
LInux设备驱动开发
简述以及环境构建
简单的系统其实并不需要操作系统,一个无限循环中夹杂对设备中断的检测或者对哦设备的轮询是这种系统中软件的典型架构。
代码示例:
int main(int argc, char* argv[])
{
while(1)
{
if(serialInt==1)
{
ProcessSerialInt();//处理串口中断
serialInt=0;//中断标志位清零
}
if(keyInt==1)
{
ProcessKeyInt();
KeyInt=0;
}
status = CheckXXX();
switch(status)
{
//....
}
}
}注
像这样的系统里面,虽然不存在操作系统,但是设备驱动是必须要有的。
当有操作系统的时候的设备驱动,驱动需要融入内核之中,为了实现这种要在驱动中设计面向操作系统内核的接口。
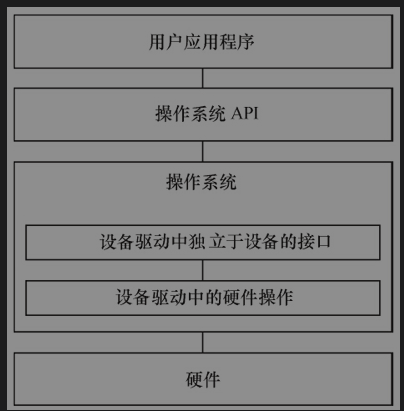
驱动针对的对象是存储器以及外设,包括CPU内部集成的存储器和外设,不是针对CPU内核。Linux将存储器和外设分为3个基础大类:字符设备、块设备、网络设备
字符设备:必须以串行顺序访问的设备。
块设备:可以按照任意顺序的顺序进行访问
简易驱动:LED
无操作系统的LED
在嵌入式系统里面:LED一般由CPU的GPIO口进行控制。GPIO有两组寄存器控制,一组控制寄存器和一组数据寄存器。
控制寄存器可以控制GPIO的工作方式。当引脚设置为输出的时候,向数据寄存器的对应位写于1和0会修改引脚上面的电平,引脚设置为输入的时候,可以读取数据寄存器对应位获取引脚的电平高低状态。
代码清单:无操作系统时候的LED驱动
//假设条件:GPIO_REG_CTRL的物理地址中控制寄存器的第n位写入1就可以设置GPIO为输出状态
//GPIO_REG_DATA物理地址中数据寄存器的第n位写入1或者0就可以修改电平
#define reg_gpio_ctrl *(volatile int *)(ToVirtual(GPIO_REG_CTRL))
#define reg_gpio_data *(volatile int *)(ToVirtual(GPIO_REG_DATA))
//ToVirtual()的作用是当系统启动硬件MMU之后,根据物理地址以及虚拟地址的映射关系,将寄存器的物理地址转换为虚拟地址。
//volatile 是一种关键字,表示编译器访问该变量的时候不要优化,而是每次去稳定访问他的内存,即不使用缓存优化访问速度。
/* 初始化LED */
void LightInit(void)
{
reg_gpio_ctrl |= (1 << n); /* 设置GPIO为输出 */
}
/* 点亮LED */
void LightOn(void)
{
reg_gpio_data |= (1 << n); /* 在GPIO上输出高电平 */
}
/* 熄灭LED */
void LightOff(void) {
reg_gpio_data &= ~(1 << n); /* 在GPIO上输出低电平 */
}LInux下面的LED驱动
在LINUX下面可以使用字符设备驱动的框架编写,内核实际实现了一个提供sysfs节点的GPIO LED驱动。
Linux下面的LED驱动
#include .../* 包含内核中的多个头文件 */
/* 设备结构体 */
struct light_dev {
struct cdev cdev; /* 字符设备cdev结构体 */
unsigned char vaule; /* LED亮时为1,熄灭时为0,用户可读写此值 */
};
struct light_dev *light_devp;
int light_major = LIGHT_MAJOR;
MODULE_AUTHOR("Barry Song <21cnbao@gmail.com>");
MODULE_LICENSE("Dual BSD/GPL");
/* 打开和关闭函数 */
int light_open(struct inode *inode, struct file *filp)
{
struct light_dev *dev;
/* 获得设备结构体指针 */
dev = container_of(inode->i_cdev, struct light_dev, cdev);
/* 让设备结构体作为设备的私有信息 */
filp->private_data = dev;
return 0;
}
int light_release(struct inode *inode, struct file *filp)
{
return 0;
}
/* 读写设备:可以不需要 */
ssize_t light_read(struct file *filp, char __user *buf, size_t count,
loff_t *f_pos)
{
struct light_dev *dev = filp->private_data; /* 获得设备结构体 */
if (copy_to_user(buf, &(dev->value), 1))
return -EFAULT;
return 1;
}
ssize_t light_write(struct file *filp, const char __user *buf, size_t count,
loff_t *f_pos)
{
struct light_dev *dev = filp->private_data;
if (copy_from_user(&(dev->value), buf, 1))
return -EFAULT;
/* 根据写入的值点亮和熄灭LED */
if (dev->value == 1)
light_on();
else
light_off();
return 1;
}
/* ioctl函数 */
int light_ioctl(struct inode *inode, struct file *filp, unsigned int cmd,
unsigned long arg)
{
struct light_dev *dev = filp->private_data;
switch (cmd) {
case LIGHT_ON:
dev->value = 1;
light_on();
break;
case LIGHT_OFF:
dev->value = 0;
light_off();
break;
default:
/* 不能支持的命令 */
return -ENOTTY;
}
return 0;
}
struct file_operations light_fops = {
.owner = THIS_MODULE,
.read = light_read,
.write = light_write,
.ioctl = light_ioctl,
.open = light_open,
.release = light_release,
};
/* 设置字符设备cdev结构体 */
static void light_setup_cdev(struct light_dev *dev, int index)
{
int err, devno = MKDEV(light_major, index);
cdev_init(&dev->cdev, &light_fops);
dev->cdev.owner = THIS_MODULE;
dev->cdev.ops = &light_fops;
err = cdev_add(&dev->cdev, devno, 1);
if (err)
printk(KERN_NOTICE "Error %d adding LED%d", err, index);
}
/* 模块加载函数 */
int light_init(void)
{
int result;
dev_t dev = MKDEV(light_major, 0);
/* 申请字符设备号 */
if (light_major)
result = register_chrdev_region(dev, 1, "LED");
else {
result = alloc_chrdev_region(&dev, 0, 1, "LED");
light_major = MAJOR(dev);
}
if (result < 0)
return result;
/* 分配设备结构体的内存 */
light_devp = kmalloc(sizeof(struct light_dev), GFP_KERNEL);
if (!light_devp) {
result = -ENOMEM;
goto fail_malloc;
}
memset(light_devp, 0, sizeof(struct light_dev));
light_setup_cdev(light_devp, 0);
light_gpio_init();
return 0;
fail_malloc:
unregister_chrdev_region(dev, light_devp);
return result;
}
/* 模块卸载函数 */
void light_cleanup(void)
{
cdev_del(&light_devp->cdev); /* 删除字符设备结构体 */
kfree(light_devp); /* 释放在light_init中分配的内存 */
unregister_chrdev_region(MKDEV(light_major, 0), 1); /* 删除字符设备 */
}
module_init(light_init);
module_exit(light_cleanup);驱动设计的硬件基础
简述
注
描述微控制器、微处理器、数字信号处理器
归纳了嵌入式系统使用的各类存储器与CPU接口、应用领域及特点进行了归纳整理
分析常见的外设接口与总线的工作方式:串口、I2C、SPI、USB、以太网接口、PCI、PCI-E、SD、SDIO等。
