顶一个一个全局逻辑变量并初始化为false
b SETL 20 ;给逻辑变量赋值20
GBLS STR ;定义一个全局字符变量STR
STR SETS "****";给STR赋值 ***
LCLA a ;定义一个局部算术变量a,并初始化为0
LCLL b ;定义一个局部逻辑变量b,并初始化为flase
LCLS name ;
name SETS "888";
//数据定义一般有如下一些操作
DATA1 DCB 10,20,30,40 ;//分配一片连续字节存储单元并初始化
STR DCB "8888";//给字符串分配一片连续的存储单元并初始化
DATA2 DCD 10,20,30,40;//分配一片连续的字节存储单元并初始化
BUF SPACE 100;//给BUF分配100字节,并初始化为0

C和汇编的混合编程
ATPCS规则
核心定义ARM子程序调用的基本规则以及堆栈的使用约定。
重要
- 子程序要通过寄存器R0~R3(可以记作a0 ~ a1)传递参数,参数个数大于4的时候,剩余参数使用堆栈传递。
- 子程序使用R0~R1返回结果
- 使用R4-R11(v1-v8)来保存局部变量
- R12作为调用的临时寄存器,保存函数的栈帧基址(FP)
- R13叫做堆栈指针寄存器,SP
- R14作为链接寄存器,用来保存函数调用者的返回地址,记作LR
- R15作为程序计数器,总是指向当前正在运行的指令,叫做PC
内嵌汇编

不同的编译器提供的执行汇编的关键字不一样。
GNU ARM
编译器就像前面说过是一套工具集:编译器、汇编器、连接器、二进制转换、库打包工具、调试工具。
GNU ARM的伪操作
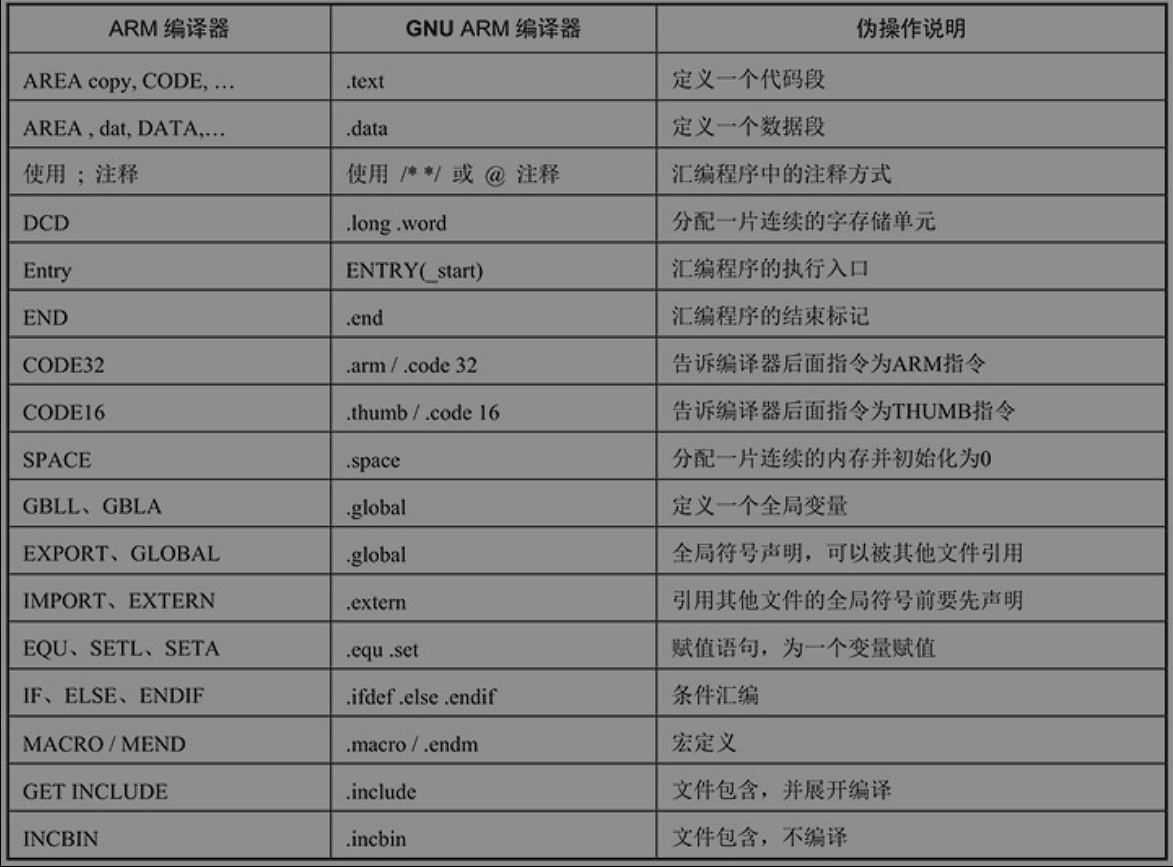
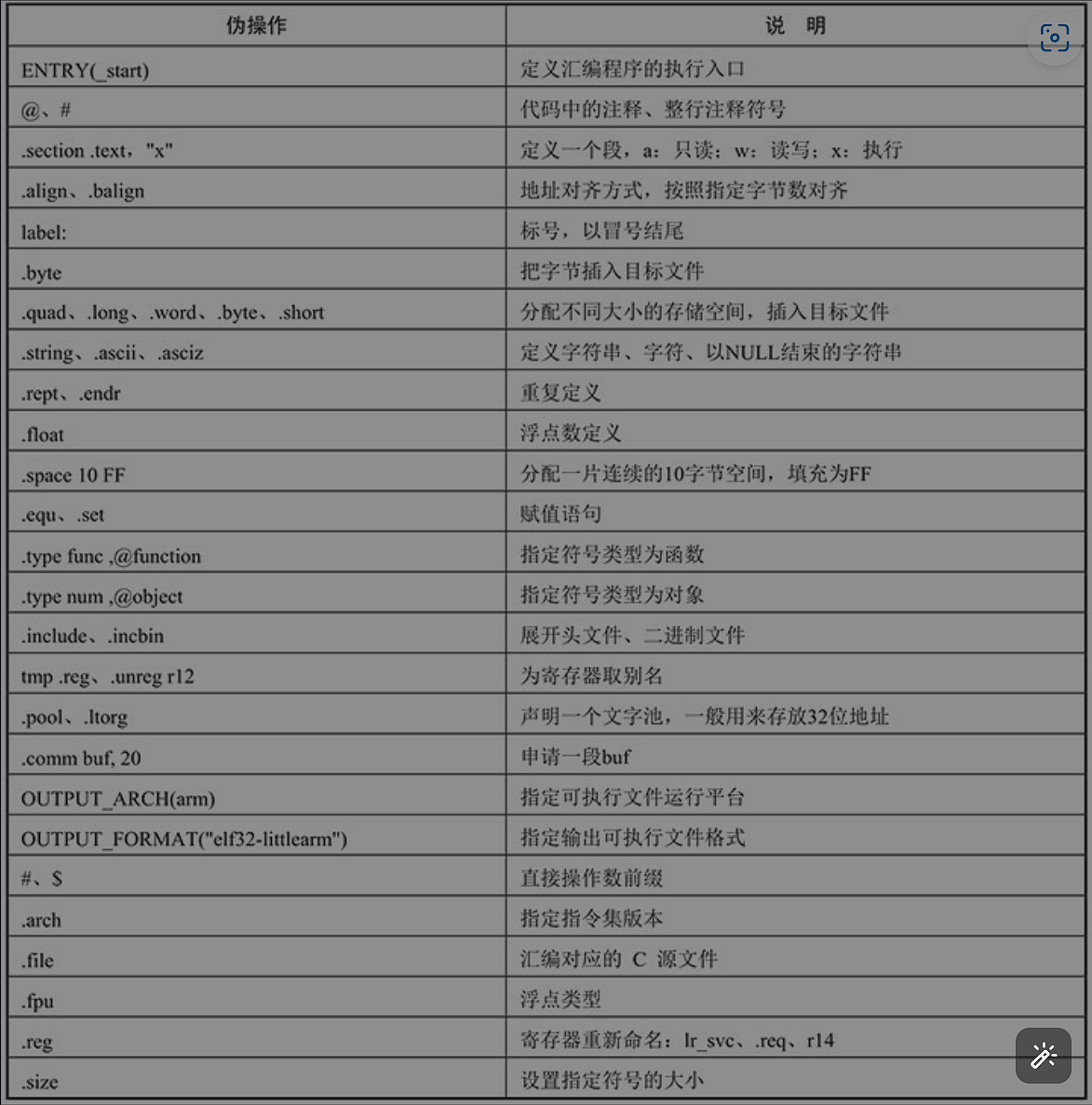
GNU ARM汇编中的标识符:字母、数字、下划线、和.构成局部标号可以是纯数字,在引用标号的时候写成N+(f or b)代表搜索方向
.section 自定义段
.section <section name> {,'<flags>'}
//要注意不能冲突可以用readelf来查看系统预留的段名基本数据格式:
二进制数据通常以0B或0b开头,八进制数据以0开头,十六进制数据以0x开头,十进制数据则以非0数字开头。负数前面加“-”,取补用“~”,不相等用“<>”,其他运算符号如+、-、*、%、<、<<、>、>>、|、&、^、!、==、>=、&&与C语言语法相似。
字符串常量要用双引号""括起来。使用.ascii定义字符串时要自行在结尾加'\0',.string伪操作可以定义多个字符串,使用.asciz伪操作可以定义一个以NULL字符结尾的字符串,使用.rept伪操作可以重复定义数据。
数据定义:
示例:
标签:命令
f:
.float 3.14
.equ f,3.1415 @重新赋值.equ除了给数据赋值意外,还可以把常量定义在代码段
.section .data
.equ DELAY,100
.section .text
MOV R0,$DELAY程序的编译、链接、安装和执行
readelf -h :查看可执行文件的头部信息
readelf -S:查看可执行文件节头表
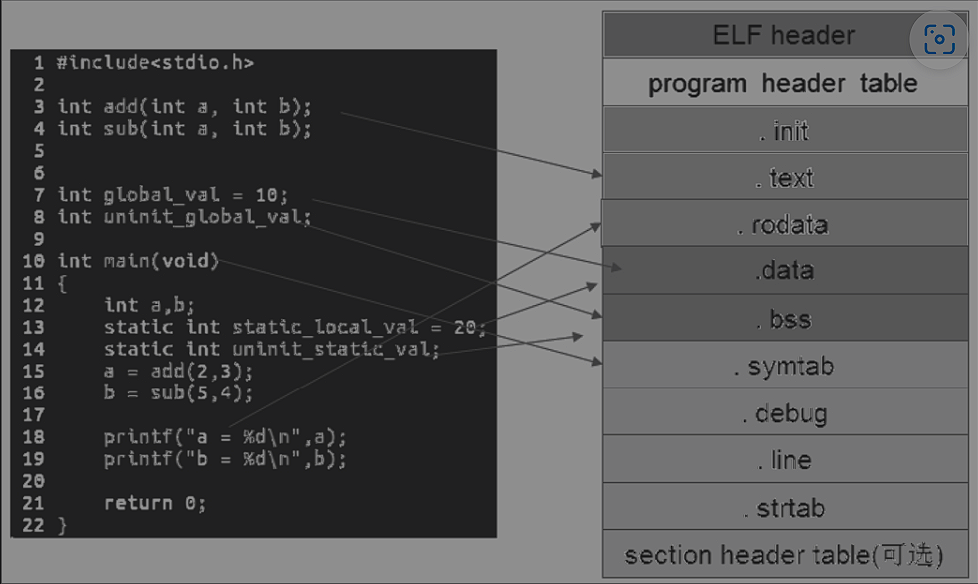
通过节头表,可以探究可执行文件的基本构成:一个可执行文件可以由一系列的section组成,section header table里的各个section header用来描述各个section的名称、类型、起始地址、大小等信息。除此之外,可执行文件还会有一个文件头ELF header,用来描述文件类型、要运行的处理器平台、入口地址等信息。
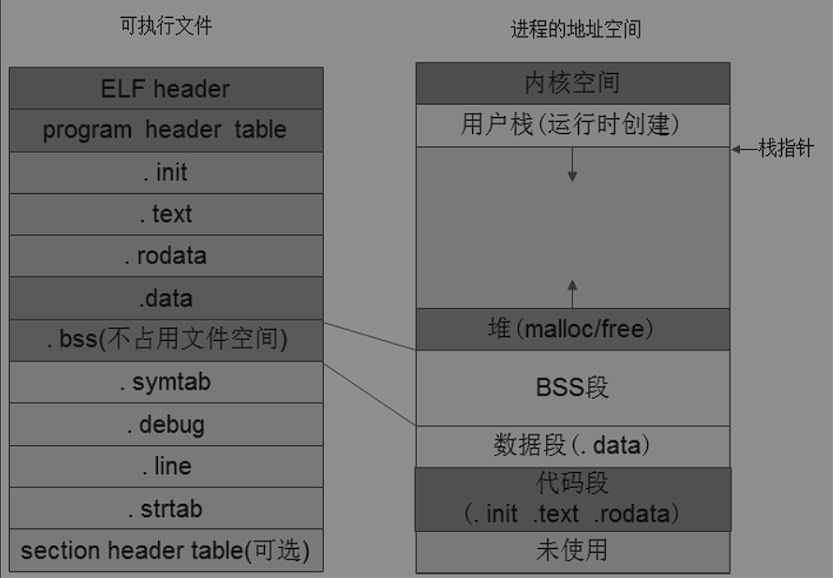
.text,.data,.bss等等段,函数放在代码段、初始化的全局变量和静态局部变量放在数据段,而BSS段,一般来讲没有经过初始化的全局变量和静态变量放在BSS段里面,但是因为没有初始化,默认值全是0,没有必要单独开辟空间,为了节省存储空间,所以在可执行文件中BSS段是不占用空间的,但是BSS段的大小、起始地址、各变量的地址信息分别保存在section header table和符号表.symtab里面,当程序运行时,加载器会根据这些消息在内存中紧挨着数据段的为BSS段开辟一片存储空间。程序中定义的一些字符串、printf函数打印的字符串常量放置在只读数据段.rodata中,如果程序在编译狮设置为debug模式,则有一个专门的.debug section,用来保存执行文件每一个二进制指令对应的源码位置信息。
预处理
头文件包含:#include
定义一个宏:#define
条件编译:#if、#else、#endif
编译控制:#pragma
注
#pragma pack([n]):指定对齐方式
#pragma message(“string”):在编译信息窗口打印string
#pragma warning:有选择修改编译器警告信息行为
#pargma once:防止多次包含的方言
预处理:头文件展开、宏展开、条件编译、删除注释、添加行号和文件名标示、保留#pragma命令
编译
通过有限状态机解析并识别这些字符流,将源程序分解为一系列不能再分解的记号单元:token,语法分析主要是对前一阶段产生的token序列进行解析,看是否能构建成一个语法上正确的语法短语。语法短语用语法树表示,是一个树型结构,不再是线性序列。
语法分析-语法分析-语义-中间代码生成-汇编代码生成-目标代码生成。
语法分析阶段输出的表达式或程序语句,以语法树的形式存储,中间代码是编译过程的一种临时代码,常见的有三地址、P-代码。
中间代码与语法树相比,有很多优点:中间代码是一维度线性序列结构、类型伪代码,编译器很容易将中间代码翻译成目标代码。
汇编过程
.o文件文件属于可重定位的目标文件,它们要经过链接器重定位、链接。
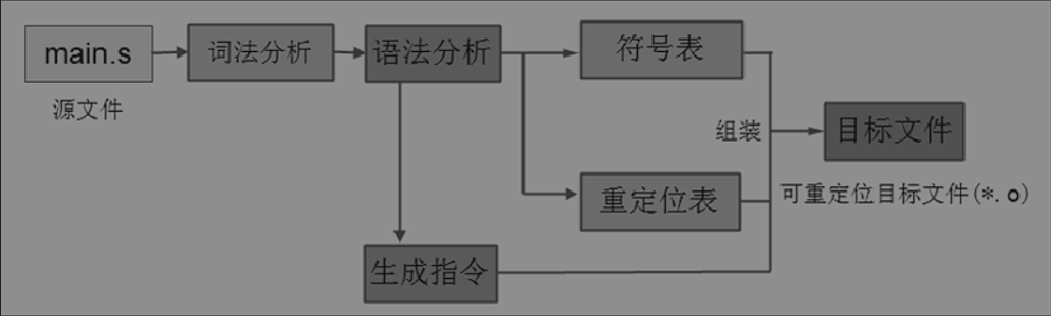
连接器将各个目标文件组装到一起后,需要重新修改各个目标文件中的变量或函数的地址,这个一般称为重定位。把这些收集起来生成重定位表。
除此之外,一个文件中的所有符号,无论是函数名和变量名,无论其是否重定位,也会收集起来生成符号表,以section的形式添加到每个可重定位目标文件中。
符号表与重定位表
在汇编阶段,汇编器会分析汇编语言中各个section的信息,收集各种符号,生成符号表。
(readelf -s * .o )查看目标文件符号表信息
整个编译过程中,符号表主要用来保存源程序中各种符号的信息,包括符号的地址、类型、占用空间的大小。
符号表里每一个符号都有符号值和类型。符号值本质是一个地址,可以是绝对地址,一般出现在可执行文件中;也可以是一个相对地址,一般出现在可重定位目标文件中。
符号类型主要有:
- OBJECT
- FUNC
- FILE
- SECTION:用于重定位
- COMMON:表明是一个公用块数据对象,是一个弱符号
- TLS:表明该符号对应的变量存储在线程局部存储中
- NOTYPE:未指定类型或者不知道类型
在包含其他文件的时候如果有直接找不到不会在编译阶段报错而是在链接阶段报错,如果在收集的过程中没有找到符号的定义那么就会收集起来保存到一个单独的符号表里面,这个符号表就是重定位符号表.rel.text
链接过程
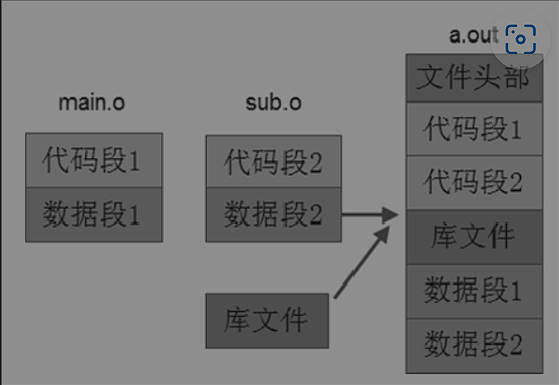
在一个c项目的编译中,编译器以C源文件为单位,将c翻译成对应的目标文件。生成的每一个目标文件都是由代码段、数据段、BSS段、符号表等section组成的,这些section从目标文件的零偏移地址开始按照顺序依次排放,每个段的符号相对于零地址的偏移就是每个符号的地址,这样就为程序定义的变量和函数名给予了暂时的地址。