讲解FPGA以及CPLD的工作原理
从实际项目进行硬件分析,如何进行原理图分析、时序分析
讲解调试过程中仪器仪表的使用方法
处理器
**通用处理器(GPP):**目前的这个主流的通用处理器采用SoC片上系统的芯片设计方法,集成了各种功能模块。
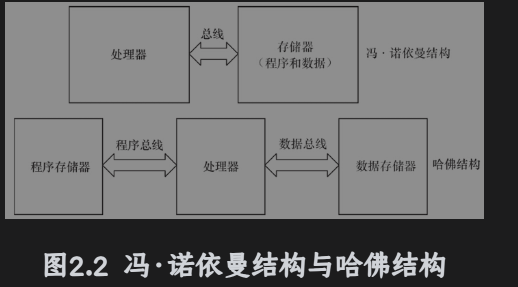
中央处理器按照体系结构可以分为:冯.诺依曼、哈佛结构。
冯.诺依曼也称过普林斯顿结构,是一种将程序指令存储器和数据存储器合并在一起的存储器结构。程序指令存储地址和数据存储地址指向同一个存储器的不同的物理结构,因此程序指令和数据的宽度相同。
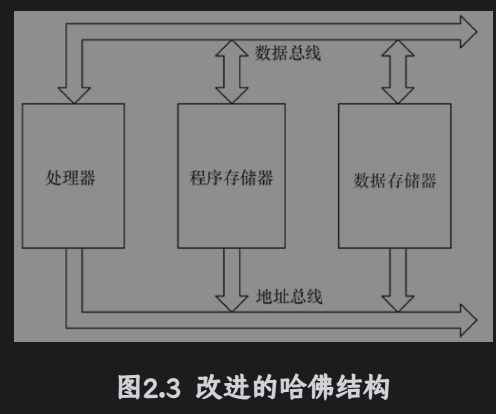
哈佛结构将程序指令和数据分布分开存储,指令和数据可以有不同的数据宽度,哈佛结构还采用独立的程序总线和数据总线,分别作为CPU与每个存储器之间的专用通信路径,具有较高的执行效率。两条总线由程序存储器和是数据存储器分时共用,改进的哈佛结构针对程序和数据,没有独立的总线,而是使用共用数据总线来完成程序存储模块或数据存储模块与CPU之间的数据传输,共用的地址总线来寻址程序和数据。
也可以按照指令集分为:RISC和CISC(复杂指令集计算机),RISC强调尽量减少指令集、指令单周期执行,但是目标代码大。
**数字信号处理器:**是一种针对通信、图像、语音视频处理等领域的算法设计的。有独立的硬件乘法器,优化卷积、数字滤波、FFT、相关矩阵运算等算法的大量重复乘法。
DSP(Digital Signal Processing )有两类,一类是定点DSP,一类是浮点DSP。(浮点的DSP运算利用硬件实现,可以在单周期内完成,因而浮点运算处理速度高于定点DSP)。
除此之外还有NPU、FPGA(现场可编程门阵列)、TPU等等(异构时代的产物)
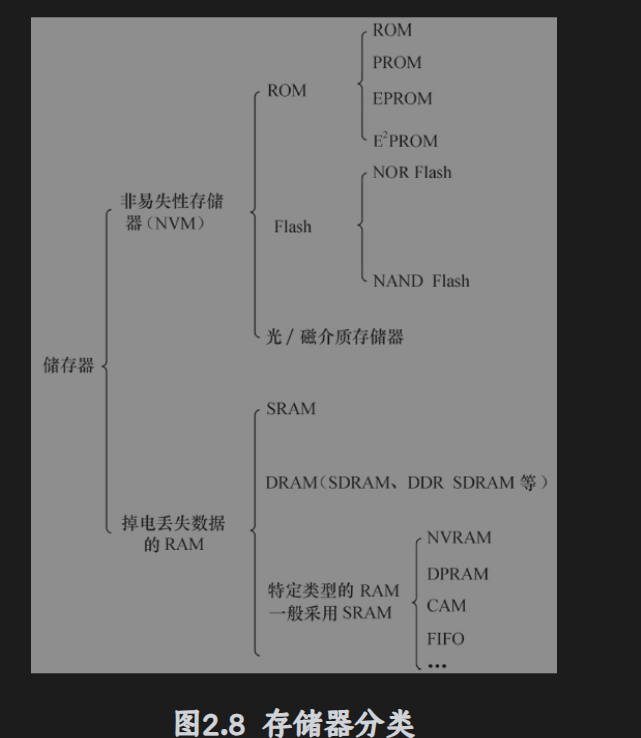
存储器
存储器主要可以分为ROM(只读存储器)、Flash(闪存)、RAM(随机存取存储器)、光、磁介质存储器
NOR(或非)和NAND(与非)在市场上面是两种主要的Flash闪存技术。
NOR与CPU的接口属于典型的类SRAM接口,不需要增加额外的控制电路。NOR Flash 特点是可芯片内执行(eXecute In Place XIP ),程序可以接在NOR里面执行。
公共闪存接口(Common Flash Interface ,CFI)是一个从NOR Flash 器件里读取数据的标准接口。可以让系统软件查询已安装的Flash 器件的参数。如果芯片不支持CFI,就需要使用JEDEC。
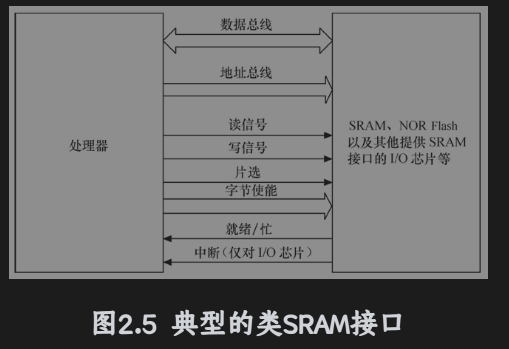
而NAND Flash和CPU的接口必须由相应的控制电路进行转换,当然也可以通过地址线或GPIO产生NAND Flash 接口的信号,NAND 以块方式进行访问,不支持芯片内执行。
NAND Flash 接口包含以下信息:I/O总线、芯片启动(CE#)、写使能、读使能、指令锁存使能(CLE)、地址锁存使能(ALE)、就绪/忙(R/B)----->NAND的容量大、价格低,而且擦除速度以及编程速度远远高于NOR Flash。
重要
由于Flash固有的电器特性,在读写的时候可能会出现几位的数据错误即位反转,NAND的这个概率是要远高于NOR的。在使用NAND技术的时候同时要采用错误探测/错误更正(EDC/ECC)
Flash 编程原理只能将1写为0,而面对0只能将之前的块擦除,这个擦除就相当于把0变为1,但是没有真正意义上的变0为1;
Flash存在一个负载均衡的问题:不能经常在同一地方进行擦除和写的动作容易导致,坏块。
NOR Flash 可以使用SPI接口进行访问节省引脚,此外还有些支持DDR模式,能进一步提高访问速度。
IDE接口(Integrated Drive Electronics)控制硬盘控制器或光驱,IDE接口的信号与SRAM相似。人们通常把IDE也叫做ATA接口。
SOC集成了一个eFuse电编程熔丝作为OTP存储器(一次性可编程存储器)。
到目前为止的各种ROM、Flash 、磁介质存储器都属于非易失性存储器NVM范畴,掉电时候信号不会丢失。
RAM
SRAM(静态RAM)、DRAM(动态RAM)
DRAM:采用电荷的形式存储,数据存储在电容器里面,由于电容器会因为漏电而出现电荷丢失,所以DRAM需要定期刷新。
SRAM:只要供电就会保持一个值,SRAM没有刷新周期,每个SRAM存储单元由6个晶体管组成,DRAM存储电源由1个晶体管和一个电容器组成。
SDRAM、DDR SDRAM都是DRAM的范畴,采用CPU外存控制器同步的时钟工作(不是和CPU的工作频率一致)
与SDRAM相比DDR SDRAM 同时利用了时钟脉冲的上升沿和下降沿路径传输数据,在时钟频率不变,数据传输频率翻倍。
还有使用RSL的RDRAM 和DIrect RDRAM,针对不同的环境嵌入式系统还会使用一些特定的RAM
DPRAM
DPRAM可以通过两个端口同时访问,具有完全独立的两套数据总线、地址总线、读写控制线;通常用于两个CPU之间进行交互。一端被写入数据之后,另一端可以通过轮询或中断获知,并读取其写入的数据。
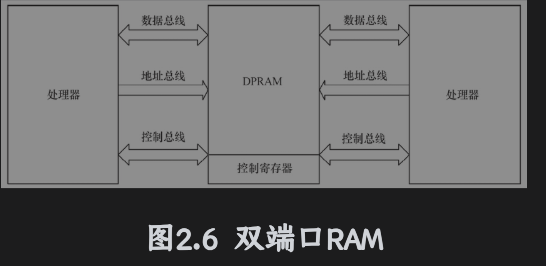
其优势就是速度快、实时性高、接口简单并且双工。
CAM:内容寻址RAM
是一种特殊的存储阵列RAM,他的主要工作机制就是同时将一个输入数据项和存储在CAM里面的所有数据进行自动的比较,判断是否匹配并输出数据对应的匹配数据。
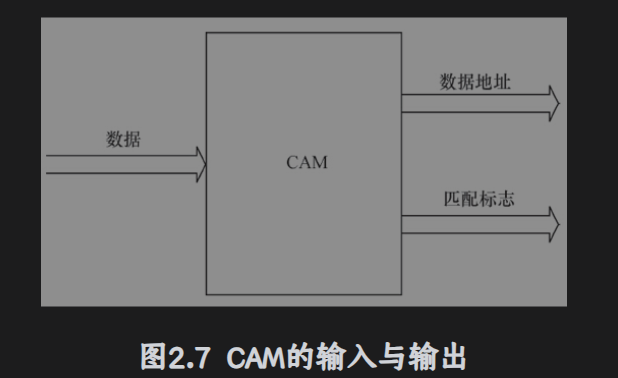
这玩意儿极大提高了系统的性能。
FIFO
fifo存储器特点是先进先出,多用于数据缓冲。FIFO和DPRAM类似,有两个访问端口,但是FIFO的端口不对等,一进一出
接口和总线
串口
RS-232、RS422、RS-485都是串行数据接口标准,最开始是EIA制定。
RS-232C是嵌入式中最广泛的串行接口,标准接口有25跳线(4条数据线、11条控制线、3条定时线、7条备用线)。其中常用的有9根,RTS/CTS(请求发送、清除发送流控制)、RXD/TXD(数据收发)、DSR/DTR(数据终端就绪、数据设置就绪流控制)、DCD(数据载波检测)、Ringing-RI(振林指示)、SG(信号地)信号
注
RTS:用来表示DTE(数据终端设备)请求DCE(数据通信设备)发送数据,当终端要发送的时候信号有效。
CTS:表示DCR准备接收数据对RTS响应
RXD:DTE通过RXD接收DCE的串行数据
TXD:DTE发送数据到DCE
DSR:有效就表示DCE可以用
DTR:有效表明DTE可以使用
DCD:当本地DCE设备收到其他DCE过来的载波信号的时候,当前就会有效并且通知DTE准备接收,将载波转变为数字信号,经由RXD线推送
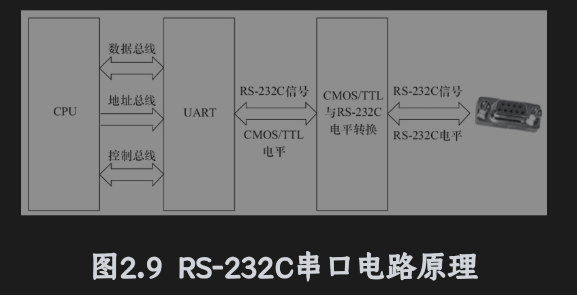
UART:通用异步接收发送器
I2 C
内置集成电路总线(I2 C)是两线式串行总线,主要用来链接微控制器和外围设备。
组成I2 C的两个信号是数据线SDA 和时钟SCL,为了避免总线信号混乱,要求设备连接到总线的输出端必须是开漏输出或者集电极开路输出的结构。
当SCL稳定在高电平的时候,SDA由高到低变化就产生一个开始位,而由低到高变化产生一个停止位。
SPI
SPI:串行外设接口 是一种同步串行外设接口,他可以使CPU与各种外围设备以串行方式进行通信以交换信息。
SPI接口一般使用4条线:串行时钟线(sclk)、主机输入/从机输出数据线(moso)、主机输出/从机输入数据线(mosi)、低电平优先的从机选择线(ss)
为同外设进行数据交换,根据外设工作要求,输出串行同步时钟极性(CPOL)和相位(CPHA)可以进行配置。如果CPOL=0,串行同步时钟的空闲状态为低电平,那=1就是。。。,如果CPHA=0,在串行同步时钟的第一个跳变沿数据被采样,如果CPHA=1,在串行同步时钟的第二个跳变沿被采样。
USB
通用串行总线,usb2.0的总线机械结构简单,采用4芯的屏蔽线,一对差分线(D+、D-)传送信号,另一对(VBUS、电源地)传送+5v的直流电。USB3.0是8条内部线路,新增了SSRX与SSTX专门为USB3.0设计的线路。
每个USB设备会有一个或者多个逻辑连接点在里面,每个连接点叫做端点。USB有多种传输模式
- 控制传输模式
- 同步传输模式
- 中断传输方式
- 批量传输方式,USB3.0bulk streams支持多个数据流,每个数据流被分配给一个stream id,每个id和一个主机缓冲区对应
在USB中,集线器负责检测设备的连接和断开,利用其中断端点向主机报告,一旦获悉有新设备,主机就发送一系列请求给设备所挂载的集线器,再由集线器建立起一条连接主机和设备之间的通信通道,然后主机用控制传输的方式通过端点0对设备发送各种请求,设备收到主机发来的请求后回复相应的信息,进行枚举操作,因此USB总线支持热插拔功能。
以太网接口
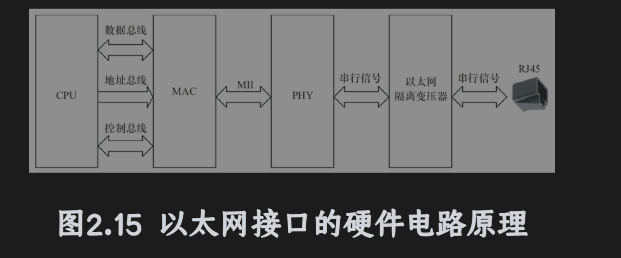
以太网接口以MAC和PHY组成,IEEEE802.3以太网标准定义,实现了数据链路层。
MAC和PHY之间采用MII连接,是以太网的行业标准,包括一个数据接口与MAC和PHY之间的一个管理接口。
数据接口由用于发送和接受的两条独立信道,每个信道都有自己的数据、时钟和控制信号。MII接口总共需要16个信号。MII管理接口包含两个信号,一个是时钟信号,另一个是数据信号。
PCI和PCI-E
PCI是一种局部总线
注
数据总线为32位,可以扩充到64位
可进行突发模式传输(Burst),指的是取得总线控制权后连续进行多个数据的传输,与单周期的一个总线周期只传送一个数据有所区别。
总线操作和处理器-存储器子系统操作并行
采用中央集中式总线仲裁
支持全自动配置、资源分配,PCI卡内有设备信息寄存器组为系统提供卡的信息
PCI总线规范独立与微处理器,通用性好
PCI设备可以作为主控设备控制总线
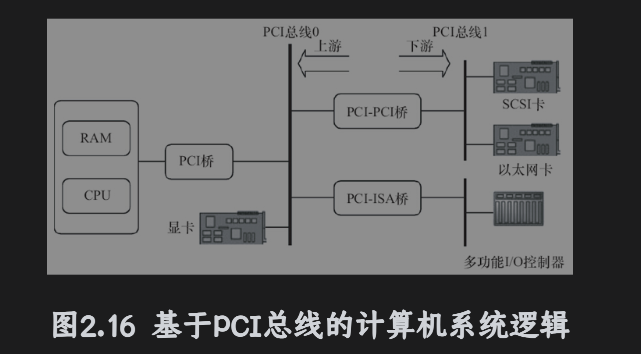
PCI卡上电之后,卡上的配置空间会被访问,里面存储着一些配置信息。
PCI-E采用点对点串行连接,同PCI相比,每个设备都有属于自己的专属连接,采用串行的方式传输可以不用向总线请求贷款,可以将传输率提高到很高的频率。
SD和SDIO
SD是存储卡标准,设计上和MMC兼容.SDIO主要有两类应用,可以移动和不可以移动。
SD和SDIO有所区别,具体可以见2.3.7节
emmc是NAND Flash 、闪存控制芯片、标准接口封装的集合,它将NAND和控制芯片直接封装在一起成为一个多芯片封装(MCP)。
CPLD 和FPGA
CPLD(复杂可编程逻辑器件)由完全可编程的与或门阵列以及宏单元构成。
CPLD的基本逻辑单元是宏单元,宏单元由一些“与或”阵列加上触发器构成,“与或”完成组合逻辑,触发器完成时序逻辑。
详细见2.3.8节
FPGA(现场可编程门阵列)基于LUT(查找表)工艺。查找表本质是一篇RAM,当用户通过原理图或HDL描述逻辑电路之后,FPGA开发软件就会自动计算逻辑电路可能的结果,并提前写入RAM。
详细见2.3.8节
硬件时序分析
概念
建立时间是指在触发器的时钟信号边沿到来以前,数据已经保持稳定不变的时间,如果建立时间不够,数据将不能在这个时钟边沿被打入触发器
保持时间是指在触发器的时钟信号边沿到来以后,数据还需稳定不变的时间,如果保持时间不i狗也不能打入触发器。
典型硬件时序
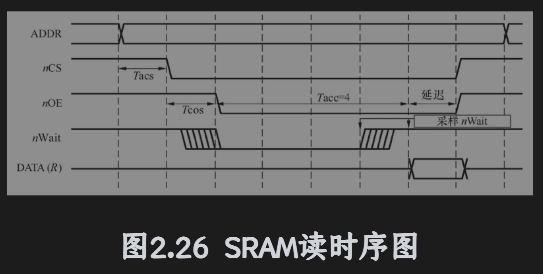
SRAM的读时序,写时序与此相似,首先,地址总线上输出要读写的地址,然后发出SRAM片选信号,接着输出读写信号,之后读写信号要经历数个等待周期。当SRAM读(写)速度比较慢,等待周期可以由MCU的相应寄存器设置,也可以通过设备就绪/忙向CPU报告,读写过程中会自动添加等待周期。
LInux内核与内核编程
LInux2.6改进点:
新的调度器:早期采用O(1)的算法,之后采用CFS(Completely Fair Scheduler,完全公平调度),在LInux3.14中,增加了一个新的调度方式:SCHED_DEADLINE,实现了EDF(Earliest Deadline First)最早截止期限优先调度算法。
内核抢占:内核任务可以被抢占。
改进的线程模型:LInux2.6以后采用NPTL(Native POSIX Thread Libary)相比较于LInux2.4的LinuxThreads模型效率大提高,内核也增加了FUTEX(Fast Userapce Mutex)
虚拟内存的变化:新内核融合了r-map(反向映射)技术,显著改善虚拟内存一定大小负载下的性能,Linux2.4里面的收,要回收页时,内核的做法是遍历每个进程的所有PTE用来判断该PTE是否与该页建立映射,如果建立就取消映射,最后无PTE与该页相关联后才收回该页。Linux后,建立反向映射,可以通过页结构体快速找到寻找页面的映射。
文件系统:增加对于日志文件系统功能支持,对扩展属性及POSIX标准访问控制的支持(支持给制定文件在文件系统中嵌入元数据)----当前研究热点是基于B树的BTRFS
音频:高级linux音频体系取代了缺陷很多旧的OSS。
总线、设备和驱动模型: 总线是三者联系起来的基础,总线类型中match()函数用来匹配设备和驱动,当匹配操作完成之后就会执行驱动程序的probe()函数。
电源管理:支持高级配置和电源接口,用于调整CPU在不同的负载下工作于不同的时钟频率以降低功耗。
联网和IPSEC:加入对IPSec的支持,删除了原来内核内置的HTTP服务器khttpd,加入对新的NFSV4客户机/服务器的支持,并改进了对IPV6的支持。
用户层界面:重写了帧缓冲/控制台层,加入了对近乎所有接口设备的支持,设备驱动程序方面,在API中增加内存池、sysfs文件系统、内核模块从.o变为.ko、驱动模块编译方式、模块使用计数、模块加载和卸载函数的定义等方面。
内核组成
内核目录结构
- .arch
包含和硬件体系相关的代码,每种平台占一个相应的目录,如i386、arm、arm64、powerpc、mips等,linux内核现在支持30种左右的体系,当前目录放的就是各个平台以及及芯片对linux内核的进程调度、内存管理、中断等的支持,以及每个具体Soc和电路板的板级支持代码
- .block:块设备驱动程序I/O调度
- .crypto:常用于加密和散列算法,以及压缩和CRC校验算法
- .documentation:内核各部分的通用解释和注释
- .drivers:设备驱动程序,每个不同的驱动占用有个子目录,如char、block、net、mtd、i2c等
- .fs:所支持的各种文件系统,EXT、FAT、NTFS、JFFS2等
- .include:头文件,与系统相关的放在include/linux子目录下
- .init:内核初始化代码
- .ipc:进程间通信代码
- .kernel:内核最核心部分,包括进程调度、定时器等而和平台相关的代码放在arch/*/kernel目录下面
- .lib:库文件代码
- .mm:内存管理代码,和平台相关的代码放在arch/*/mm目录下面
- .net:网络相关代码,实现各种常见的网络协议
- .scriptes:内核脚本文件
- .security:SElinux模块
- .sound:ALSA、OSS音频设备的驱动核心代码和常用设备驱动
- .usr:实现打包和压缩的cpio
- .inluce:内核API级别的头文件
内核要做到驱动和arch分离,驱动中不包含板级信息,实现驱动跨越平台
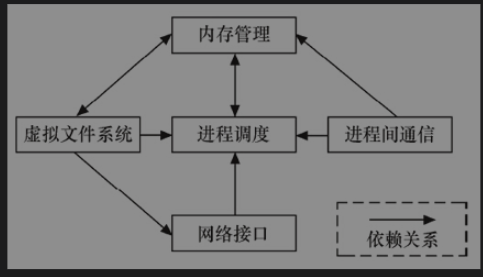
- 进程管理
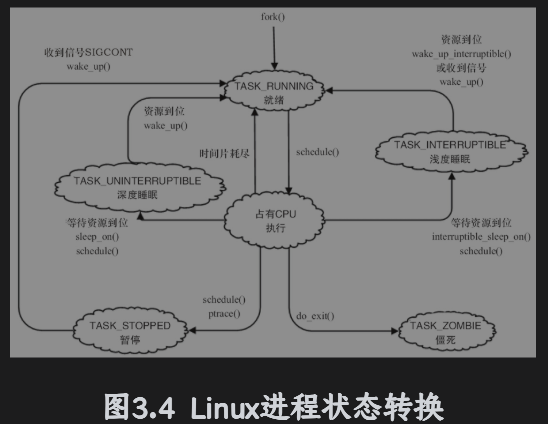
完全处于TASK_UNINTERRUPTIBLE状态的进程甚至无法被kill,在2.6.26之后的内核里面给变成TASK_WAKEKIILL|TAK_UNINTERTUPTIBLE这样就可以响应致命信号。
linux内核里面,使用task_struct结构体描述进程,结构体中包含描述进程的内存资源、文件系统资源、文件资源、TTY资源、信号处理等的指针,linux的线程采用轻量级进程模型来实现。用户用pthread_create()API创建线程的时候,本质就是内核创建一个新的task_struct,并将新的task_struct的所有资源指针都指向创建它的那个task_struct的资源指针。
在内核编程中,如果需要几个并发执行的任务,可以启动内核线程,这些线程没有用户空间,启动内核线程的函数为
pdd_t kernle_thread(int (*fn)(void*), void *arg, unsigned long flags)
- 内存管理
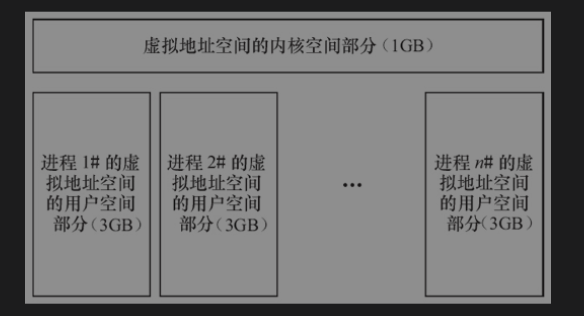
内存管理的主要作用是控制多个进程安全地共享主内存区域,当CPU提供内存管理单元(MMU)时,Linux内存管理对于每个进程完成从虚拟内存到物理内存转换。 kernel Features ->mempry split可以设置界限为2GB或者3GB。
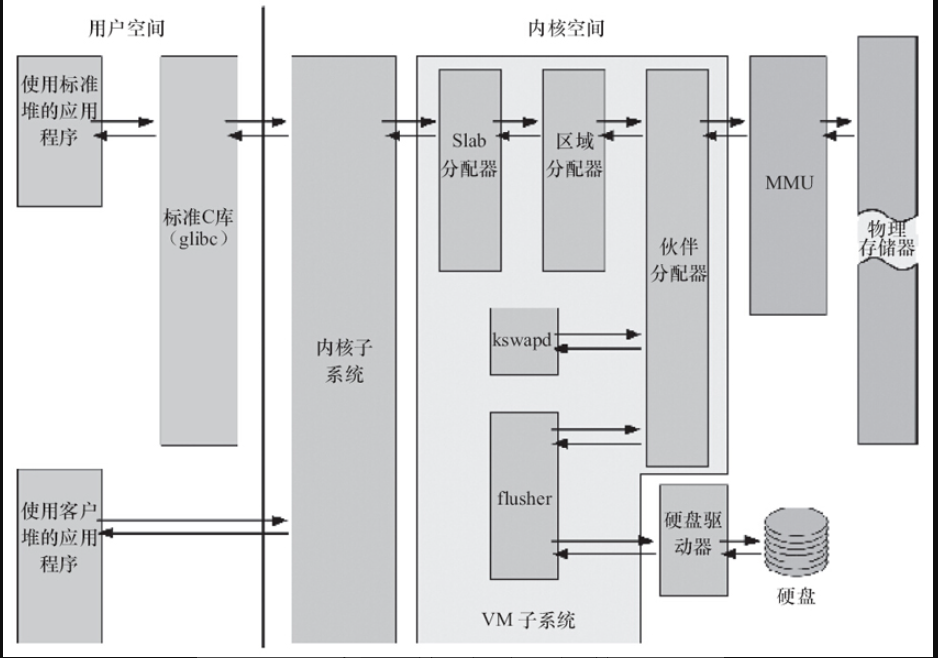
Linux内存管理:
BUddy算法,管理每个页的占用情况,内核空间的slab以及用户空间的c库的二次管理
此外内核提供了页缓存,通过内存缓存磁盘,per-BDI flusher线程用于刷回脏的页缓存到磁盘。Kswapd(交换进程)是LInux中用于页面回收(包括file-backed的页和匿名页)的内核线程,采用LRU算法进行内存回收。
- 虚拟文件系统
为上层应用程序提供了统一的vfs_read()和vfs_write()等接口,并调用具体底层文件系统或设备驱动中实现的file_operations结构体的成员函数。
- 网络接口
网络接口提供对各种网络标准的存取和各种网络硬件的支持。Linux里面网络接口可以分为网络协议和网络驱动程序。
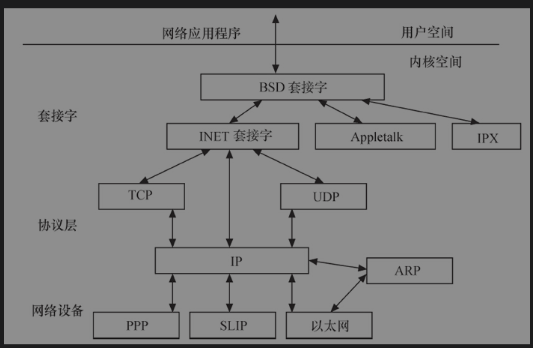
- 进程间的通信
包括的机制有信号量、共享内存、消息队列、管道、UNIX域套接字,在实际应用中更加偏向于用套接字[Android内核相较之下新增了Binder进程通信方式]
操作系统具有不同的操作模式,通常有7种工作模式:
- 用户模式(usr)
- 快速中断模式(fiq):用于高速数据传输或通道处理
- 外部中断模式(irq):用于通用的中断处理
- 管理模式(svc):操作系统使用的保护模式
- 数据访问中止模式(abt):当数据或指令预取中止时候进入该模式,可用于虚拟存储及存储保护
- 系统模式(sys):运行具有特权操作的操作系统任务
- 未定义指令中止模式(und):当未定义指令进入该模式的时候,用于支持硬件协处理器的软基仿真。
类似的X86有4个人不同的特权级,称为Ring0~Ring3。
#Linux内核的编译,首先需要配置内核
make config #文本界面
make menuconfig #基于文本的菜单界面
make xconfig #要求QT
make gconfig #要求GTK+
#为开发版配置内核
make ARCH=arm xx_dbgconfig
#编译方法是
make ARCH=arm zImage
make ARCh=arm modules内核引导:
SOC里面一般内嵌bootrom,上电时bootrom运行,bootrom引导bootloader,再引导linux内核,内核启动阶段cpu0发出中断唤醒cpu1,之后两个一起运行cpu0运行用户空间的Init程序,派生出新进程之后二者一起承担。
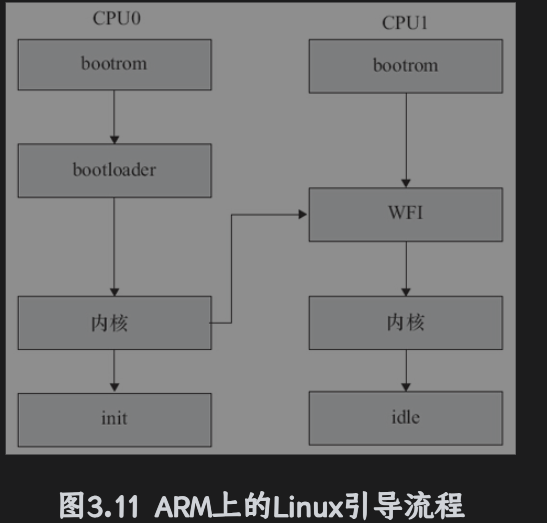
bootrom是Soc厂家写的,一般具有从eMMC、SD、NAND、USB等介质启动能力。