在后续的链接过程中,这些目标文件中的各个section会重新拆分组装,每个section的起始参考地址都会发生变化。
分段组装
链接器将编译器生成的各个可重定位目标文件重新分解组装:将各个目标文件的代码段放在一起,作为最终生成的可执行文件的代码段;将各个目标文件的数据段放到一起,最为最终可执行文件的数据段。其他模仿这个过程。
符号表:链接器会在可执行文件中创建一个全局的符号表,收集各个目标文件符号表的符号,通过这步,一个可执行中的所有符号都有了自己的地址,并保存在全局符号表里面,此时还是临时地址。
通过链接脚本指定各个段的组装顺序、起始地址、位置对齐等等,同时对输出的可执行文件规格、运行平台、入口地址等信息做了详细的描述。链接器是根据链接甲苯定义的规则来组装可执行文件,并最终将这些信息以section形式可保存到可执行文件的ELF Header里面。
arm-linux-gnueabi-ld –verbose
不同编译器默认的链接地址也是不一样的,在一个由带有MMU的cpu搭建的嵌入式系统中,程序的链接起始地址往往都是一个虚拟地址,程序运行过程中还需要地址转换,通过MMU将虚拟地址转换为物理地址,才能访问内存。
符号决议
面对一些变量名冲突的情况:
强符号和弱符号:函数名、初始化的全局变量是强符号,未初始化的就是弱符号
强符号不可以多次定义,强弱可以在一个项目中共存,共存的时候强符号直接覆盖掉弱符号,链接器选择强符号作为可执行文件中的最终符号
编译器允许一个项目中出现多个弱符号共存,在编译期间,未初始化的全局变量并没有被直接放在BSS段,而是将这些弱符号放到叫做COMMON的临时块里面,在符号表里面使用一个未定义的COMMON来标记,链接期间,链接器会比较多个文件中的弱符号,选择占用空间最大的那个作为可执行文件的最终服符号,这个时候符号大小确定,被直接放到BSS段里面
如果项目由需求可以把一些强符号转换为弱符号GNU C的_ attribute _
除了强弱符号还有强弱引用的概念,通过符号去调用函数或者访问一个变量通常称作引用,强符号对应强引用,弱符号对应弱引用。
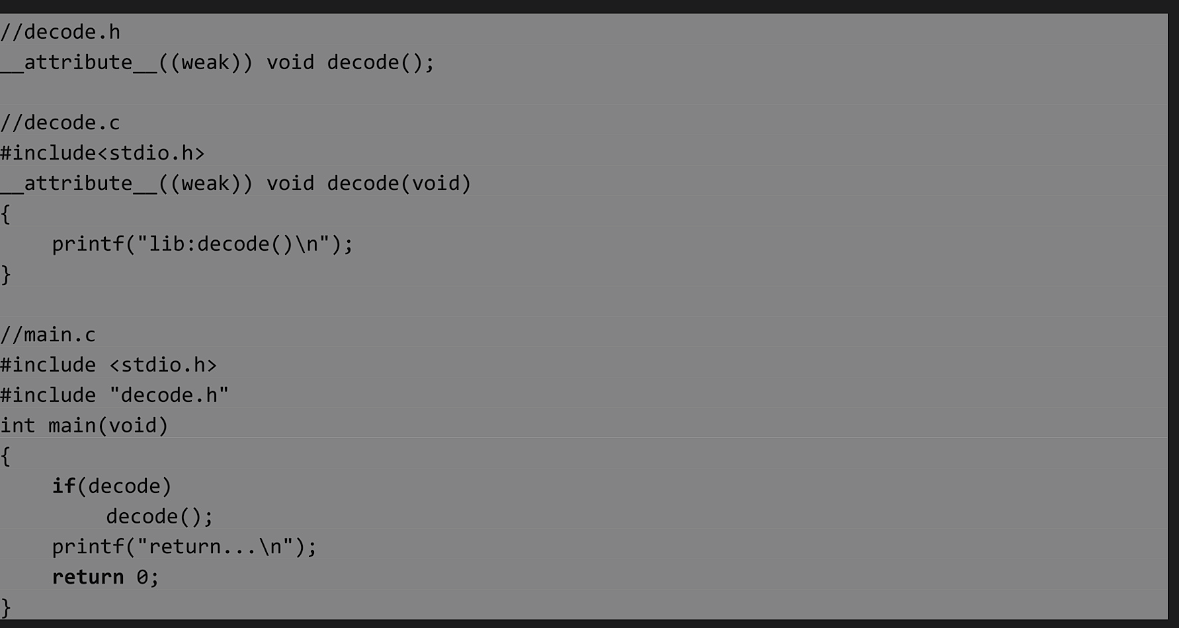
如果是强引用,在链接的时候如果找不到定义那么就会报未定义错误,如果一个符号的引用是弱引用,链接时候找不到定义链接器不会报错而且不会影响最终可执行文件的生成,只有在运行时候没有找到对该符号的定义才会报错。
利用链接器对弱引用的处理规则,我们在引用一个符号之前可以先判断该符号是否存在,这样当引用没有定义符号的时候,在链接阶段不会报错,在运行阶段通过判断运行也可以避免运行错误。适合于版本新发布有一些还没有完成的接口,设置成弱引用,并且在运行之前进行判断这样的话就可以不影响程序的正常运行。
重定位
符号决议解决了多文件符号冲突的问题,现在需要把符号表中的变量地址由原来的目标文件地址,重新组装也就是重定位问题,原来各个函数相对于零地址偏移就是各函数的入口,现在要重构这些。
一般会基于某个链接地址Link_addr进行链接,接下来修改可执行文件的全局符号表
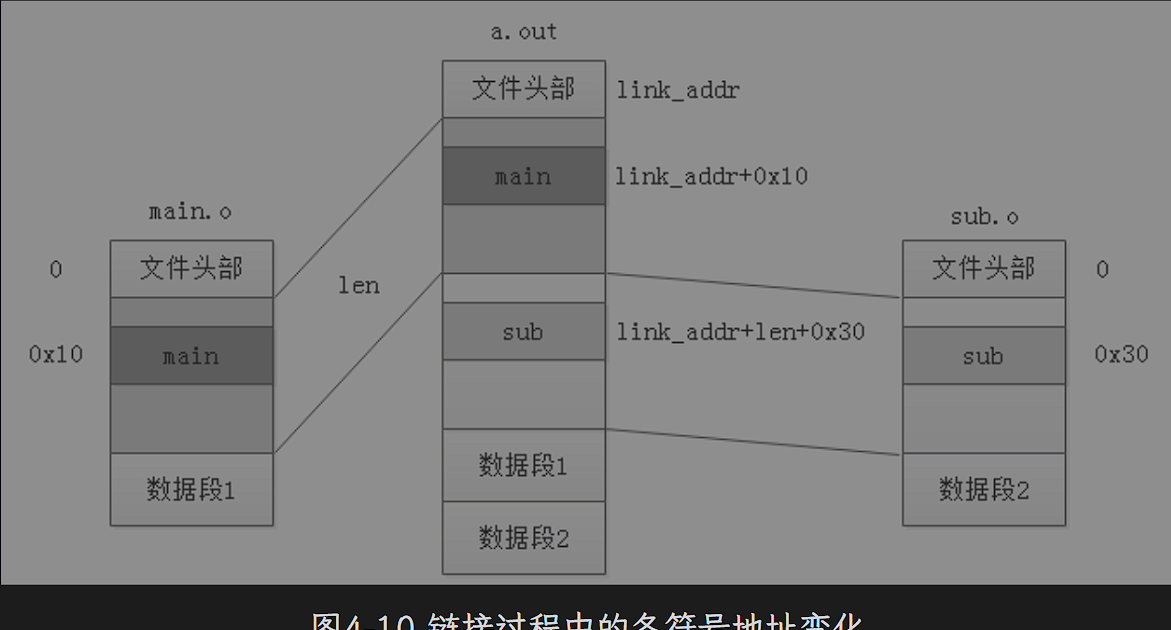
链接阶段,会收集未定义符号形成重定位表。无论代码段还是数据段,都会有一个重定位表与之对应,如果需要重定位的话。
realelf objdump
程序安装
程序运行其实就是处理器根据PC寄存器的地址,从内存里面取指、翻译指令、执行指令的过程。软件安装的过程其实是将一个可执行文件安装到ROM,安装安装宝就是将包中的可执行文件解压出来然后将可执行文件和动态共享库复制到安装目录,并且配置环境变量当运行软件的时候系统就会从目录下找到这个可执行文件。
dpkg制作安装包,可是参考4.5.2节。
选择一个镜像源添加到/etc/apt/source.list文件,如果是国内源就可以从国内镜像进行下载了。
windows下面的安装程序通过创建自解压压缩格式来创建程序
程序运行
注
程序运行由两种: 一种是在有系统下运行:ELF—》会包含各种段、文件头、符号表啥的辅助程序运行 一种是在无系统下运行:HEZX/BIN–》纯指令文件
可执行文件在被加载器加载的时候,程序的各种section会加载到内存中的不同位置,可执行程序的文件头会包含一些关键信息,如果加载器读完头发现有些不匹配的现象就会报错。
可执行文件中有一个program header table 记录如何将文件加载到内存的相关信息,包括了可执行文件要加载的内存的段和入口地址等,这个section在目标文件可以没有但是在一个可执行文件这个section是必须的。 readelf -l 可以读
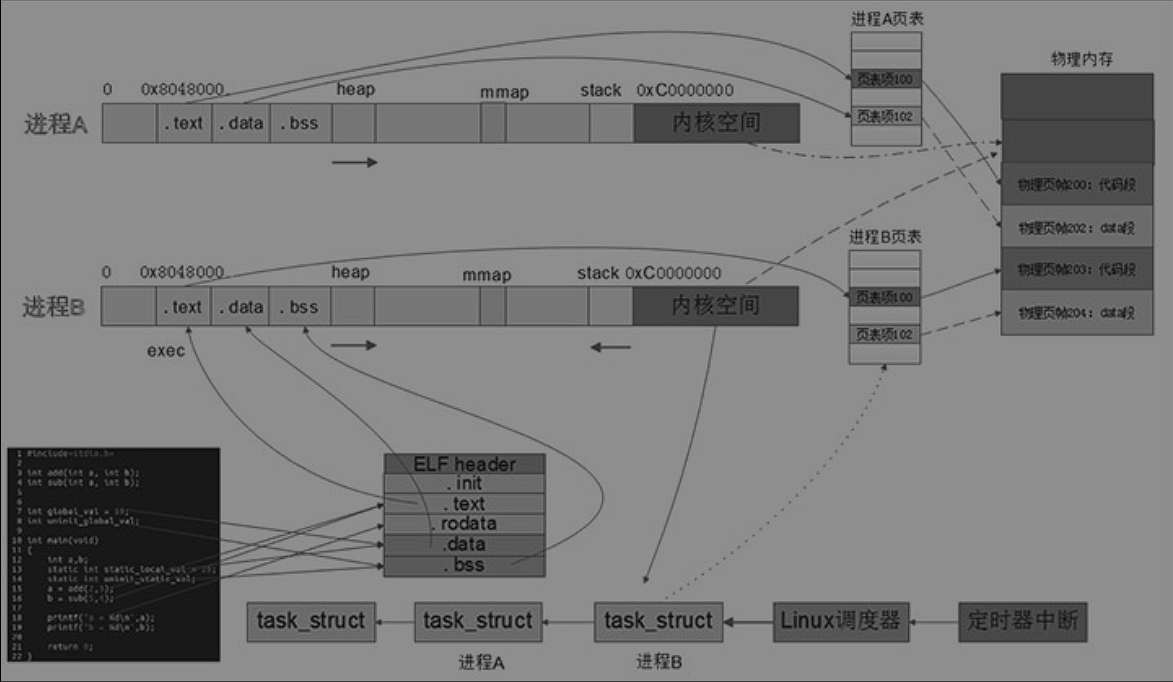
大致过程是在shell执行运行之后会创建一个子进程并且调用execve()加载要运行的程序,通过文件头找到映射关系和程序入口,将PC指针设置到程序入口。
每个进程拥有自己的页表,页表里面每一个条目叫做页表项,页表项里面存储的是虚拟地址和物理地址的映射,相同的虚拟地址经过MMU转换后,会分别映射到物理地址的不同区域。
每个运行的程序Linux内核会用一个task_struct结构体表示,多个结构体通过指针构成链表。操作系统基于这个链表进行管理。
在裸机环境下很多集成开发环境ADS1.2,Keil等可以提供编辑、编译、运行、调试、烧写等等。
U-Boot在linux启动过程中充当加载器,U-boot存储在NAND/NOR Flash上,在启动的过程中不仅要完成自复制:将自身代码从存储分区复制到内存里面,还要完成自身代码的重定位,一般具有这种功能的代码称作“自举”。
其实在main()之前,会做一些准备工作必须初始化堆栈指针等(通过汇编),这段初始化的代码是在程序编译阶段的时候由编译器自动添加到可执行文件中的。
注
不同编译器C标准库约定的入口有所区别,WIN32 窗口的入口函数是WinMain;Visual Studio 和VC++6.0约定入口_tmain,其余一般是main
可以自定义入口,通过加入编译参数 -nostartfiles 表示不连接art1.o 文件
-nostartfiles -e <入口函数> ,这样之后不能再使用return 形式返回因为没有链接初始化代码,可以使用exit()
BSS段不占用可执行文件存储空间,但是当程序加载到内存运行的时候,加载器会在内存给BSS开辟一段空间,section header table 会记录BSS段大小,在符号表会记录每个变量的地址和大小。加载器根据这表里面信息,在数据段后面分配指定大小的空间并清零,根据符号表里面变量的地址,在内存中给各个未初始化的全局变量、静态变量分配存储空间
静态库
编译的时候静态库就已经链接,动态库在编译阶段不参与链接,不会和可执行文件组装在一起,而是在程序运行时候才会被加载到内存。
注
gcc -c test.c
ar rsc libtest.a test.o
gcc main.c -L. -ltest
#注意要在main.c里面声明函数形式
# -L 后面跟要链接的路径
# -l 后面跟去掉前后缀后的库名
#-c:禁止在创建库时产生的正常消息。
# -r:如果指定的文件已经在库中存在,则替换它。
# -s:无论库是否更新都强制重新生成新的符号表。
# -d:从库中删除指定的文件。
# -o:对压缩文档成员进行排序。
# -q:向库中追加指定文件。
# -t:打印库中的目标文件。
#-x:解压库中的目标文件。静态库不好的地方就是会把整个库都链接进去,可以通过readelf -s 查看