有名的bootloader就是U-BOOT,zImage类似的内核镜像是由没有压缩的解压算法和被压缩的内核组成,所以在bootloader跳入zImage之后,自身的解压逻辑就会压缩的内核镜像给解压出来。
用户空间的init程序常用的有busybox init 、SysVinit、systemd等,任务就是把系统启动最后形成一个进程树【pstree】
gnu-c
-ansi–pedantic :取消gnc扩展语法
- 零长度数组以及变长数组
- case 范围
- 语句表达式
- typeof关键字
- 可变参数宏
#define LOG(fmt, arg...) printf(fmt, ##arg)
#define LOG(fmt, ...) printf(fmt, ##__VA_ARGS__)标号元素
__ FUNCTION __
特殊属性声明
noreturn
format
unsed
section
aligned :内存对齐
pakced:尽可能最小内存
# define ATTRIB_NORET __attribute__((noreturn)) .... asmlinkage NORET_TYPE void do_exit(long error_code) ATTRIB_NORET; asmlinkage int printk(const char * fmt, ...) __attribute__ ((format (printf, 1, 2)));
- 内建函数
内核模块
lsmod:可以展示系统中已经加载的所有模块以及模块间的依赖关系(其实就是读取/proc/modules文件)
测试编译:
注
首次
- 安装依赖
sudo apt-get install build-essential linux-headers-$(uname -r)- 编译Makefile
obj-m := hello.o
KERNELDIR ?= /lib/modules/$(shell uname -r)/build
PWD := $(shell pwd)
all:
make -C $(KERNELDIR) M=$(PWD) modules
clean:
make -C $(KERNELDIR) M=$(PWD) clean- 编写源码
#include<linux/init.h>
#include<linux/module.h>
static int __init hello_init(void)
{
printk(KERN_INFO "HELLO woed enter \n");
return 0;
}
module_init(hello_init);
static void __exit hello_exit(void)
{
printk(KERN_INFO "hello world exit\n");
}
module_exit(hello_exit);
MODULE_AUTHOR("CHENLONG COPY");
MODULE_LICENSE("GPL");
MODULE_DESCRIPTION("HELLO MODULE");
MODULE_ALIAS("SIMPLE MODULE");- 加载模块
sudo insmod hello.ko
sudo dmesg | tail
lsmod |grep hello
cat /proc/modules
cd /sys/module/hello && tree -a #可以得到目录树
#加载模块还有modprobe,这个会自动去加载依赖模块,使用modprobe安装以 modprobe-r filename 就会同时卸载其依赖模块,模块间的依赖关系放置在根文件系统的/lib/modules/<kernel-veersion>/modules.dep这个文件是在整体内核编译的时候由depmod工具生成- 查询模块信息
modinfo modulename- 卸载模块
sudo rmmod hello
modprobe -r hello模块结构
- 模块加载函数:当通过insmod或modprobe命令加载内核模块
- 模块卸载函数:当使用rmmod卸载模块的时候,模块的卸载函数会自动被内核执行,完成与模块卸载相反的功能。
- 模块许可证声明:许可证(LICENSE)声明描述内核模块的许可权限,如果不声明LICENSE,模块加载的时候,将内核被污染(kernek Tainted)的警告。“GPL”、“GPL v2”、“GPL and additional rights”、“Dual BSD/GPL”、“Dual MPL/GPL”和“Proprietary”。
- 模块参数:模块参数是模块被加载的时候可以传递给它的值它本身对应模块内部的全局变量
- 模块导出符号:内核模块可以导出的符号(symbol,对于函数或变量),若导出,其他模块则可以使用本模块中的变量或函数。
加载函数
static int __init funcname(void)
{
/*初始化代码*/
}
module_init(funcname);
//正确返回0,错误但会接近于0的负数,-ENODEV,-ENOMEN之类的符号值。
//linux内核中,可以使用request_module(const char *fmt, ...)函数加载内存模块
request_module(module_name);
//如果表示__init的函数直接编译进入内核,成为镜像的一部分,在连接的时候会放在.init.text区段
#define __init __attribute__((__section__(".init.text")))\卸载函数
static void __exit cleanup_function(void)
{
/*释放代码*/
}
module_exit(clean_function);
//__exit修饰告诉内核如果相关的模块被直接编译进内核,那么clean_function()函数会被省略,直接不连接最后的镜像,模块参数
module_param(参数名, 参数类型);
static char *book_name = "dissecting Linux Device Driver";
module_param(book_name, charp, S_IRUGO);
static int book_num = 4000;
moudle_param(book_num, int, S_IRUGO);装载内核模块时,用户可以向模块传递参数insmode 模块名=参数名=参数值。如果模块被内置,就不能insmod,但是bootloader可以通过在bootargs里设置的“模块名.参数名=值”的形式给内置的模块传递参数。
模块记载之后会在/sys/module/目录下面出现以此模块名命名的目录。当读写权限设置为0,表示此参数不存在sysfs文件系统下对应的文件节点,如果此模块存在不为0的命令行参数,在此模块下将出现parameters目录,其中包含一系列以参数名命名的文件节点,这些文件的权限值就是传输module_param()的权限,文件内容就是参数值
#include <linux/init.h>
#include <linux/module.h>
static char *book_name = "name";
module_param(book_name, charp , S_IRUGO);
static int book_num = 400;
module_param(book_num, int, S_IRUGO);
static int __init book_init(void)
{
printk(KERN_INFO "book_name%s\n", book_name);
printk(KERN_INFO "book_num%d\n", book_num);
return 0;
}
module_init(book_init);
static void __exit book_exit(void)
{
printk(KERN_INFO "BOOK_MOUDLE exit\n");
}
module_exit(book_exit);
MODULE_AUTHOR("ChenLong");
MODULE_LICENSE("GPL v2");
MODULE_DESCRIPTION("A simple Module for testing module params");
MODULE_VERSION("V1.0");导出符号
在linux的/proc/kallsyms文件对应着内核符号表,记录了符号以及符号所在的内存地址。
模块可以使用
EXPORT_SYMBOL(符号名)、EXPORT_SYMBOL_GPL(符号名)
导出的符号名可以被其他模块使用,但是需要提前声明一下,EXPORT_SYMBOL_GPL()适用于包含GPL许可权的模块。
#include <linux/init.h>
#include <linux/module.h>
int add_integar(int a, int b)
{
return a + b;
}
EXPORT_SYMBOL_GPL(add_integar);
int sub_integar(int a, int b)
{
return a - b;
}
EXPORT_SYMBOL_GPL(sub_integar);
MODULE_LICENSE("GPL v2");grep integar /proc/kallsyms
#打印如下
# grep integar /proc/kallsyms
e679402c r __ksymtab_sub_integar [export_symb]
e679403c r __kstrtab_sub_integar [export_symb]
e6794038 r __kcrctab_sub_integar [export_symb]
e6794024 r __ksymtab_add_integar [export_symb]