解决方案那就是源文件分别产生.o再一起编成静态库这样的话就不不会整个库都链接了。
但是静态库还有一个问题,多个程序调用每个程序都会添加一份printf指令,会出现很多重复的指令代码
动态库
在程序运行阶段才参与链接。程序运行的时候,这些动态链接库会跟着一起加载到内存,参与链接和重定位。
动态链接的好处是节省资源、升级方便。Linux环境下,运行一个程序的时候,会先fork一个子进程,随着动态链接库被动态链接器加载到内存,操作系统交出控制权,让链接器完成动态库的加载和重定位操作,动态链接器是C标准库的实现,是glibc的一部分,在可执行文件的.interp段中存放由其加载路径.objdump -j .interp -s a.out可以查看.
采用与地址无关的代码的方式让不同的进程可以访问同一个动态库而不用多次加载。
将指令中加入动态库需要修改的部分分离出来,让剩余部分与地址无关。
gcc -fPIC #编译与位置无关代码 #不同的编译器实现方式有所区别,在模块内部避免采用绝对地址,一般采用行对地址替代。 #比如ARM有一种以PC寄存器作为基址,以当前指令和目标地址的差作为偏移量
全局偏移表
当动态库作为第三方模块被不同程序引用时候,库里一些绝对地址符号,将被调用多次需要重定位。做到同时被不同的程序进行引用的方式就是采用全局偏移表。
这个表将每个程序引用的动态库(绝对地址符号)收集起来,程序运行时候通过查询表里面的符号。(GOT)
GOT表以section的形式保存在可执行文件,这个表的地址在编译阶段确定,当程序运行需要加载动态库里的函数,会将动态库加载到内存,根据动态库加载到内存的地址,更新GOT的符号地址,采用这样的方式可以不同程序运行的时候修改自己的GOT表,他们都可以指向同一个被加载内存的动态库。
延迟绑定
采用相对寻址的方式效率相对较低,对程序运行时间有一定的影响。可执行文件有考虑这个问题就是延迟绑定:程序运行的时候不会一次性加载所有的动态库,当函数第一次被调用的时候就会去加载动态库。
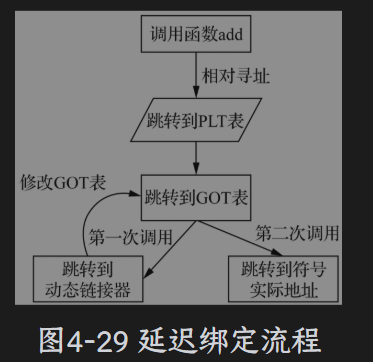
指令代码中每一个动态链接的符号<x@plt>都被保存在过程连接表(PLT表)。过程表本质是一个数组,每个再程序中被引用的动态链接库函数,都在数组里面对应一项,PLT有两个特殊项PLT[0]会关联动态链接器的入口,PLT[1]关联到初始化函数_libc _start _mian(),这个函数初始化C语言运行的基本环境。
共享库
当程序运行时,动态链接器首先被加载到内存运行,动态链接器会分析可执行文件,从可执行文件的.dynamic段中查询该程序运行需要依赖的动态共享库,然后到库的默认路径下查找这些共享库,加载到内存中并进行动态链接,链接成功后将CPU的控制权交给可执行程序,我们的程序就可以正常运行了。
动态链接器在查找共享库的过程中,除了到系统默认的路径(/lib、/usr/lib)下查找,也会到用户指定的一些路径下去查找,用户可以在/etc/ld.so.conf文件中添加自己的共享库路径。
插件
插件的本质是共享动态库。
//加载动态链接库
void* dlopen(const cahr *filename, int flag);
void *Handle = dlopen("./libtest.so",RTLD_LAZY);
//这个函数返回void* 的操作句柄,第一个参数就是动态库,第二个是打开标志位
//RTLD_LAZY:解析动态库遇未定义不退出仍然继续使用
//RTLD_NOW:遇到未定义直接退出
//RTLD_GLOBAL:允许到处符号,在后面其他动态库中可以引用void *dlsym(void *handle, char *symbol);
void (*funcp)(int , int);
funcp = (void(*)(int, int)) dlysm(Handle , "myfunc");
//dlsym()函数根据动态链接库句柄和要引用的符号,返回符号对应的地址然后利用对应类型的指针去转换就可以使用到这个动态库里的函数了。int dlclose (void *Handle);
//该函数会将加载到内存的共享库的引用计数减一,记数归零,动态库就会被卸载。const char *dlerror(void);
//动态库操作函数失败时,derror将返回出错信息,如果没有出错返回NULLLinux内核模块运行机制
Linux内核实现了模块化的动态加载和运行。直接使用insmod命令就可以加载模块。
U-BOOT提供了bootm机制启动内核的运行,Bootm会解析uimage文件里面64字节的数据头,解析出指定的加载地址,在和自己的启动参数进行对比。参数相同,跳过数据头,直接到zimage入口执行,不同就会把去掉字节头的内核镜像zimage复制到编译时候指定的加载地址,然后到该地址执行。
zimage是一个压缩文件,在运行之前需要解压,将其重定位到指定的链接地址上,Linux内核运行使用的虚拟地址,需要CPU硬件管理关于MMU的支持,MMU可以将虚拟地址映射到物理地址上,zimage的解压缩代码就会被拷贝到实际物理内存处,然后跳转过去启动。
使用U-boot引导Linux内核启动,不仅充当加载器引导运行还充当了链接器角色。
ARMSoC会在芯片内部集成一块ROM,ROM会固化一段启动代码,系统上电后,会首先运行ROM里面的代码,这部分代码的主要工作就是初始化存储接口、建立存储映射,它根据CPU外部脚管或eFuse判断系统的启动方式。一个系统有NOR Flash 、NAND Flash或者从SD卡启动。根据选择的启动类型就会声明映射到零地址,然后系统复位,CPU调转U-boot中断向量表中的第一行代码。
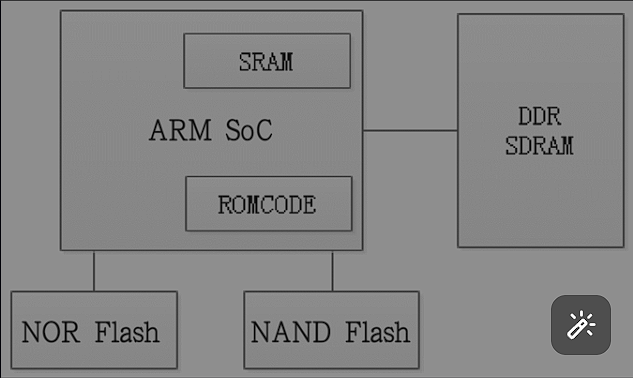
因为NAND Flash或SD启动其不支持直接运行有一个load\store的过程。
U-boot的启动流程
重要
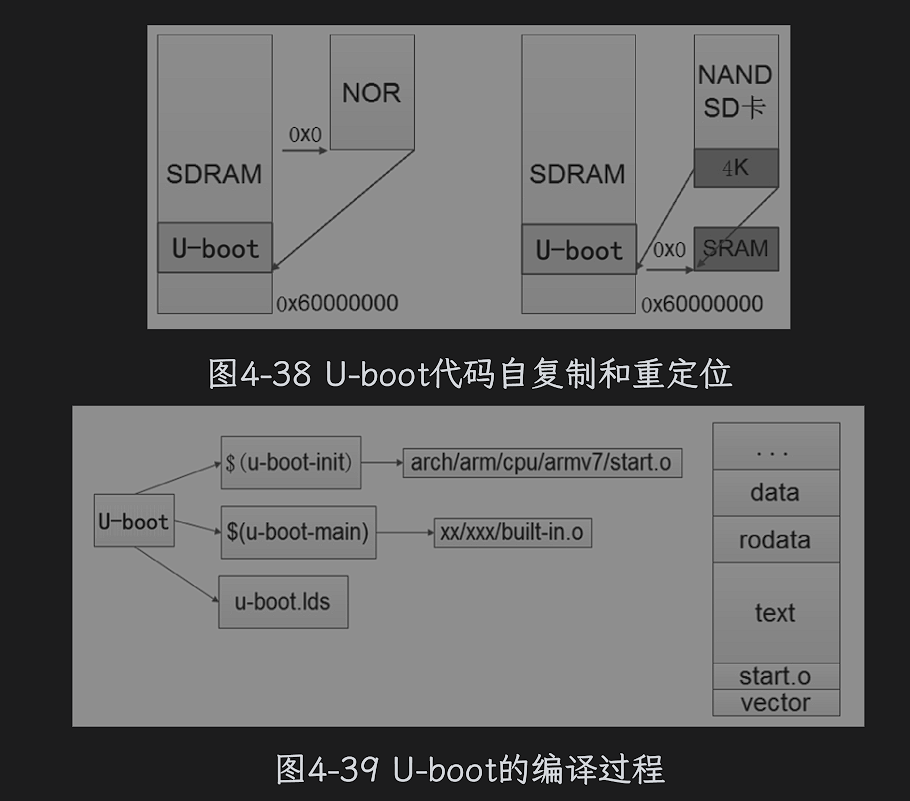
U-boot上电后会依次涉及以下几个文件
- arch/arm/lib/vector.S:b reset –>reset
- arch/arm/cpu/armv7/start.S:reset–>_main
- arch/arm/lib/crt0.S:main—>relocate_code
- arch/arm/lib/relocate.S:relocate_code
系统上电复位,ARM首先会跳到中断向量表执行复位程序,rest复位程序在start.S汇编文件里面,pc指针跳转到start.S文件执行程序。
- 设置CPU未SVC模式
- 关闭Cache ,关闭MMU
- 设置开门狗、频闭中断、设置时钟、初始化SDRAM
reset程序会调用不同的子程序完成初始化。rest最后会跳到crt0.S中的_main汇编子程序执行。
- 初始化C语言运行环境、堆栈设置
- 各种板级设备初始化、初始化NAND Flash、SDRAM
- 初始化全局结构体变量GD,在GD里有U-boot实际加载地址
- 调用relocate_code,将U-boot镜像从Flash复制到RAM
- 从Flash跳到内存RAM中继续执行程序
- BSS段清零,跳入bootcmd或main_loop交互模式
启动过程中最关键,最难理解的是调用relocate_code实现代码的复制与重定位操作。
relocate_code在relocate.S汇编文件中定义,它会将U-boot自身的代码段、数据段从Flash复制到RAM,然后根据重定向符号表,对内存进行重定位。
旧版本的U-boot一般链接地址等于加载地址,新版本的U-boot则采取不同的操作:无论编译时的链接地址是多少,U-boot可以根据硬件平台实际RAM的大小灵活设置加载地址,并保存在全局数据gd->relocaddr中。
U-boot分别使用两个零长度数组_ image_ copy start 和 _image_copy_end 来标记U-boot要复制到内存中的指令,复制前要判断链接地址 _image_copy_start和保存在R0的实际加载地址gd->relocaddr是否相等,如果相等就跳过复制。
复制之后还需要进行重定位,才能跳转到ARM运行。旧版会在重定位前判断,运行地址是否等于链接地址,如果相同或者直接从SDRAM启动,就不需要重定位,但是新版的无论采用那种都需要进行重定位。
U-boot重定位操作和动态链接库类似,采用与地址无关代码+符号表的形式实现重定位。
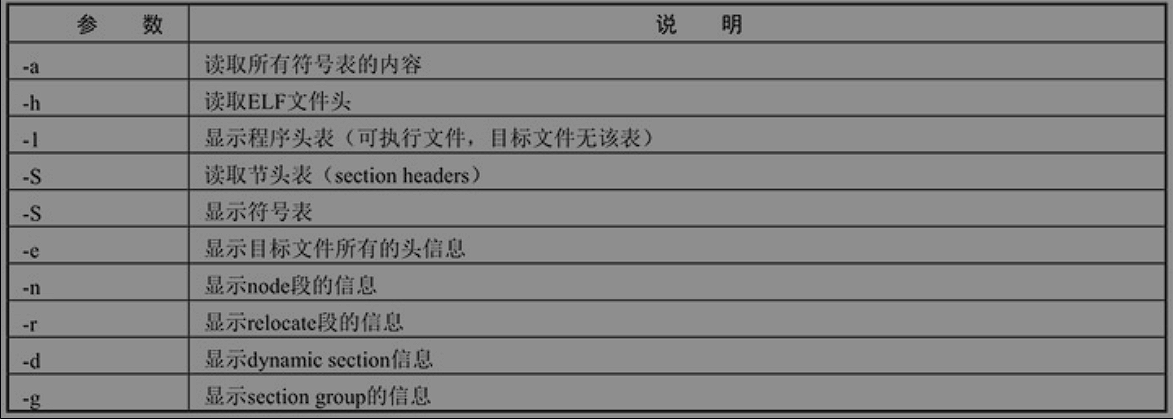
常用的binutils工具集

readelf
主要查看二级制文件的section信息。
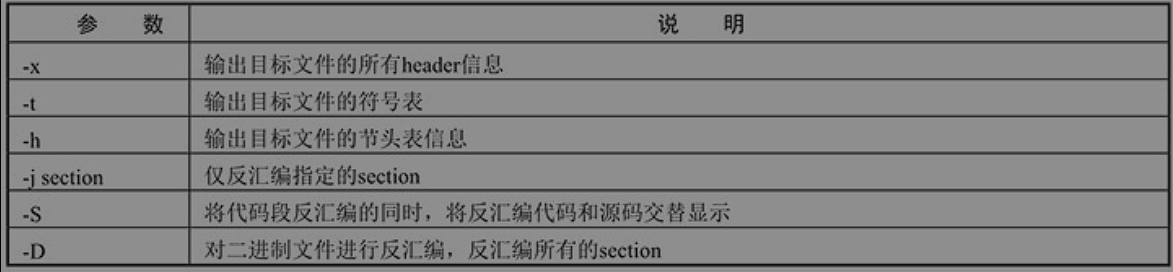
objdump
主要用于反汇编。

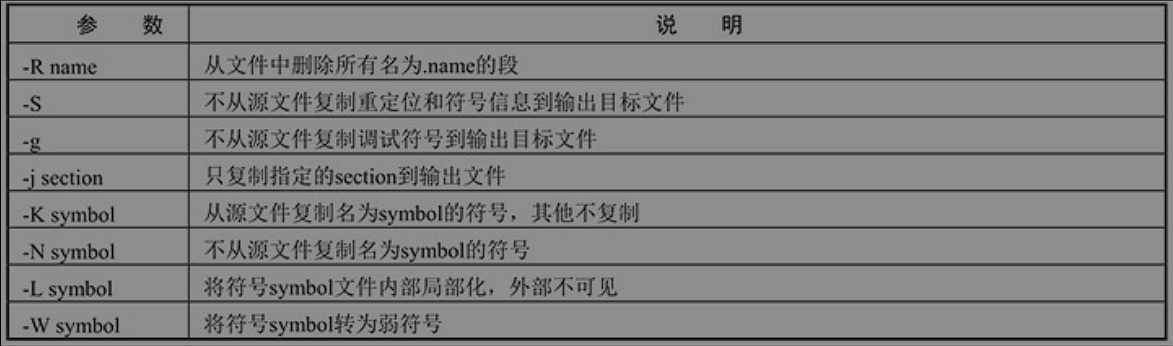
objcopy
主要用来将一个文件内容复制到另一个目标,对目标文件实现格式转换。
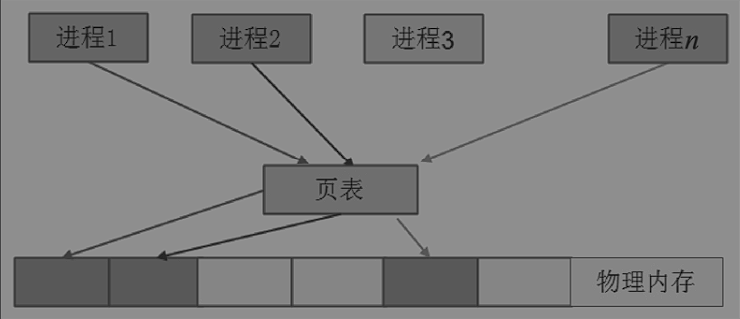
内存堆栈管理
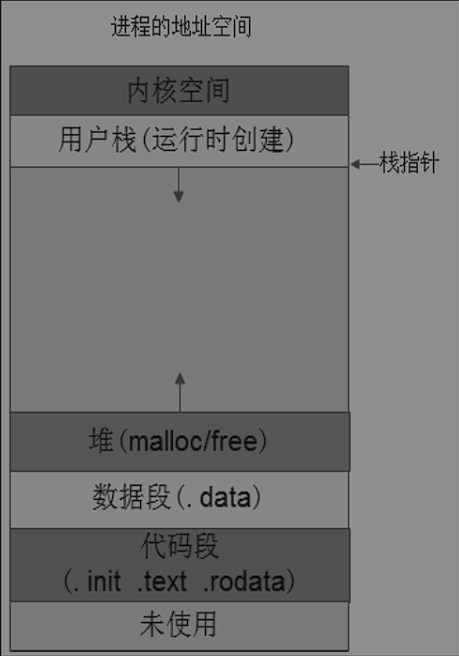
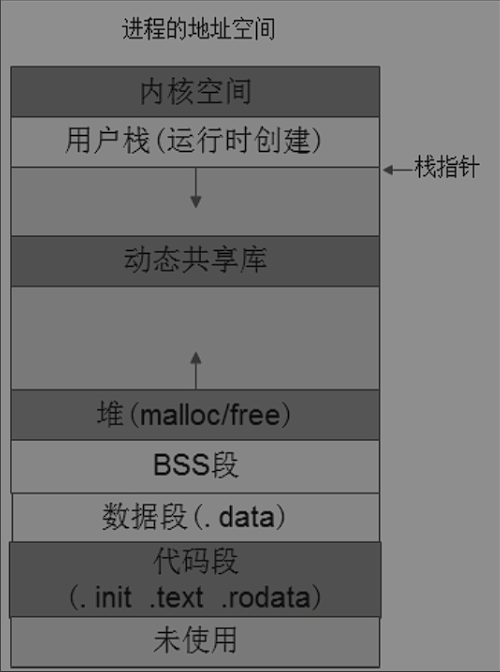
在进程的地址空间中,地址是已经固定了,整个程序运行时间内不会发生改变,这部分叫静态内存,而malloc申请的内存、函数调用过程中的栈是不断变化的,叫做动态内存。
Linux的内存管理
Linux下面的程序编译起始地址都是相同的的,是一个虚拟地址,需要配合CPU内存管理单元的支持才能运行,Linux利用页表以及MMU实现内存管理。
每个进程都会有各自的页表,用来记录各自进程中的虚拟地址到物理地址的转换。
堆空间往内核生长,栈往低地址即远离内核生长,堆栈之间有一块区域MMAP,动态共享库就是使用这片区域。
栈
入栈和出栈都依靠SP(栈指针),分类是满、空、递增、递减糅合比如:满递减栈
处理器一般用专门的寄存器保存栈的起始地址
- X86:ESP EBP
- ARM: R13(SP) R11(FP)
防止黑客袭击,Linux内核一般会见将栈的起始地址设置为随机的。初始化之后SP就会指向这片空间的栈顶,当需要入栈、出栈,SP就会移动。
栈的初始化还涉及栈空间大小的确定,可以通过ulimit -s num设置栈大小
默认会给予8MB的大小,小了容易溢出造成段错误,大了容易影响速度。
这也是为什么函数递归容易爆栈的原因,因为栈大小较小。
函数调用
每个函数有属于之间的栈空间(FP:栈帧),每个栈帧使用两个寄存器FP和SP维护,FP指向栈帧底部,SP指向栈帧顶部。函数栈帧除了保存局部变量和实参还用来保存函数上下文。
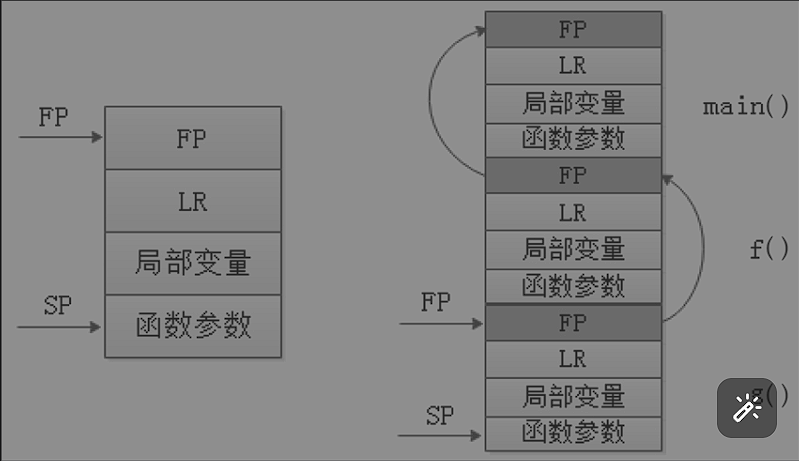
关于参数的调用方式有ATPCS规则,超过4个参数使用压栈的方式传递,把传递约束方式叫做调用惯例

c语言采用的cdecl从右到左的顺序压栈,cdecl的好处是可以预先知道参数和返回大小,支持了可变参数的调用。
形参只有在实际调用的时候才会在栈中分配临时存储单元,所以只是产生副本而不是修改原值。
堆空间:
堆空间位于BSS后面
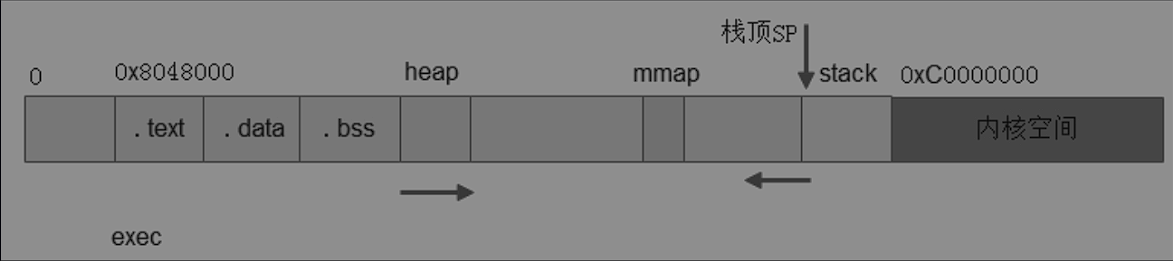
堆内存是匿名化的一般都是通过指针访问
函数运行期间堆函数栈内的内存访问不能像变量那样通过变量名直接访问而是用FP和SP间接访问
裸机环境:嵌入式环境频繁使用和释放堆空间容易造成碎片化,不建议使用堆空间,如果大块内存可以使用全局数组
而操作系统下的会改善碎片频繁的情况:UC/OS内核源码中有一个os_mem.c这个实现了对堆内存的管理。
就是将堆以内存块的形式进行管理。每个内存分区使用一个结构体表示,也叫做内存空间快。
image-20250428224448415

内存块构成链表,通过内存控制块结构体中的OSMemFreeList成员可以获取指向该链表的指针。
下图的OSMemFreeList是一个全局指针变量,指向链表第一个节点
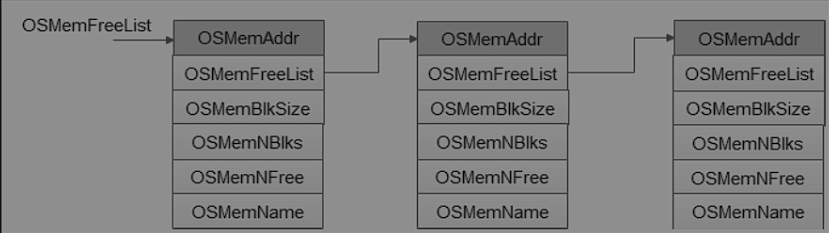
UC/OS的堆管理还是有弊端,内存块的大小必须大于4个字节,而且在申请之前要熟悉要创建的堆的内存防止越界
liNUX 堆内存管理
Linux内核的内存管理子系统负责整个Linux虚拟空间的权限管理和地址转换。
重要
当用户申请内存大于128k的时候一般通过mmap系统调用直接映射一片内存进行使用,结束之后使用ummap调用归还内存。mmap是Linux进程空间的特殊区域,主要给动态库的加载和mmap文件映射。mmap的区域大多位于0xbxxxx区域,紧挨着进程的用户栈。
ps |grep a.out #查看进程号
cat /proc/pid/maps#查看进程的内存布局各段之间有一个随机编译段,用来防止被攻击,所以每次运行malloc开辟的空间起始地址是不一样的,当然有一个randomize_va_space控制。
cat /proc/sys/kernel/randomize_va_space
echo 0 > /proc/sys/kernel/randomize_va_space#可以修改这个选项
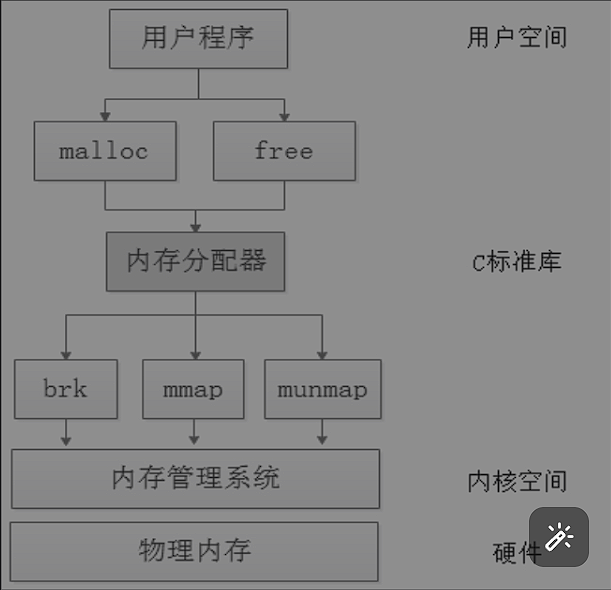
#使用之后就会看到进程1起始栈的空间紧挨着内核空间,heap 紧挨bss mmap紧挨stack空间用户创建的每个Linux进程,内核对应使用一个task_struct结构体描述。task_struct结构体内嵌一个mm_struct结构体,描述进程的代码段、数据段、堆栈起始地址。当用户使用malloc()申请的内存大小大于当前的堆区时,malloc()就会通过brk()系统调用,修改mm_struct中的成员变量brk来扩展堆区的大小。brk()系统调用的核心就是通过扩展数据段的边界来修改数据段的大小。
代码段和数据段的大小在编译的就确定,前者具有可执行和可读,后者可读写。栈和代码段之间的空间需要申请才能使用brk()调用通过扩展数据段的终止边界,扩大可读写内存空间,并且把这段空间作为堆区,使用start_brk和brk来标注堆区的起始和终止。
系统调用意味上下文的切换,系统调用是不支持任意大小的内存分配的,容易造成资源浪费。
所以为了提高内存申请的效率,减少系统调用带来的开销,在用户层进行介入,当使用brk()和mmap()申请到内存之后,进行free()释放的时候,释放的内存其实是被内存分配器接管了,通过一个链表收集起来,等下次有用户再去申请内存时候,可以直接在链表找内存块,如果空间不够再走到brk()和mmap()。其实这个内存分配器就相当于一个内存池。
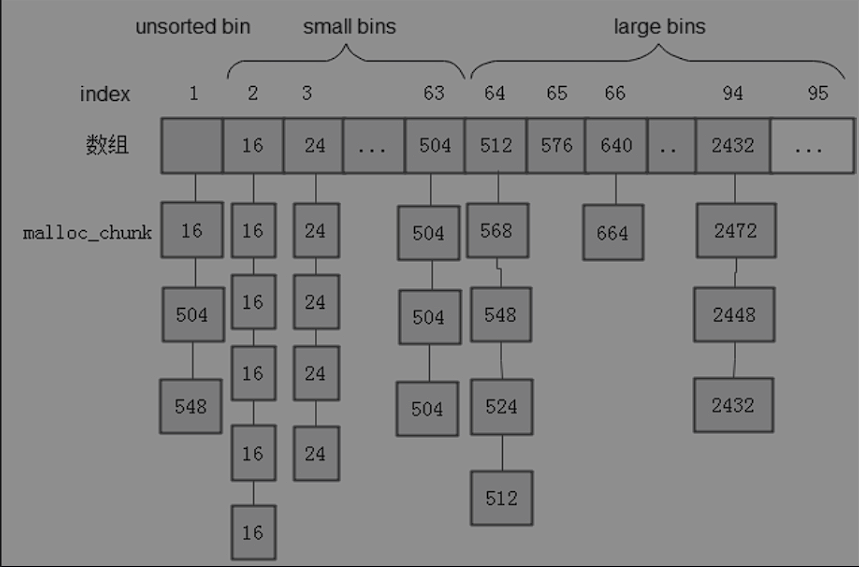
除了上图中数组的Bit以外还有一个fast bins,用户释放到小于M_MXFAST的内存块首先放到fast bins里面,fast bins由单链表构成,效率高。