e6794048 r __kstrtab_add_integar [export_symb]
e6794034 r __kcrctab_add_integar [export_symb]
e6793000 t add_integar [export_symb]
e6793010 t sub_integar [export_symb]模块声明及描述
MODULE_AUTHOR(author);// 作者
MODULE_DESCRIPTION(description);// 描述
MODULE_VERSION(version_string);// 版本
MODULE_DEVICE_TABLE(table_info);// 设备表
MODULE_ALIAS(alternate_name);// 别名像USB、PCI等设备驱动通常会创建一个MODULE_DEVICE_TABLE,表明该驱动模块所支持的设备。
static struct usb_device_id skel_table [] = {
{
USB_DEVICE(USB_SKEL_VENDOR_ID,
USB_SKEL_PRODUCT_ID)},
{}
};
MODULE_DEVICE_TABLE (usb, skel_table);模块的计数
2.6内核的Linux后,内核提供了模块技术管理接口,取代2.4的宏
int try_module_get(strcut module *module)—用于增加模块使用计数,返回0说明调用失败。
void module_put(struct module *module)--用于减少模块使用计数
编译
# 获取当前内核版本
KVERS = $(shell uname -r)
# 指定模块名称 (从 hello.c 编译)
obj-m += hello.o
# 可选的调试编译标志
# EXTRA_CFLAGS = -g -O0
# 声明伪目标(避免与文件名冲突)
.PHONY: all clean
# 默认目标
all: modules
# 核心构建规则
modules:
$(MAKE) -C /lib/modules/$(KVERS)/build M=$(CURDIR) modules
# 清理规则
clean:
$(MAKE) -C /lib/modules/$(KVERS)/build M=$(CURDIR) clean文件
系统调用
创建
int creat(const char *filename, mode_t mode);
//创建一个文件,mode规定其存取权限,与umask一道决定最终权限(mode&umask)
int umask(int newmask);//可以修改umask打开
int open(const char *path, int flasgs);
int open(const char *path, int flags, ,mode_t mode);
//打开指定路径的文件,其中flag是文件打开标志,如果是创建文件,要用第二种api给予文件访问权限标志:
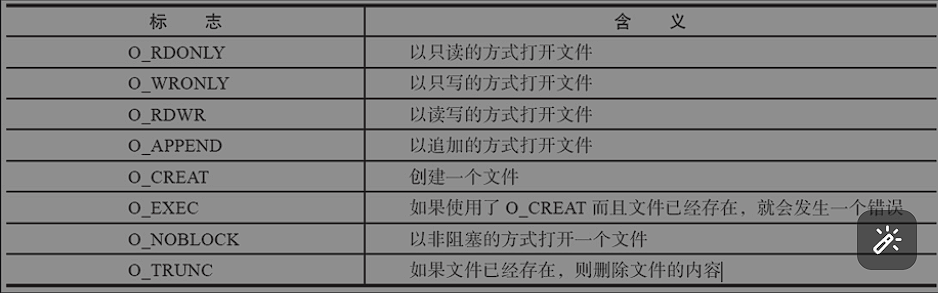
文件访问权限:
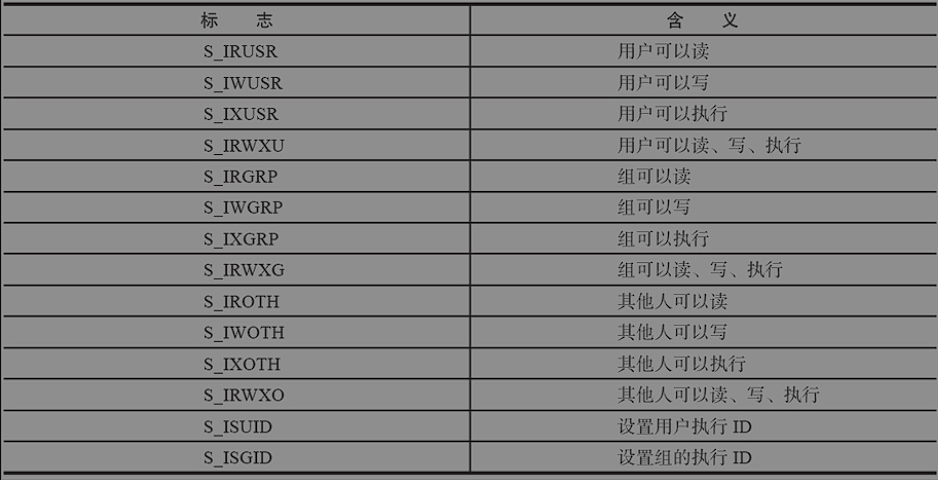
文件访问权限可以通过数字的方式赋予,依次分别表示用户ID,组ID,用户权限,组权限,其他人权限。
打开成功会返回一个文件描述符。
读写
int read(int fd, const void *buf, size_t len);
int write(int fd, const void *buf, size_t len);定位
int lseek(int fd, offset_t offest, int whence);
//SEEK_SET:相对于文件开头
//SEEK_CUR:相对于现在指针位置
//SEEK_END:相对于文件末尾
lseek(fd, 0, SEEK_END);//表示文件的字节数。关闭
int close(int fd);c库中文件操作
file *fopen(const char *path, const char *mode);
读写
读写支持以字符、字符串为单位:
int fgetc(filE *stream);
int fputc(int c, fileE *stream);
char *fgets(char *s, int n, filE *stream);
int fputs(const cahr *s, filE *stream);
int fprintf(filE *stream, const char *format, ....);
int fscanf(filE *stream, const char *format, ...);
size_t fread(void *ptr, size_t size, size_t n, filE *stream);
size_t fwrite(const void *ptr, size_t size, size_t n, filE *stream);fread()实现从stream里面读取n个字段,每个字段是size个字节,将读取的字段保存到字符数组中,返回已经读取的字段数,当读取的字段小于num,可能在函数调用的时候出现错误,也可能是读到了文件的末尾,因此要通过feof()和ferror()来判断。
write()实现从缓冲区ptr所指的数组把n个字段写到stream中,每个字段长size字节,但会写入的字段数。
相似的c库也提供了定位的能力,这些函数包括:
int fgetpos(filE *stream, fpst_t *pos);
int fsetpos(filE *stream, const fpos_t *pos);
int fseek(filE *stream, long offset, int whence);关闭
int fclose(filE *stream);文件系统
目录结构
在linux下面的目录结构里面
- /bin:包含一些基本的命令
- /sbin:包含系统命令
- /dev:设备文件存储目录,通过对这些文件的读写和控制来访问实际的设备
- /etc:系统配置文件所在,一些服务器的配置文件也在这里(busybox的启动脚本也在这里)
- /lib:系统库文件存放目录等
- /mnt:存放挂载设备的挂载目录
- /opt:有些安装包的安装位置
- /proc:操作系统运行时,进程以及内核信息存放处。/proc目录是伪文件系统proc的挂载目录
- /tmp:临时文件存放处
- /usr:系统存放程序目录,用户命令以及用户库等
- /var:存放一些经常变动的东西比如/vat/log
- /sys:Linux2.6内核所支持的sysfs文件系统将被映射到此目录上。
LInux文件系统以及设备驱动
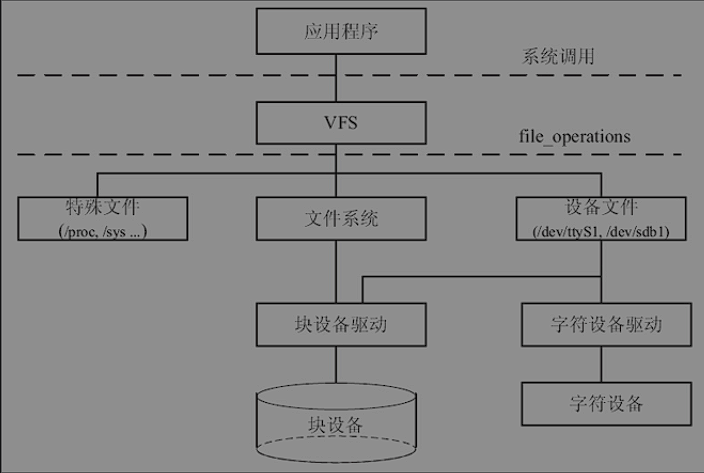
而VFS与文件系统以及设备之间的接口file_operations结构体成员函数。结构体包含对文件进行打开、关闭、读写、控制的一系列成员函数。
字符设备的上层没有类似于磁盘的ext2等文件系统,所以字符设备的file_operations成员函数就直接由设备驱动提供。
块设备有两种访问方法,一种方法是不通过文件系统直接访问裸设备,另一种方法是通过文件系统访问块设备,文件系统会把针对文件的读写转换为针对块设备原始扇区的读写。
设备驱动程序的设计,关心file和inode结构体。
file结构体
strcut file {
union {
struct llist_node fu_llist;
struct rcu_head fu_rcuhead;
}f_u;
struct path f_path;
#define f_dentry f_path.dentry
struct inode *f_inode;
const struct file_operations *f_op;
spinlock_t f_lock;
atomic_long_t f_count;
unsigned int f_flags;
fmode_t f_mode;
struct mutex f_pos_lock;
loff_t f_pos;
struct fown_struct f_owner;
const struct cred *f_crred;
struct file_ra_statef_ra;
u64 f_version;
#ifdef CONFIG_SECURITY
void*f_security;
#endif
void *private_data;
#ifdef CONFIG_EPOLL
struct list_head f_ep_links;
struct list_head f_tfile_llink;
#endif
struct address_space *f_mapping;
} __attribute__((aligned(4)))inode
它是Linux管理文件系统的最基本单位,也是文件系统链接任何子目录、文件的桥梁
struct inode {
...
umode_t i_mode; //inode权限
uid_t i_uid; //拥有者id
gid_t i_gid; //所属群组id
dev_t i_rdev; //如果是设备文件,这个记录设备的设备号
loff_t i_size; //代表文件大小
struct timespec i_atime; //最后一次存取的时间
struct timespec i_mtime; //最近一次修改的时间
struct timespec i_ctime; //inode产生时间
unsigned int i_blkbits;
blkcnt_t i_blocks;
union {
struct pipe_inode_info *i_pipe;
struct block_device *i_bdev;
struct cdev *i_cdev;
}
...
};I_rdev表示设备文件的inode结构,i_rdev字段包含设备编号,Linux内核设备编号分为主设备编号和次设备编号,前者为dev_t 的高12位,后者位dev_t 的低20位。
unsigned int iminjor(struct inode *inode);
unsigned int imajor(struct inode *inode);通过查看proc/device文件就可以获知系统中注册的设备,第一列为主设备号,第二列为设备号。
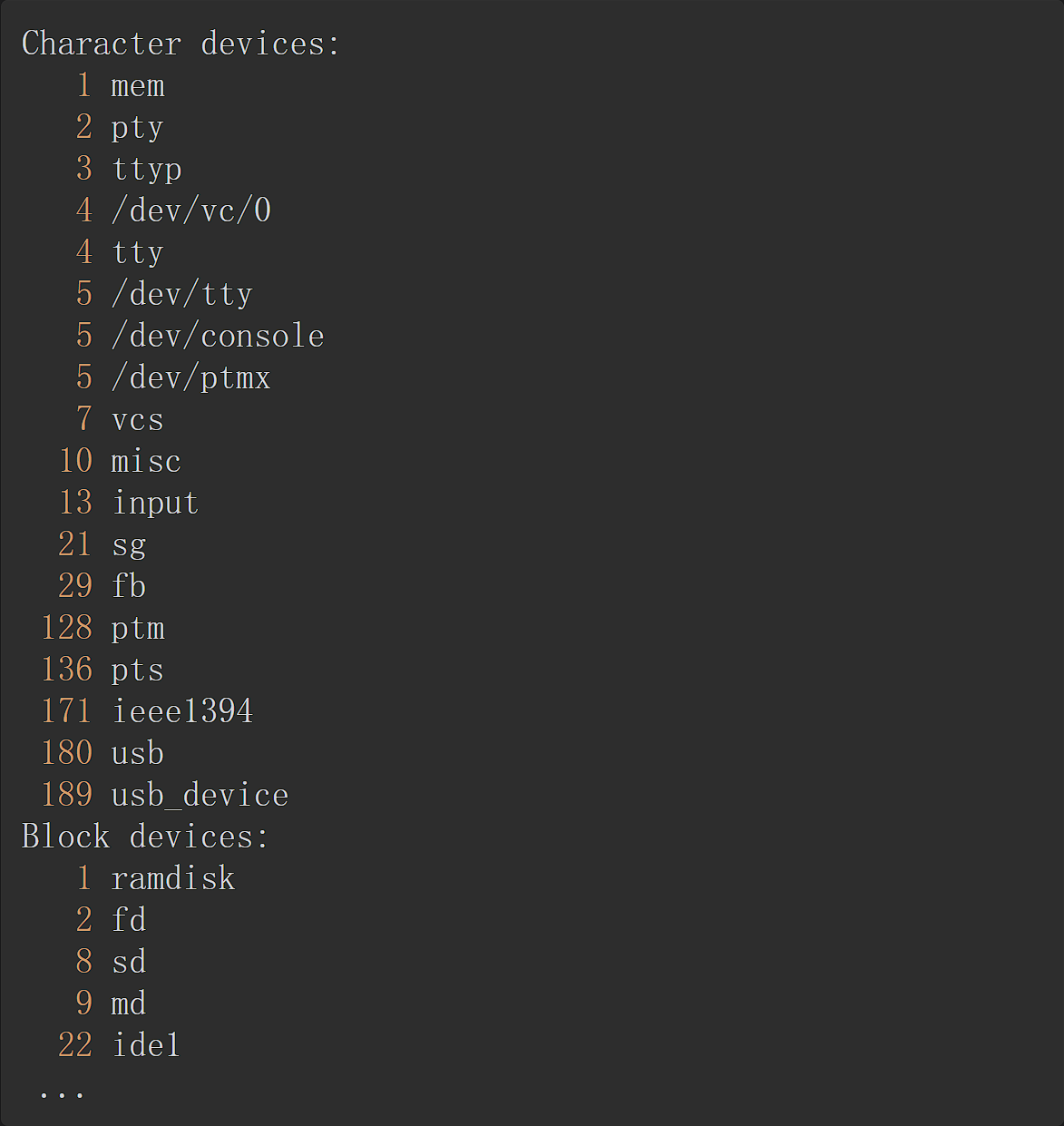
查看/dev可以获得系统中包含的设备文件,日期的前两列给出了对应设备的主设备号和次设备号。主设备号对应驱动级,一类设备一般采用相同的主设备号,不同的设备一般使用不同的主设备号。同一驱动可能支持多列设备,因此用次设备号来描述使用该驱动的设备的序号,一般从0开始。
devfs
devfs(设备文件系统)是Linux2.4内核引入。
devfs具有如下优点:
- 可以通过程序在设备初始化时在
/dev目录下创建设备文件,卸载设备的时候会将它删除。 - 设备驱动程序可以指定设备名、所有者和权限位,用户空间程序仍可以修改所有者和权限位。
- 不再需要为设备驱动程序分配主设备号以及处理次设备号,在程序中可以直接在register_chredv()传递0主设备号以获得可用的主设备号,并在devfs_register()中指定次设备号。
//创建设备目录
devfs_handle_t devfs_mk_dir(devfs_handle_t dir, const char *name, void *info);
//创建设备文件
devfs_handle_t devfs_register(devfs_handles_t dir, const char *name, unsigned int flags, unsigned int major, unsigned int minor, umode_t mode, void *ops, void *info);
//撤销设备文件
void devfs_unregister(devfs_handle_t de);udev用户空间设备管理
sysfs文件系统与Linux设备模型
sysfs文件系统是LInux2.6之后引入,看作是proc、devfs和devpty同类别文件系统,与proc文件系统非常相似。其最上层目录有block、bus、devices、class、fs、kernel、powe、firmware等。
- block:块设备
- devices:系统所有设备,根据设备挂接总线类型组织成层次结构
- bus:包含所有总线类型
- class:包含系统设备类型
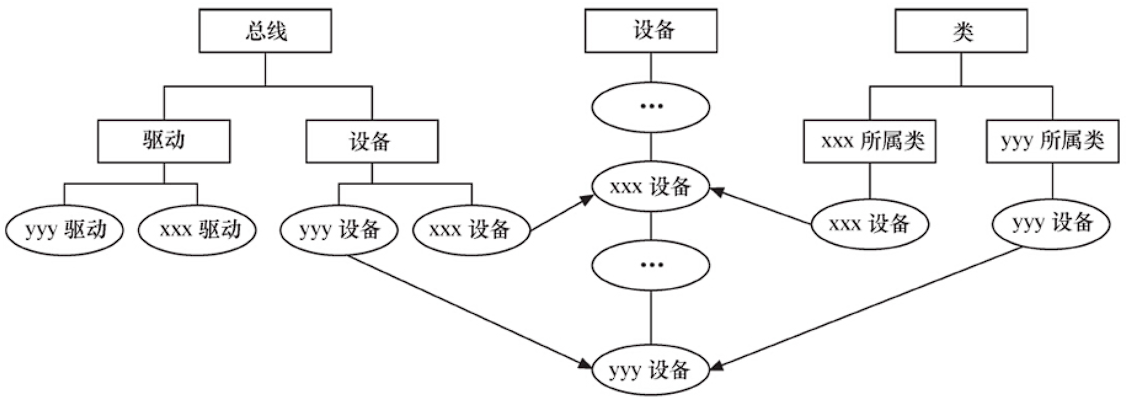
在Linux内核中,分别使用bus_type、device_driver、device描述总线、驱动和设备。
struct bus_type {
const char *name;
const char *dev_name;
struct device *dev_root;
struct device_attribute *dev_attrs; /* use dev_groups instead */
const struct attribute_group **bus_groups;
const struct attribute_group **dev_groups;
const struct attribute_group **drv_groups;
int (*match)(struct device *dev, struct device_driver *drv);
int (*uevent)(struct device *dev, struct kobj_uevent_env *env);
int (*probe)(struct device *dev);
int (*remove)(struct device *dev);
void (*shutdown)(struct device *dev);
int (*online)(struct device *dev);
int (*offline)(struct device *dev);
int (*suspend)(struct device *dev, pm_message_t state);
int (*resume)(struct device *dev);
const struct dev_pm_ops *pm;
struct iommu_ops *iommu_ops;
struct subsys_private *p;
struct lock_class_key lock_key;
};struct device_driver {
const char *name;
struct bus_type *bus;
struct module *owner;
const char *mod_name; /* used for built-in modules */
bool suppress_bind_attrs; /* disables bind/unbind via sysfs */
const struct of_device_id *of_match_table;
const struct acpi_device_id *acpi_match_table;
int (*probe) (struct device *dev);
int (*remove) (struct device *dev);
void (*shutdown) (struct device *dev);
int (*suspend) (struct device *dev, pm_message_t state);
int (*resume) (struct device *dev);
const struct attribute_group **groups;
const struct dev_pm_ops *pm;
struct driver_private *p;
};struct device {
struct device *parent;
struct device_private *p;
struct kobject kobj;
const char *init_name; /* initial name of the device */
const struct device_type *type;
struct mutex mutex; /* mutex to synchronize calls to
* its driver.