适当实际,fast bins会将物理相邻的空闲内存块合并,存放到unsorted bin中,如果内存分配器在unsorted bin中没有找到适合大小的内存块,就会将unsorted bins中物理相邻的内存块合并,根据合并后的内存块大小再迁移到small bins或者large bins,之后去找large bins如果找到了大于当前要求的将内存块取出来然后进行切割,剩余部分放到unsorted bins中。如果large bins里面也找不到,那么就会到top chunk 分配内存,top chunk 不属任何bins,如果申请内存小于top chunk top chunk切割,一部分给用户,剩余作为新的top chunk,如果top chunk 还不够那么机会通过sbrk()和mmap()扩展top chunk大小。当用户申请的内存大于M_MMAP_THRESHOLD(默认128K),内存就会通过mmap进行申请内存,这种区域叫做mmap chunk ,当用户free这片空间的时候,内存分配器通过munmap()归还空间。
mmap
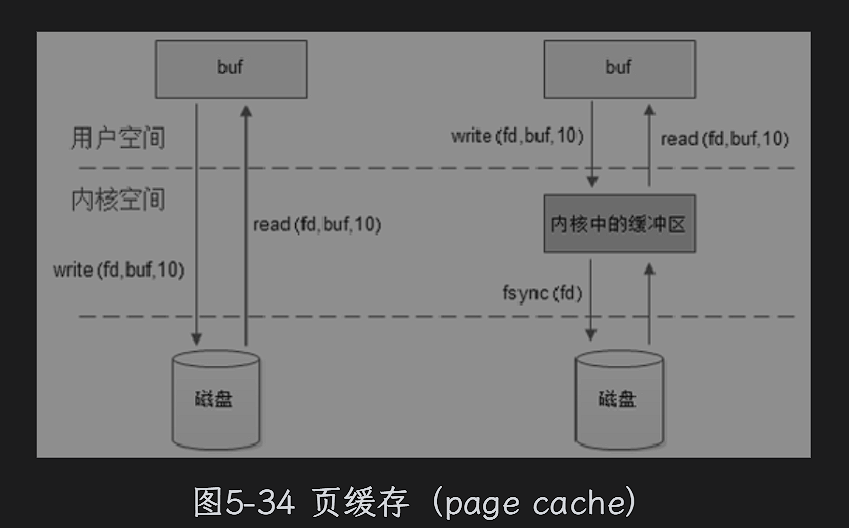
read 和write读写流程如左边所示,不过为了减少对于磁盘的访问,提高效率,利用程序的局部原理提供了一种磁盘缓冲机制。多个文件可能要读到page cache物理页面中,Linux内核通过一个叫做radix tree的树结构管理这些缓存对象。一个物理页上可以是文件也缓存也可以是交换缓存,甚至是普通缓存。文件页缓存通过一个address_space 结构体让磁盘文件和内存产生关联通过inode->immapping成员指向address_space对象,物理也中的page->mapping指向页缓存owner的address_space.
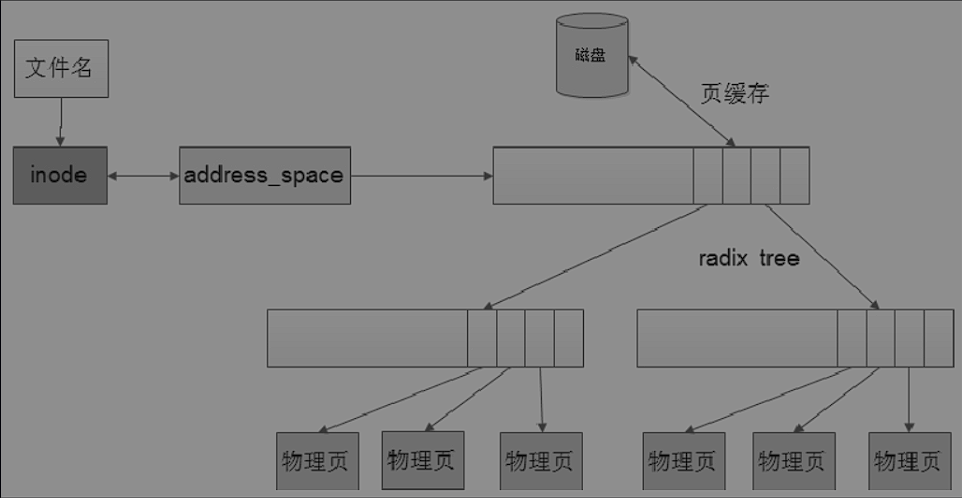
当读取指定文件的时候,文件描述符会找到对应的address_space,通过入参的文件位置偏移参数可以到页缓存中找对应的物理页,如果找到了就把物理页上数据读到用户空间,如果没有找到就会去新建一个物理页到页缓存,然后从磁盘里面读取数据,最后再把物理页数据复制到用户空间。
上面的模式有一个缺陷就是频繁的系统调用导致的上下文切换开销,glibc为了解决这个问题引入了fread()\fwrite()。在用户空间C标准库会为每个文件分配一个I/O缓冲区和一个文件描述符fd。
用户可以通过FILE结构体里面的内容访问。当数据从内核的页缓存复制到I/O缓冲区,然后复制到用户的buf2中,当fread第二次读写磁盘文件就会先读I/O缓冲区;如果是fwrite()函数写文件,会先从用户的buf1缓冲区复制到I/O缓冲区,当缓冲区满时再一次性复制到内核的页缓存,linux在适当时间刷新页缓存。
这个缓冲区减少了系统调用的次数,但是增加了数据在不同缓冲区的复制次数,要优化这个可以直接将文件映射到进程虚拟空间。
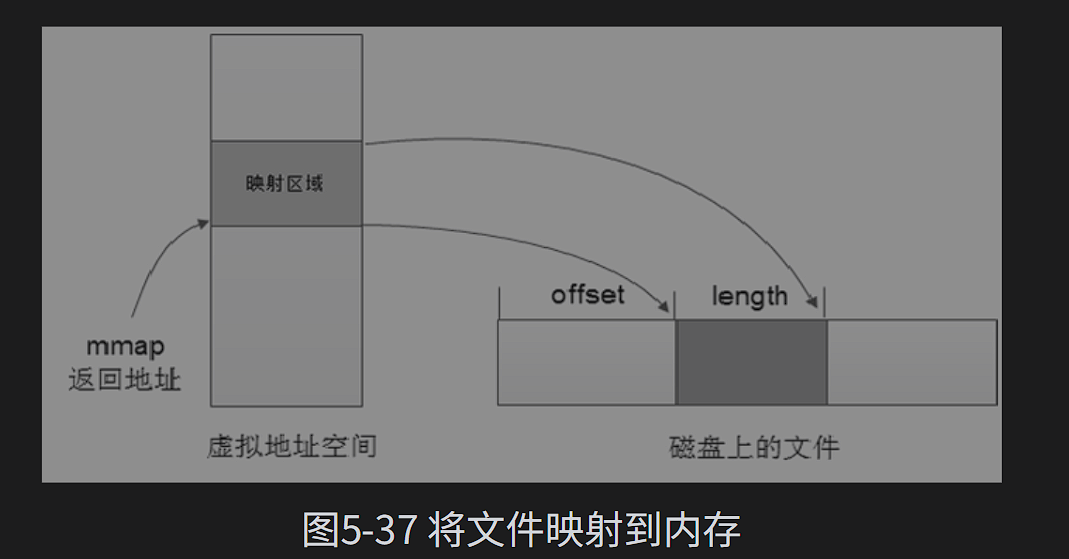
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offest);
//映射起始地址
//映射区域大小
//内存保护标志:PROT_EXEC PROT_READ PROT_WRITE
//flags 映射对象类型MAP_FIXED MAP_SHARED MAP_PRIVATE
//fd:要映射的文件描述符
//offest:文件位置偏移
//mmap的参数addr和offest必须按页对齐task_struct 的mm_struct 成员描述当前进程的内存布局,进程的每个区域都用vm_area_struct结构体对象描述。
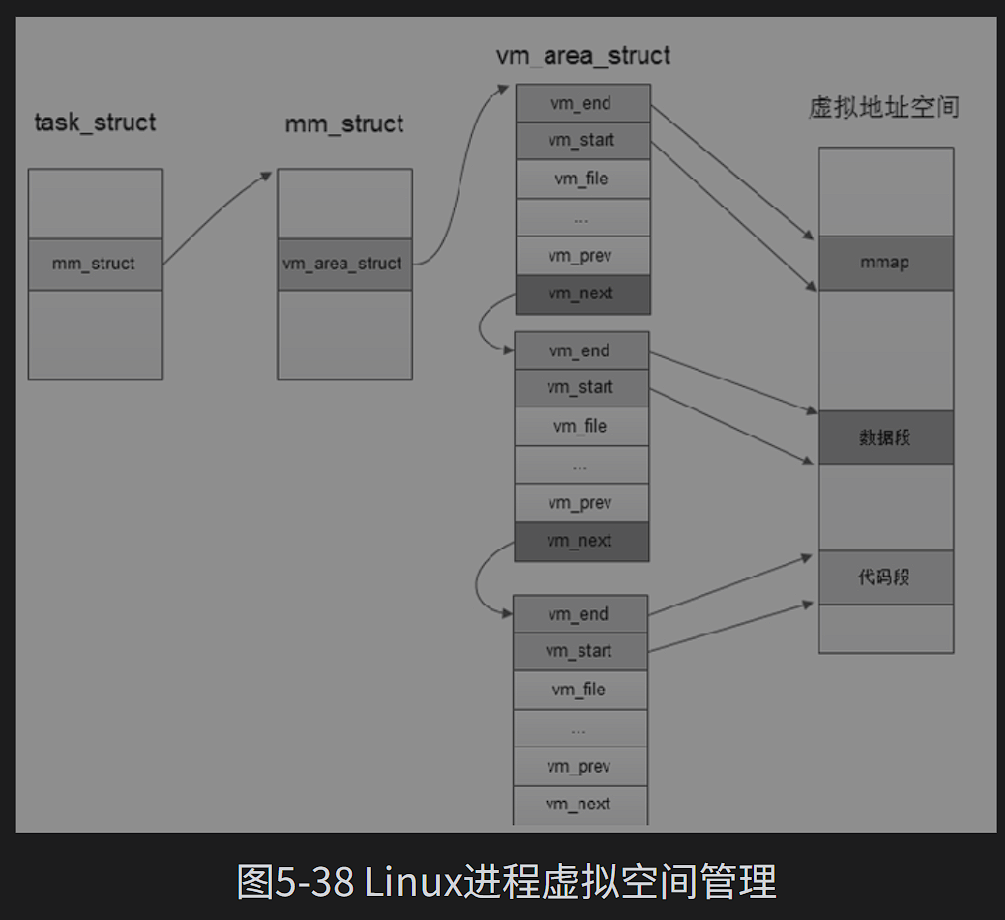
mmap完成了映射,当第一次读写的时候发现,映射区域没有分配物理内存,会产生一个请页异常,Linux内存管理子系统就会给这片映射内存分配物理内存。
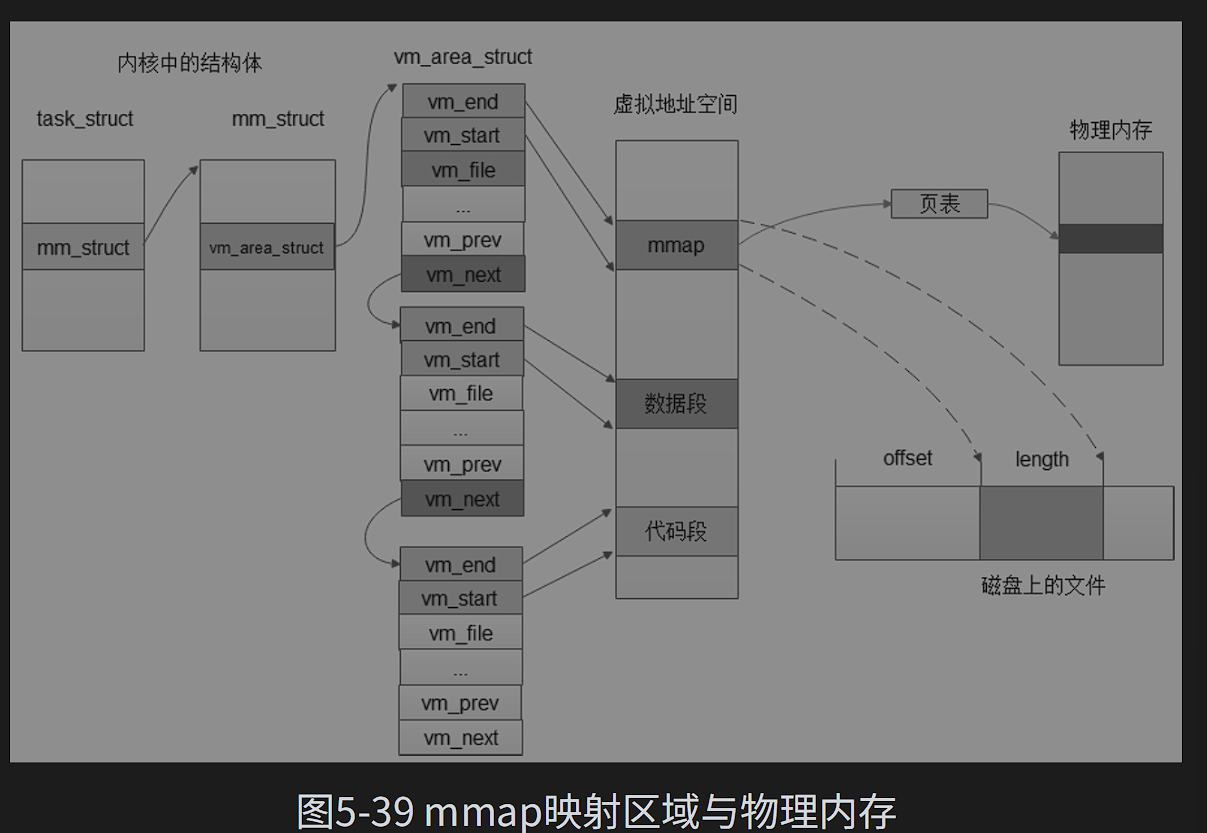
进程查找动态库的时候先去查radix tree上是否以及有了需要的动态库,有的话就修改当前进程的页表项,将当前进程的映射区域直接映射到想要的动态库的物理内存上。
同一动态库虽然映射到了不同的虚拟地址空间,但是MMU的地址转换都是指向同一块物理空间,因此动态库又叫动态共享库。
内存泄漏及内存问题
广义的内存泄漏
连续申请和释放造成了内存碎片,比如fast bins的使用,通过glibc的内存分配器进行调整,让需求达到更大匹配。
#Include<malloc.h>
int mallocpt(int param, int value);
//M_ARENA_MAX :可以创建的最大内存分区数,在多线程下经常创建多个分区
//M_MMAP_MAX:可以申请的映射分区个数,0表示关闭
//M_MMAP_THRESHOLD:当申请的内存大于阈值的时候使用MMAP分配内存
//M_MXFAST:fast bins中内存块的大小阈值,最大80*sizeof(size_t)/4,0表示关闭
//M_TOP_PAD:调用sbrk()每次向系统申请/释放的内存大小
//M_RMIM_THRESIOLD:当top chunk 大小大于阈值,会释放bins中一部分内存节省内存
内存踩踏
mprotect()是Linux环境下一个用来保护内存非法写入的函数
#include<sys/mman.h>
int mprotect(void *addr, size_t len, int prot);
//第三个参数表示内存访问权限
//页(page)是Linux内存管理的基本单元,在32位系统中,一个页通常是4096字节,mprotect()要保护的内存单元通常要以页地址对齐,我们可以使用memalign()函数申请一个以页地址对齐的一片内存。valgrind
使用memcheck检查内存泄漏、越界等。
valgrind --leak-check-full//检查越界
vakgrind --tool=memcheckGNC C编译器
指定初始化
//支持指定初始化
int a[100] = {[10] = 100, [15] = 102};
int a[100] = {[10 ... 30] = 1, [50 ... 80] = 2};
//支持switch里面使用
switch (num) {
case 1:
break;
case 2 ... 8:
break;
default:
break;
}
//支持结构体初始化
struct student {
char name[20];
int age;
};
int main(void)
{
//第一种是gnu的初始化方式
struct student stu = {
.name = "name",
.age =18
};
struct student stu2 = {"ww", 18};
}语句表达式
注
表达式:有操作符和操作数构成的式子。
有关系、逻辑、条件、赋值、算术
语句表达式是堆C语言标准做了扩展,允许在一个表达式内嵌语句,允许在表达式内部使用局部变量、for循环和goto跳转语句。
//({表达式; 表达式; 表达式;})
int main(void)
{
int sum = 0;
sum = ({
int s = 0;
for (int i = 0; i < 10; i++) {
s = s + i;
}
s;
})
}
//这个sum后面就是语句表达式,其中,语句表达式的值就是内嵌语句中的最后一个表达式的值。
//宏里面使用语句表达式eg:使用宏比较出最大值
#define MAX(a, b) ((a) > (b) ? (a) : (b))
//上面无法面对i++等情况
//但是语句表达式:
#define MAX(a, b) (\
int _a = a;\
int _b = b;\
_a > _b ? _a : _b;\
})
#define MAX(type, a, b) ({\
type _a = a;\
type _b = b;\
_a > _b ? _a : _b;\
})
#define MAX(a, b) ({\
typeof(a) _a = a;\
typeof(b) _b = b;\
(void) (&_x == &_y)\ //这个表达式在两个数据类型不一致的情况会报警,并且设置成(void)会避免因为返回值没有使用而报警
_a > _b ? _a : _b;\
})typeof 和 container_of
typeof
类似于sizeof关键字,typeof关键字是获取变量或者表达式的类型。

container_of
当前宏的作用是根据结构体某一成员的地址,获取这个结构体的首个地址。
#define offsetof(TYPE, MEMBER) ((size_t)&((TYPE *)0)->MEMBER)
#define container_of(ptr, type, member) ({\
const typeof( ((type *)0)->member ) *_mptr = (ptr);\
(type *)( (char *)_mptr -offsetof(type, member) ); \
})
//(struct some *)0->member是一种特殊的语法,通过数字0的强转将结构体起始地址设置为0,从而得到结构体各个成员的内存排布零长度数组
零长度数组可以作为变长结构体,为什么不用指针来代替零长度数组。数组名用来表征一块连续内存空间的地址,而指针是一个变量,编译器要给它单独分配空间,用来存放它指向的变量的地址。使用零长度数组就是因为指针不仅占用存储空间而且,零长度数组不会对结构体定义造成冗余。
section
//__attribute__
/*这个声明的用途是知道编译器在编译程序的时候进行特定方面的优化和代码检查*/
__attribute__((funcname))
int global_val __attribute__((section(".data")));UBOOT自复制

uboot在源码中实现了这样的零长度数组,并指示编译器要放在的位置分别是.__ iamge_copy_start和 . __ image_copy_end等两个section里面,链接器在链接各个目标文件的时候,会按照链接脚本里面各个section的排列顺序,将各个section组装成一个可执行文件。
属性对齐:aligned
结构体按照结构体里面最大成员进行对齐,但是aligned是一个建议,不能超过编译器允许的最大值。
packed
aligned属性用来增大变量的地址对齐,元素之间因为地址对齐会造成一定的内存空洞,而packed属性则与之相反,一般减少地址对齐,指定变量或类型使用最可能小的地址对齐方式。这个会取消内存对齐的机制而让内存以最小空间分配,可以避免内存空洞。
可以和aligned一起使用,可以在避免结构体成员内部空洞的同时,又指定整个结构体的对齐方式。
format
void LOG(int num, char *fmt, ...) __attribute((format(printf,2,3)));
//这个attribute告诉编译器LOG()里面的第二个和第三个参数要参考printf()里面的方式。变参函数实现
和main函数中的实现方式相似通过将参数放在连续空间里面通过指针偏移来访问。
#define DUBUG
void __attribute__((format(printf, 1,2))) LOG(char *fmt, ...)
{
#ifdef DEBUG
va_list args;
va_start(args, fmt);
vprintf(fmt, args);
va_end(args);
#endif
}weak
void __attribute((weak)) func(void);
int num __attribute__(weak);
//强符号:函数名,初始化的全局变量名
//弱符号:未初始化的全局变量名
//强强不共存、强弱可共存、都弱选大体积弱符号的用途:当一个函数被声明为弱符号时候,有一个特殊的地方,当链接器找不到这个函数的定义的时候不会报错,编译器会将这个函数名,即弱符号设定为0或一个特殊的值,只有当调用这个函数跳转到零地址或一个特殊的地址才会报错,产生一个内存错误。
//main.c
void __attribute__(weak) func(void);
int main(void)
{
if(func) {//这个就可以检测弱符号函数是否有实现,这样可以避免由于弱符号函数未实现调用时候导致的段错误
func();
}
}
//alias的作用是给函数定义一个别名
void __f(void)
{
printf("here\n");
}
void f() __attribute__((alias("__f")));
int main(void)
{
f();
return 0;
}内联函数
static inline __attribute__((noinline)) int func();
static inline __attribute__((always_inline)) int func();
//inline将函数声明为内联函数,使用inline和register类似只是一个建议
注
register修饰一个变量会将变量放到寄存器里面,但是具体放不放由编译器来权衡
内联展开:适用于少量而多次调用且函数体内无指针赋值、递归、循环等语句的函数场景,减少了上下文切换的开销。
内联相较于宏具有:
- 参数类型检查
- 可调式
- 具有返回值
- 接口封装
内联会让程序体制膨胀,内联函数降低了函数的复用性,编译器在对内联函数做展开时,除了检测用户定义的内联函数内部是否有指针、循环、、递归还会在函数执行效率和函数调用开销之间进行权衡。
使用static inline的好处是为了在多个.c包含.h里面的时候,会在每个.c里面生成一个副本不会出现冲突的问题。
内建函数
内建函数是编译器内部实现的函数是无需像标准库函数一般使用,内建函数一般在编译器内部使用主要用途有:
- 处理变长参数列表
- 处理程序运行异常、编译优化、性能优化
- 查看函数运行时的底层信息、堆栈信息
- 实现C标准库的常用函数
了解
__ builtin_return_address(levle)和 __builtin_frame_address(level)是较为常用的内建函数
__builtin_return_address(LEVEL)
//0:获取当前函数的返回地址
//1:获取上一级函数的返回地址
//2:返回上二级函数的返回地址
//通过栈帧实现函数链的调用,当前函数的栈帧会保存上一个栈帧的起始地址。
//FP和SP分别指向当前栈帧的起始地址和结束地址,当有函数调用的时候FP和SP就会切换到调用函数的栈帧。
__builtin_frame_address(LEVEL)
//0:查看当前函数的栈帧地址C标准库的内建函数:
常见的内建函数:要使用的化要在前面加上__builtin
● 与内存相关的函数:memcpy()、memset()、memcmp()。
● 数学函数:log()、cos()、abs()、exp()。
● 字符串处理函数:strcat()、strcmp()、strcpy()、strlen()。
● 打印函数:printf()、scanf()、putchar()、puts()。
还有一些用于编译的内建函数:__builtin_constant_p(n)
该函数的作用是用来判断参数n在编译的时候是否为常量,如果是就返回一,不是就返回0.