*/
struct bus_type *bus; /* type of bus device is on */
struct device_driver *driver; /* which driver has allocated this
device */
void *platform_data; /* Platform specific data, device
core doesn't touch it */
struct dev_pm_infopower;
struct dev_pm_domain*pm_domain;
#ifdef CONfiG_PINCTRL
struct dev_pin_info*pins;
#endif
#ifdef CONfiG_NUMA
int numa_node; /* NUMA node this device is close to */
#endif
u64 *dma_mask; /* dma mask (if dma'able device) */
u64 coherent_dma_mask; /* Like dma_mask, but for
alloc_coherent mappings as
not all hardware supports
64 bit addresses for consistent
allocations such descriptors. */
struct device_dma_parameters *dma_parms;
struct list_head dma_pools; /* dma pools (if dma'ble) */
struct dma_coherent_mem *dma_mem; /* internal for coherent mem
override */
#ifdef CONfiG_DMA_CMA
struct cma *cma_area; /* contiguous memory area for dma
allocations */
#endif
/* arch specific additions */
struct dev_archdataarchdata;
struct device_node *of_node; /* associated device tree node */
struct acpi_dev_node acpi_node; /* associated ACPI device node */
dev_t devt; /* dev_t, creates the sysfs "dev" */
u32 id; /* device instance */
spinlock_t devres_lock;
struct list_head devres_head;
struct klist_node knode_class;
struct class *class;
const struct attribute_group **groups; /* optional groups */
void(*release)(struct device *dev);
struct iommu_group *iommu_group;
boo offline_disabled:1;
boo offline:1;
};驱动和设备分别注册,当注册之后会匹配相应的驱动(match函数),匹配成功之后会调用xxx_driver的peobe()函数。
总线、设备和驱动中的各个attribute会直接运行创建各个文件,在过程中伴随show()和store()函数的调用,分别用于读写attribute对应的sysfs文件。
注
udev工作过程
内核检测到系统中出现新设备后,内核会通过netlink套接字发送uevent。
udev获取内核发送的信息,进行规则匹配,匹配包括SUBSYSTEM、ACTION、attribute、内核提供名称等
一些工具:
udevadm info工具查找规则文件能利用的内核信息以及sysfs属性信息
udevadm info -a -p
udevadm info -a-p$ (udevadm info-q path-n/dev/<节点名>)反向分析
字符设备驱动
Linux字符设备驱动结构
cdev结构体
struct cdev {
struct kobject kobj;//内嵌的kobject
struct module *owner;//所属模块
struct file_operations *ops;//文件操作结构体
struct list_head list;
dev_t dev; //设备号
unsigned int count;
};
MAJOR(dev_t dev)
MINOR(dev_t dev)
MKDEV(int major, int minor)Linux内核提供一组函数用于操作cdev结构体:
void cdev_init(struct cdev *, struct file_operations *);
struct cdev *cdev_alloc(void);
void cdev_put(struct cdev *p);
int cdev_add(struct cdev *, dev_t, unsigned);
void cdev_del(struct cdev *);cdev_init()函数用于初始化cdev的成员,并建立cdev和file_operations之间的连接。
void cdev_init(struct cdev *cdev, struct file_operations *fops)
{
memset(cdev, 0, sizeof(*cdev));
INIT_LIST_HEAD(&cdev->list);
kobject_init(&cdev->kobj, &ktype_cdev_default);
cdev->ops = fops; //将传入的文件操作结构体指针赋值给cdev的ops
}cdev_alloc()函数用于动态申请一个cdev内存。
struct cdev *cdev_alloc(void)
{
struct cdev *p = kzalloc(sizeof(struct cdev), GFP_KERNEL);
if (p) {
INIT_LIST_HEAD(&p->list);
kobject_init(&p->kobj, &ktype_cdev_dynamic);
}
return p;
}cdev_add()函数和cdev_del()函数分别向系统和删除一个cdev,完成字符设备的注册和注销。
register_chrdev_region()或alloc_chrdev_region()应该再cdev_add()之前。
int register_chrdev_region(dev_t from, unsigned count, const char *name);//已知起始设备的设备号的情况
int alloc_chrdev_region(dev_t *dev, unsigned baseminor, unsigned count, const char *name);//向系统动态设备申请未被占用的设备号的情况,函数调用成功之后,会把得到的设备号放入第一个参数dev中。cdev_del()函数从设备注销字符设备之后,unregister_chrdev_region()应该被调用从释放原先申请的设备号。
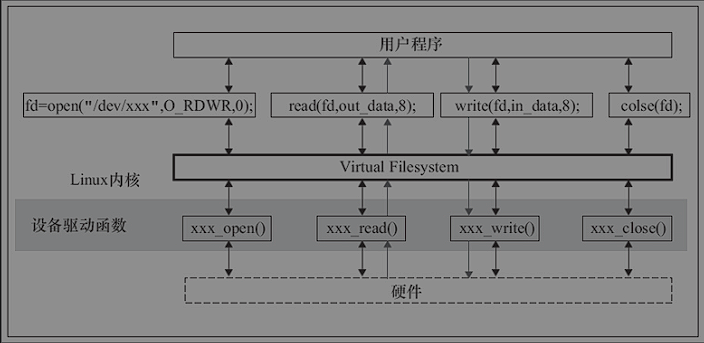
void unregister_chrdev_region(dev_t from, unsigned count);file_operations结构体的成员函数是字符设备驱动程序设计的主体内容,这些函数实际会在应用程序进行Linux的open()、write()、read()、close()等系统调用。
struct file_operations {
struct module *owner;
loff_t (*llseek) (struct file *, loff_t, int);
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
ssize_t (*write)(struct file *, const char __user *, size_t, loff_t *);
ssize_t (*aio_read)(struct kiocb *, const struct iovec *, unsigned long, loff_t);
ssize_t (*aio_write)(struct kiocb *, const struct iovec *, unsigned long, loff_t);
int (*iterate)(struct file *, struct dir_context *);
unsigned int (*poll)
}llseek()函数用于修改一个文件的当前读写位置,并将新位置返回,在出错时,这个函数返回一个负值。
read()函数用于从设备中读取数据,成功时函数返回读取的字节数,出错返回负值。
unlocked_ioctl()提供设备相关控制命令的实现,当调用成功时。
unsigned long copy_from_user(void *to, const void _ _user *from, unsigned long count);
unsigned long copy_to_user(void _ _user *to, const void *from, unsigned long count);
//__user这个是一个宏
#ifdef _ _CHECKER_ _
# define _ _user _ _attribute_ _((noderef, address_space(1)))
#else
# define _ _user
#endif
//__user是指的是这个指针无法指针无法直接访问,address_space(1)表示的用户空间
//内核空间访问用户空间的缓冲区,一般要提前进行合法性检查access_ok (type, addr, size);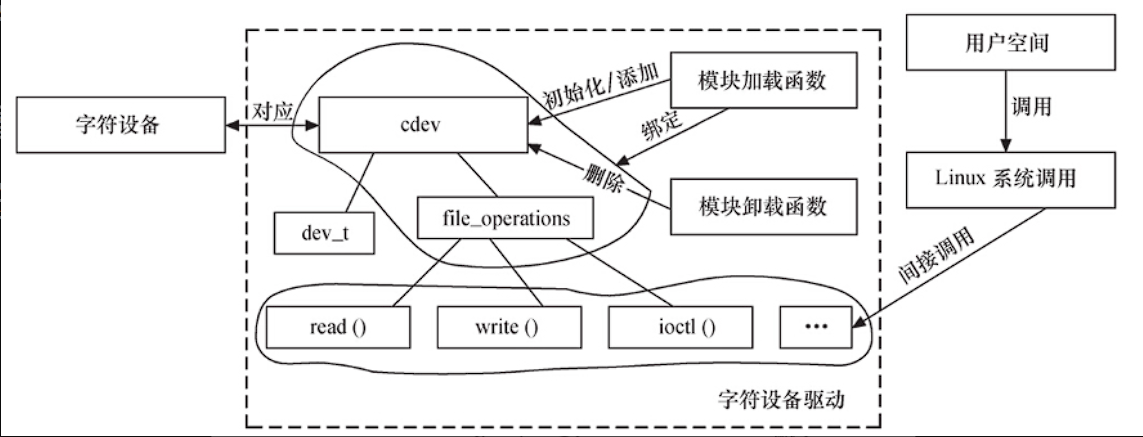
globalmem虚拟设备实例
globalmem意味全局,在globalmem字符设备驱动中会分配一片大小为GLOBALMEM_SIZE的内存空间,并在驱动中提供针对该片内存的相关函数。
static void globalmem_setup_cdev(struct globalmem_dev *dev, int index)
{
int err, devno = MKDEV(globalmem_major, index);
cdev_init(&dev->cdev, &globalmem_fops);
dev->cdev.owner = THIS_MODULE;
err = cdev_add(&dev->cdev, devno, 1);
if (err)
printk(KERN_NOTICE "Error %d adding globalmem%d", err, index);
}
static int __init globalmem_init(void)
{
int ret;
dev_t devno = MKDEV(globalmem_major, 0);
if (globalmem_major)
ret = register_chrdev_region(devno, 1, "globalmem");
else {
ret = alloc_chrdev_region(&devno, 0, 1, "globalmem");
globalmem_major = MAJOR(devno);
}
if (ret < 0)
return ret;
globalmem_devp = kzalloc(sizeof(struct globalmem_dev), GFP_KERNEL);
if (!globalmem_devp) {
ret = -ENOMEM;
goto fail_malloc;
}
globalmem_setup_cdev(globalmem_devp, 0);
return 0;
fail_malloc:
unregister_chrdev_region(devno, 1);
return ret;
}
module_init(globalmem_init);详细实例过程见书
ioctl()命令

设备类型是幻数,新设备驱动定义幻数要避免和内核的ioctl-number.txt中给出的推荐的和已被使用的幻数冲突。
命令码的序列号也是八位宽,命令码的方向字段表示数据传输的方向:可能是_IOC _NONE(无数据传输)、 _IOC _READ(读取)、 _ IOC_WRITE(写)和 _ IOC_READ| _ IOC _WRITE _
内核还定义了_io() _IOR() _IOW() _IOWR()等宏辅助生成。
LInux设备的并发管理
并发和竞态
SMP是一种紧耦合、共享存储的系统模型,多CPU使用共同的系统总线。在SMP下,CPU间的竞态可能发生于CPU的进程之间、中断之间或者中断和进程之间
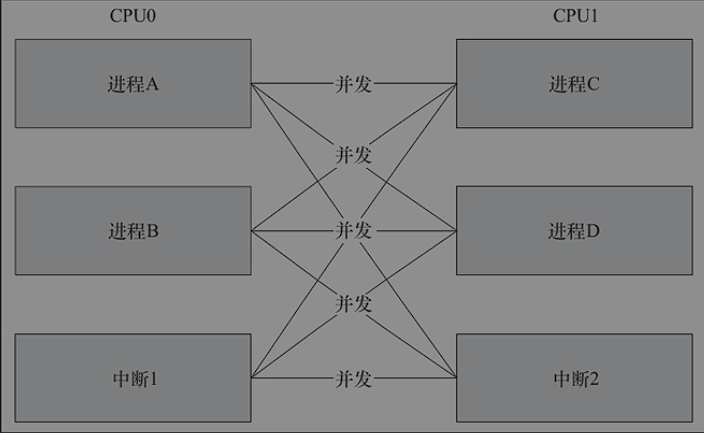
还有一个进程被另一个进程抢占,抢占的进程访问了访问了同一个共享资源。
中断和进程之间也有竞态的可能,中断之间也有竞态的可能。
访问共享资源的代码区域叫做临界区,临界区需要用某种互斥机制保护以避免竞态(中断屏蔽、原子操作、自旋锁、信号量、互斥体等)
编译乱序和执行乱序
编译器会优化编译的顺序以提高运行的效率,但是有时可能会产生乱序编译的情况,如果要确保程序的编译顺序需要加上编译屏障
barrie()屏障
int main(int argc, char *argv[])
{
int a = 0, b, c, d[4096], e;
e = d[4095];
b = a;
c = a;
printf("a:%d b:%d c:%d e:%d\n", a, b, c, e);
return 0;
}
//以上代码编译的时候可能就会发生编译顺序与源码不一致的情况
#define barrier() __asm__ __volatile__("": : :"memory")
int main(int argc, char *argv[])
{
int a = 0, b, c, d[4096], e;
e = d[4095];
barrier();
b = a;
c = a;
printf("a:%d b:%d c:%d e:%d\n", a, b, c, e);
return 0;
}
//以上代码就可以避免编译顺序问题
//volatile作用很弱,并不具有保护临界资源的作用在处理号编译乱序之后,处理器在运行过程中会有执行乱序的情况发生,高级的cpu可以根据缓存的组织特性,将访存指令重新排序执行。就引入了内存屏障的情况
//cpu1
while (f == 0) {
print x;
}
//cpu2
x = 31;
f = 1;
//尽管x先声明当while进去的时候,x的值不一定是31。注
DMB:数据内存屏障
在DMB之后的显式内存访问执行之前,保证DMB指令前面所有内存访问都已经完成
DSB:数据同步屏障
等待所有在DSB之前的指令完成(包括缓存、跳转预测、TLB维护操作全部完成)
ISB:指令同步屏障
Flush流水线,使得所有ISB之后指令都是从缓存或者内存中获得
LOCKED EQU 1
UNLOCKED EQU 0
lock_mutex
; 互斥量是否锁定?