#define __dma_cache_sync(addr, sz, dir) \
do { \
if (__builtin_constant_p(dir)) {\
} else {\
}
} while (0)__builtin_expect(exp, c):这个用来进行编译优化,这个函数有两个参数,这个是告诉编译器,exp为c的可能性很大,可以在分支预测上做一些代码优化。
#define likely(x) __builtin_expect(!!(x), 1)
#define unlikely(x) __builtin_expect(!!(x), 0)
//一个细节,!!x直接转换为bool型可变参数宏
#define LOG(fmt, ...) printf(fmt, __VA_ARGS__)
#define DEBUG(...) printf(__VA_ARGS__)
int main(void)
{
LOG("hello i%s\n","wuqing");
DEBUG("here\n");
return 0;
}
//LOG("hello")会有问题因为展开没有第二个参数
//使用##宏连接符来改进上面的宏
##deine A(x) a##x
int main(void)
{
int A(1) = 2;
int A() = 3;
return 0;
}
//##的作用是链接两个字符串,在宏定义中可以使用##链接两个字符,预处理器在预处理阶段对宏展开的时候会将两边的字符合并并且删除这个##连接符。
printf(fmt, ##__VA_ARGS__)//如果列表非空那么和不用##没有区别,如果空列表那么就会将fmt后面的都好删除,称为printf(fmt);
#define LOG(fmt,args...) pritnf(fmt, args)
#define LOG(fmt, args...) printf(fmt, ##args)数据
数据类型以及存储
大端小端
DDR SDRAM内存电路中,通常使用电容器表示,充电高电位表示一,放电时低电位表示0.
bit是最小存储单位,byte是最基本的存储单位,也是最小额寻址单位。
高地址存高字节数据:小端法
高地址存低字节数据:大端法
一般处理器采用小端模式但是IBM、Sun、PowerPC架构处理器采用大端模式。
#define swap_endian_u16(A) ((A & 0XFF00 >> 8)|(A & 0XFF << 8))有符号数和无符号数
有符号数有符号位,而无符号数全是数据位,有符号数,采用补码形式存储(远吗、反码、补码)
隐式类型转换:
- 算术运算、逻辑运算、赋值表达式中运算符两侧数据类型不相同
- 函数调用过程中,实参与形参不匹配
- 函数返回值类型与函数声明类型不匹配
转换规则为低精度向高精度、从有符号数向无符号数方向转换,比如一个有符号数和一个无符号数比较的话,有符号数会转换成无符号数进行比较。
数据对齐
gcc默认的最大对齐模数是4,当超过4字节仍然按照4字节对齐。不同编译器的对齐模数是有所区别的。
union:对齐按照最大对齐模数的整数倍。
可以使用#pragma预处理和aligned/packed属性声明显式指定对齐方式。
typedef int array_t[10];
array_t array;//就可以定义一个数组
typedef int* pint;
ping a;//定义一个整数指针
typedef int(*func)(void);
func fp;//定义了一个函数指针
typedef enum color {
red,
white,
}color_t;//类似结构体给枚举类型定义别名
typedef int *(array[10])(void);//定义了一个函数 指针数组注
typedef char * pchar1;
#define pchar2 char *
char b = 10;
char c = 20;
int main(void)
{
const pchar1 p1= &c;
const pchar2 p2= &b;
p1 = &b;//报错此时p1是一个const类型
*p2 = 20;//报错因为宏会展开,站口之后是一个chang'liang
}typedef是具有作用域的
一般来说,创建一个新的数据类型,跨平台制定长度类型,与操作系统、BSP、网络自宽相关的数据类型,不透明的数据类型,隐藏结构体细节,只能用函数接口访问的数据类型。等情况适合使用typedef。
类似数组名、函数、枚举常量、函数调用等不能作为左值
指针
指针分成三类:
函数指针、对象指针、void*指针(通用指针)
int *(*(*f)(int))[10]//这是一个指向返回值为一个指针指向一个int *[10]的数组,参数为int的函数指针
(*(void(*)()0)()//将0转换为函数指针
数组和指针有些微差距,数组直接访问的,有一些奇怪的表达式
int a[] = {1,2,3};
int main()
{
int *p = a;
p[0];
0[p];
(p+2)[-2];
(-1)[p+1];
1[p-1];
//以上都表达同一个shu'zu
}面向对象
代码复用和分层思想
函数级复用、库级复用、框架级复用、系统级复用
通过函数指针的方法在结构体里面内嵌函数,此外在结构体内嵌另一个结构体或结构体指针来模拟类的继承。
Linux里面每一个设备都要有一个对应的驱动程序,否则无法对这个设备进行读写。一些总线型设备比如鼠标、键盘、U盘等USB设备,通信是按照标准usb协议进行的,为了最大化驱动代码的复用,设计了设备-总线-驱动模型:用总线提供一些方法来管理设备插拔。
oop:继承
c语言多种方法模拟继承:
- 一级继承一般就用内嵌结构体或者结构体指针
- 使用私有指针,来让一个通用类拥有私有的一些属性
oop:多态
模拟多态,通过函数指针,分别赋值不同的函数,就可以实现。
typedef struct funcdp {
void (*read)(char *name);
int (*write)(char *name);
}funcdp;
typedef struct file_sys{
char name[20];
funcdp func;
}
void read1(char *name)
{
//todo
}
void read2(char *name)
{
//todo
}
int main
{
file_sys a = {"a", read1, write1};
file_sys b = {"b", read2, write2};
file_sys* pt;
pt = &a,
p->func.read();
pt = &b;
p->func.read();
}模块化编程
注意隐式声明带来的问题,主要是隐式声明函数的参数类型可能是不一致的。
extern的使用。
分辨定义与声明:
- 省略extern且具有初始化语句
- 使用extern没有初始化语句就是声明
- 如果省略extern无初始化就是试探性定义
试探性定义(tentaticve definition),告诉编译器这个变量可能在其他文件有定义,暂时线作为声明,如果其他文件没有找到那么就是按照语法规则初始化变量,给予默认值就行初始化。就是在编译的时候先作为弱符号,如果存在同名的强符号那么这个就是声明,如果找完都没找到就把弱符号变成强符号。
前向引用:
- 隐式声明,c99之后已经禁止
- 语句标号:跳转向后的标号,可以不用声明直接使用
- 不完全类型:在被定义完整之前用于某些特定的用途
就是一些不需要具体的大小的情况,比如某些结构体里面内嵌另一个结构体的指针。
模块设计原则
高内聚低耦合是模块设计的基本原则。
非直接耦合:两个模块之间没有直接联系
数据耦合:通过参数来交换数据
标记耦合:通过参数传递记录信息
控制耦合:通过标志、开关、名字,控制另一个模块
外部耦合:所有模块访问同一个全局变量
linux内核里面有些全局变量并非真正的全局变量,EXPORT_SYMBOL就可以对其加以区分
文件系统的挂载
使用mount将存储设备挂载到文件系统的某个目录上,改变该目录到具体物理存储的映射关系,让该存储设备和要挂载的某个目录建立关联,加入全局文件系统目录树。
mount -t vfat /mnt /dev/mmcblock0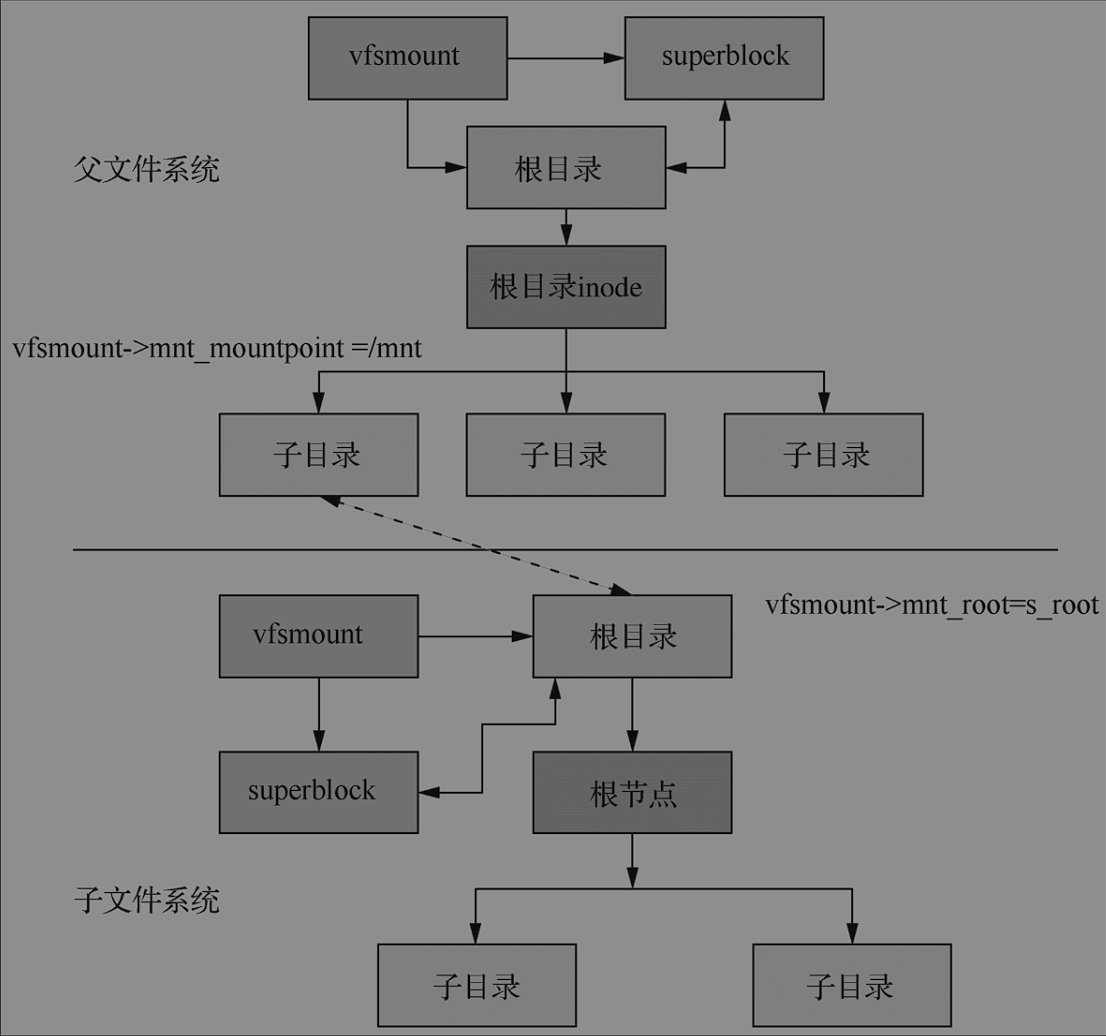
mount挂载的时候,首先每个块存储设备在挂载之前得把自己格式化一遍,然后以子文件系统的身份挂载到父文件系统的某一个目录下。对每个挂载的文件系统,Linux内核都会创建一个vfsmount和super_block对象,对象描述了文件系统挂载的所有信息,父文件系统的挂载点vsfmount->mnt_mountpoint=/mnt 和子文件系统的根目录vfsmount->mnt_root=superblock->s_root就可以通过这两个对象建立关联。
不同的存储器使用不同的接口与cpu相连,存储器几口按访问方式一般分为SRAM、DRAM接口和串行接口三种
是一种全地址、全数据线的总线接口,地址和存储单元是一一对应的,支持随机寻址,CPU可以直接访问,随机读写,SRAM和NOR Flash一般都采用这种接口和CPU相连
DRAM没有采用全地址线方式,而是采用了行地址和列地址选择的地址形式,地址线是复用的,一个地址需要多周期发送。CPU是不能直接通过地址线直接访问DRAM,要通过DRAM控制器按照规定的时序去访问DRAM的存储单元,DRAM和SDRAM一般都是采用DRAM接口与CPU处理器相连
串行接口通常以串行通信的方式发送地址和数据,读写速度相较于SRAM和SDRAM都要更慢,但是优势在于接口的管脚少,占用的CPU资源少,E2PROM、NAND Flash、SPI NOR Flash一般采用这种接口。
:::
NAND Flash容量大、成本低是嵌入式存储的主流标配,但因为不支持随机访问,所以可以选择配合一个NOR Flash,让系统从NOR Flash启动,数据用NAND存储。
处理器复电后,PC寄存器值是0,CPU默认从0地址读取指令,所以可以通过存储映射,将不同的存储器映射到零地址,CPU复位后,就可以到不同的存储器去读取指令,实现多种启动方式。
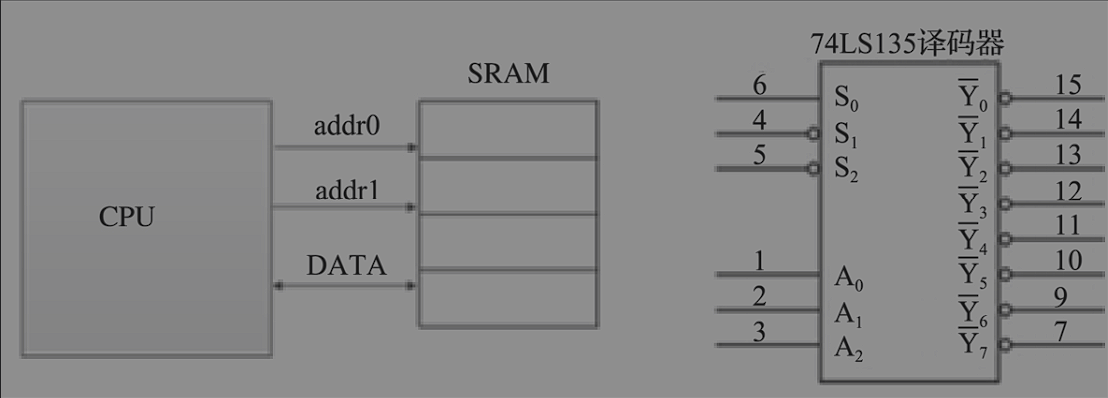
SRAM中CPU和SRAM直连,管脚发出地址信号,就有对应SRAM内部一个存储单元被选中,然后CPU就可以对该内存单元进行读写。所谓的存储映射,就是为SRAM中的存储单元分配逻辑地址的过程。
当前的嵌入式系统中,CPU和外部设备一般通过总线相连,CPU可以通过总线于多个设备相连,多个设备共享总线,此时每个物理存储单元就没有固定的地址,物理存储单元的地址就可以通过重映射进行改变。
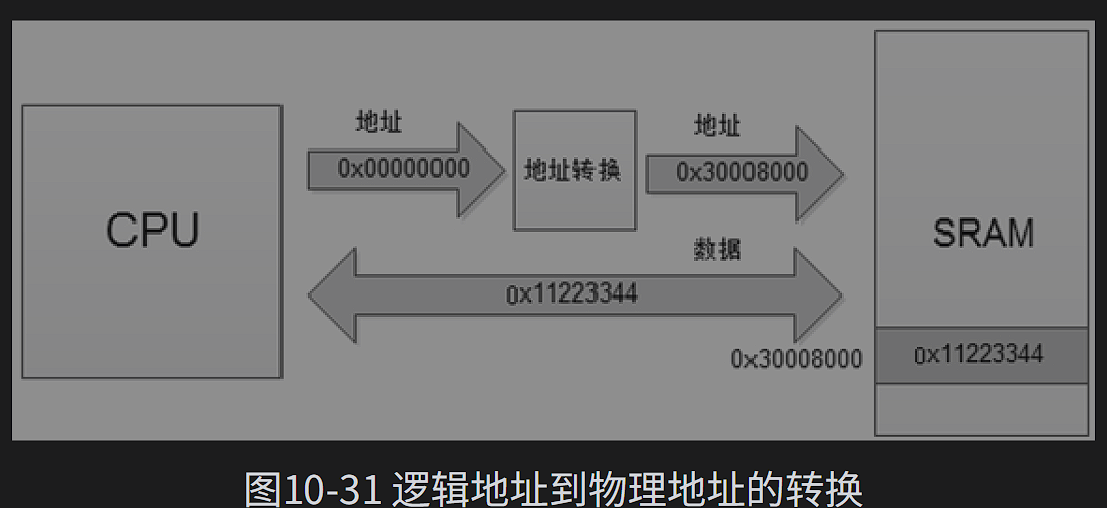
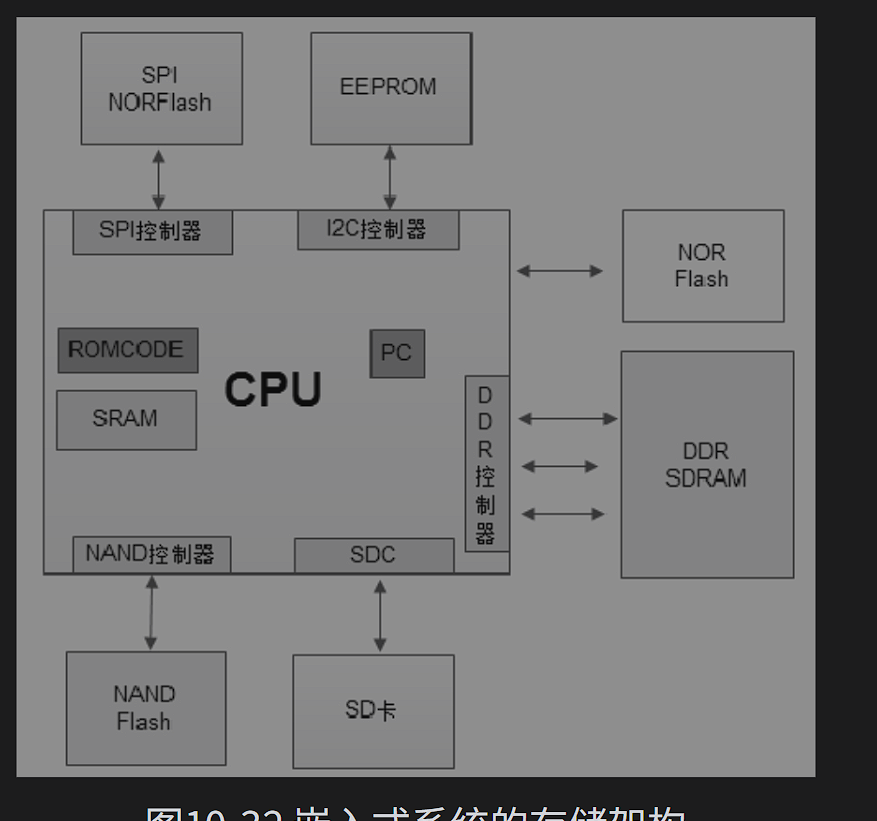
嵌入式上电之后,首先运行固化在CPU芯片内部的小段代码叫做(ROMCODE)
初始化存储器接口,建立存储映射,根据CPU管脚或eFuse值来判断系统的启动方式
除了SRAM和NOR Flash启动以外,需要将代码复制到内存执行,此外在此之前一般会代码的一部分(通常4kb)拷贝到芯片内部集成的SRAM里面执行,这段4kb的代码完成各种复制以及初始化。
内存一般是:RAM、ROM、NOR Flash其余一般是外存,内存都具有随机读写的特点,CPU的PC指针可以随机存取数据,可以直接运行代码,但是断电之后会消失,外存不支持这些。
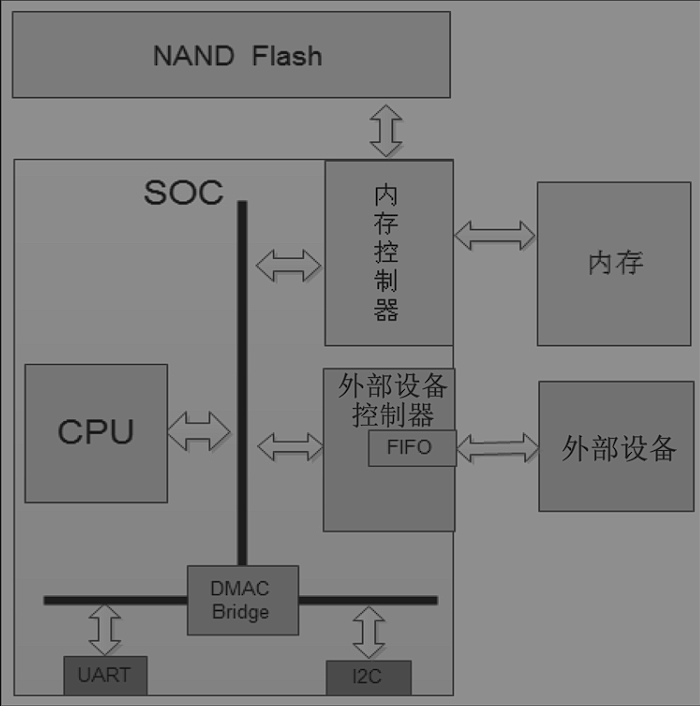
CPU同外部设备通信的方式有三种:轮询、中断和DMA。
DMA作为了数据流输入输出的中转站,首先将内存的数据搬到DMA在通过DMA发送出去,就不需要CPU参与了,传输任务完成后,DMA会通知到CPU。
一般外部设备控制器的寄存器称为I/O端口,每个寄存器对应一个端口,而给端口分配地址有两种方式:独立编址和统一编址。
注
x86架构处理器一般采用地址编址
arm一般会将外部设备控制器的寄存器、缓冲区、FIFO和内存统一编址,外部设备控制器的寄存器和内存一起共享地址空间,CPU可以按照内存读写的方式,直接读写这些寄存器来管理和操作外部设备
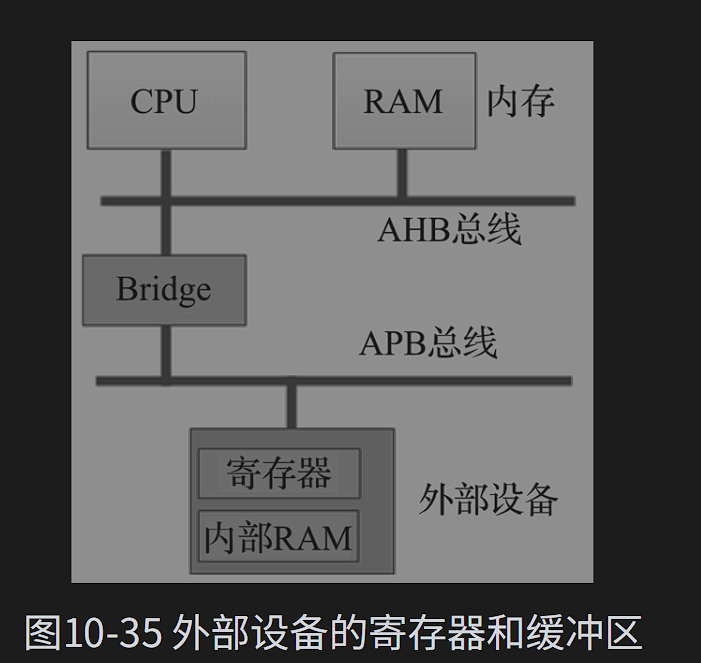
提醒
mask&(msak-1)这个可以用来判断一个数是不是2的整数次幂
位域的应用
struct register_sub {
unsigned_short en:1;
unsigned_short ep:4;
unsigned_short mode:3;
};
//意思是三个共同构成一个unsigned_short 类型其中各占多少位MMU
地址转换:MMU会根据每个进程的地址转换表将相同的虚拟地址转换位不同的物理地址
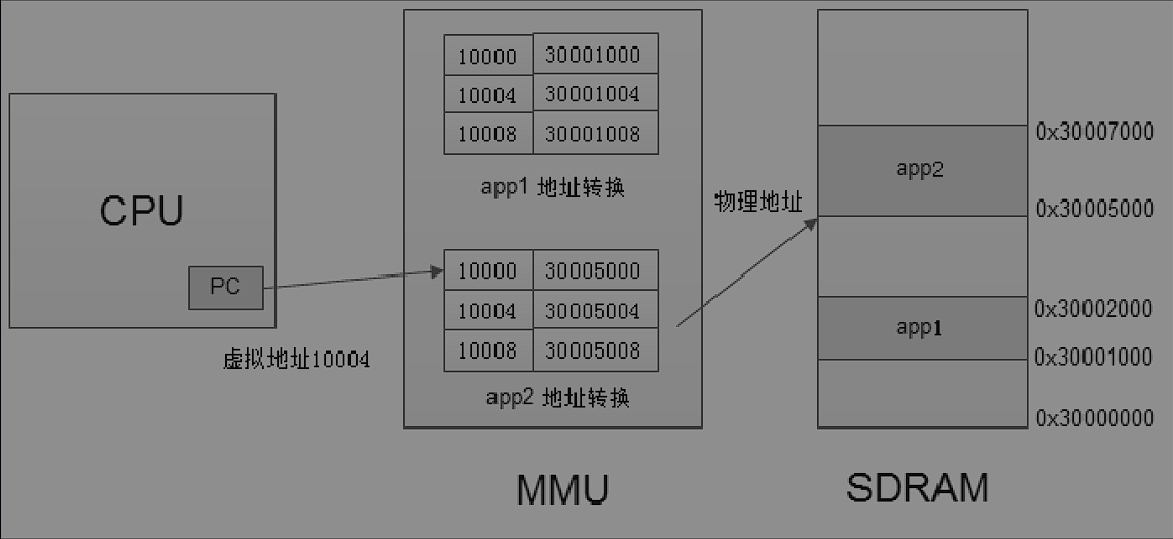
不采用一一对应的地址映射方式,将内存分割成相同大小的单元(一般4kb)叫做页或者页帧,采用页为单位进行映射,转换表中保存每个页的虚拟其实地址到物理起始地址的转换关系,此时地址转换表也叫做页表。
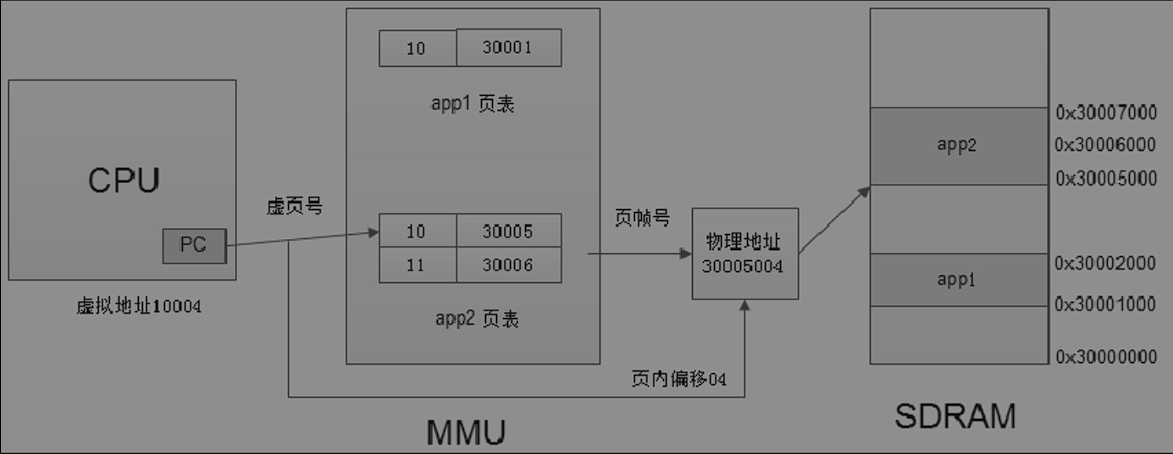
一个页表中有很多页表项,每个页表项只有每页的起始虚拟地址到物理起始地址的转换信息,,CPU将虚拟地址分解为页帧号和页内偏移的形式。比如10004其中10是页帧号,而0x004就是页内偏移(当以4kb作为页大小的时候,就可以采用低12位作为页内偏移)。地址转换的过程由软硬件一起协同配合,MMU通过页表的转换关系转换虚拟和物理地址。页表由操作系统维护,由Linux内存管理子系统复制管理和维护,当转换完成之后,会同步更新到用户空间的每一个进程里面。
为了提高效率,会首先从内存里面读取页表,根据页表内部的地址转换信息将每一个虚拟地址转换位物理地址,一般在CPU内部会集成一个缓存叫做TLB,这个用来缓存部分页表,有了这个缓存之后会首先根据虚拟地址去TLB里面查找,没有再到内存,然后更新到TLB。
Linux网络设备驱动
网络设备并非是/dev目录下的文件,应用程序最终使用套接字完成网络设备的接口,因而在网络设备身上并不能体现出“一切即文件的思想”
Linux网络设备驱动的结构
网络协议接口层、网络设备接口层、提供实际功能的设备驱动功能层以及网络设备与媒介层。
- 网络协议接口层向网络层协议提供统一的数据包收发接口,不论上层协议是ARP、IP通过dev_queue_xmit()函数发送数据,并通过netif_rx()函数接受数据。
- 网络设备接口层向协议层提供统一的用于描述具体网络设备属性和操作的结构体net_device,该结构体是设备驱动功能层中函数的容器。
- 设备驱动功能层的各函数是网络设备接口层net_device数据结构的具体成员,是驱使网络设备硬件完成相应动作的程序,通过hard_start_xmit()函数发送操作,并通过网络设备上的中断触发接受操作。
- 网络设备与媒介层是完成数据包发送和接受的物理实体,包括网络适配器和具体的传输媒介
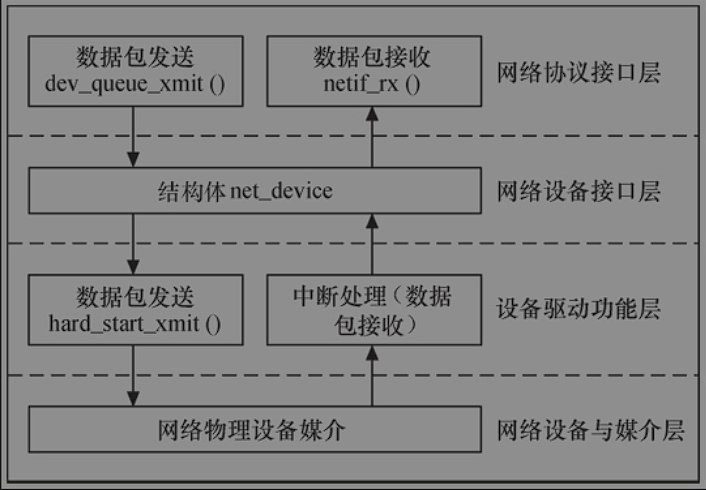
网络协议接口层最主要的功能是给上层协议提供透明的数据包发送和接收接口。
当上层ARP或IP需要发送数据包,它将调用网络协议接口层的dev_queue_xmit()函数发送该数据包,同事需传递给该函数一个指向struct sk_buff数据结构的指针
int dev_dueue_xmit(struct sk_buff *skb);同样的,上层对数据包的接收也通过向netif_rx()函数传递一个struct sk_buff数据结构的指针来完成。
int netif_rx(struct sk_buff *skb);sk_buff定义于/include/linux/skbuff.h中,叫做套接字huac