LDREX r1, [r0] ; 检查是否锁定
CMP r1, #LOCKED ; 和"locked"比较
WFEEQ ; 互斥量已经锁定,进入休眠
BEQ lock_mutex ; 被唤醒,重新检查互斥量是否锁定
; 尝试锁定互斥量
MOV r1, #LOCKED
STREX r2, r1, [r0] ; 尝试锁定
CMP r2, #0x0 ; 检查STR指令是否完成
BNE lock_mutex ; 如果失败,重试
DMB ; 进入被保护的资源前需要隔离,保证互斥量已经被更新
BX lr
unlock_mutex
DMB ; 保证资源的访问已经结束
MOV r1, #UNLOCKED ; 向锁定域写"unlocked"
STR r1, [r0]
DSB ; 保证在CPU唤醒前完成互斥量状态更新
SEV ; 像其他CPU发送事件,唤醒任何等待事件的CPU
BX lr内核里面有读写屏障(mb)、读屏障(rmb)、写屏障(wmb)、用于寄存器读写的__ iormb()、__iowmb等API。读写寄存器的readl_relaxed()和readl()、writel_relaxed()和writel()API的区别就体现在有无屏障方面。
中断屏蔽
再单CPU环境,使用中断屏蔽可以有效避免竞态,但是不推荐。
local_irq_disable()// 关中断
..
critical section //临界区
..
local_irq_enable()//开中断
static inline void arch_local_irq_disable(void)
{
asm volatile(
" cpsid i @ arch_local_irq_disable"
:
:
: "memory", "cc");
}//arm 里面底层就是让CPU本身不响应中断,比如,对于ARM处理器而言,其底层实现是屏蔽ARM CPSR的I位对于中断的屏蔽可能导致一系列的问题,所以中断暂停后的临界区需要尽可能小。
原子操作
Linux提供了一系列函数实现内核的原子操作,这些函数分为两类,分别针对位和整形变量进行原子操作。对于ARM处理器而言,底层使用LDREX和STREX指令,比如atomic_inc()底层的使用会调用atomic_add()。
整形:
- 设置原子变量值
void atomic_set(atomic_t *v, int i);
atomic_t v = ATOMIC_INIT(0);- 获取原子变量的值
void atomic_read(atomic_t *v);- 原子变量加、减
void atomic_add(int i, atomic_t *v);
void atomic_sub(int i, atomic_t *v);- 自增、自减
void atomic_inc(atomic_t *v);
void atomic_dec(atomic_t *v);- 测试加减是否为零
int atomic_inc_and_test(atomic_t *v);
int atomic_dec_and_test(atomic_t *v);
int atomic_sub_and_test(int i, atomic_t *v);
//这三个函数不会真正加减,而是在测试加减之后是否是0- 操作并返回新值
int atomic_add_return(int i, atomic_t *v);
int atomic_sub_return(int i, atomic_t *v);
int atomic_inc_return(atomic_t* v);
int atomic_dec_return(atomic_t *v);位原子操作:
- 设置位
void set_bit(nr, void *addr);- 清除位
void clear_bit(nr, void *addr);- 改变位
void change_bit(nr, void *addr);//对nr位反置- 测试位
test_bit(nr, void *addr);自旋锁
spin lock ,为了获得一个自旋锁,在某CPU上运行的代码需先执行一个原子操作,该操作测试并设置某个内存变量。若测试结果这个锁是空闲,那么程序获得这个自旋锁并继续执行,如果没有,那么将重复测试知道获取锁。
spinlock_t lock;
spin_lock_init(lock);
spin_lock(lock);
spin_trylock(lock);
spin_unlock(lock);spin lock主要针对SMP或单CPU但内核可抢占的情况,对于单CPU和内核不支持抢占的系统,自旋锁会退化为空操作。单CPU和内核可抢占的系统中,自旋锁持有期间中内核的抢占被禁止。多核SMP的情况下,任何一个核拿到自旋锁,该核上的抢占调度也暂时禁止,但是没有禁止另一个核的抢占调度。自旋锁可以保证临界区不受别的CPU和本CPU的抢占进程打扰,但是得到锁代码路径在执行临界区的时候,可能受到中断和底半部的影响。
为了解决上面的影响,需要用到自旋锁的衍生:
local_irq_disable() //关中断
local_irq_enable()// 开中断
local_bh_disable()// 关底半部
local_bh_denable()// 开底半部
local_irq_save()// 关中断并保存状态自
local_ieq_restore()// 开中断并恢复状态字由以上衍生:
spin_lock_irq() = spin_lock() + local_irq_disable()
spin_unlock_irq() = spin_unlock() + local_irq_enable()
spin_lock_irqsave() = spin_lock() + local_irq_save()
spin_unlock_irqrestore() = spin_unlock() + local_irq_restore()
spin_lock_bh() = spin_lock() + local_bh_disable()
spin_unlock_bh() = spin_unlock() + local_bh_enable()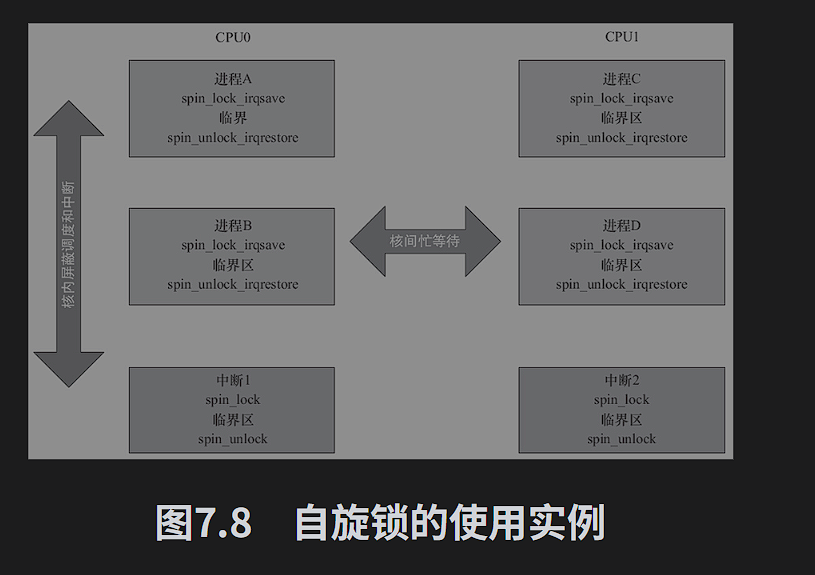
多核编程里面,进程上下文调用spin_lcok_irqsave等,在中断上下文调用spin_lock等,这样CPU0,无论是上下文还是中断获得了自旋锁,此后其他CPU必须要等待。
由于SPIN LOCK是一个忙等锁,当锁不能用时,一直循环等待锁,当临界区大时或者有共享设备的情况,需要较长时间的占用锁,会降低系统的性能。
自旋锁可能导致系统死锁,即是在递归使用自旋锁的时候。
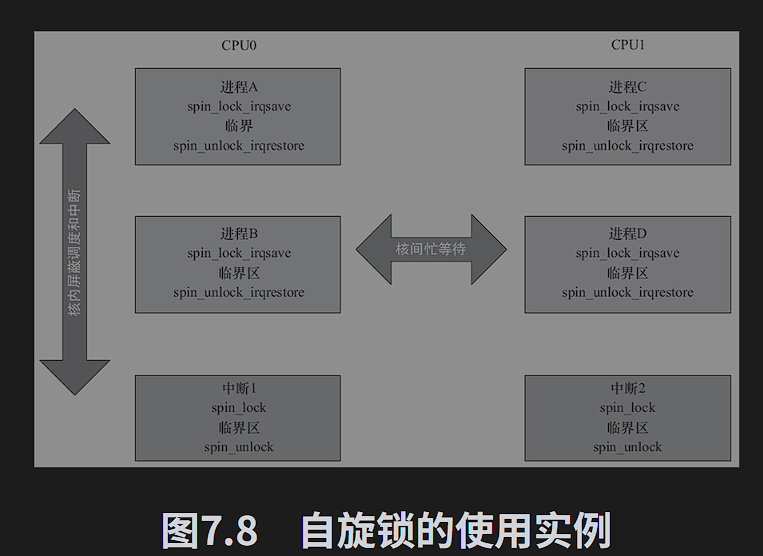
自旋锁锁定期间不能调用可能引起进程调度的函数,如果进程获得自旋锁之后再阻塞,如调用copy_from_user()、copy_to_user()、kmalloc()和msleep()等函数,可能导致内核崩溃。
无论是单核还是多核编程都不应该在中断中调用spin_lock()
读写自旋锁
读写自旋锁是一种粒度更细的锁,保留了自旋的概念,但是再写时,只有一个进程可以写,先写后读,以写进程优先级更高。
初始化
rwlock_t my_rwlock;
rwlock_init(my_rwlock);读锁定
void read_lock(rwlock_t *lock);
void read_lock_irqsave(rwlock_t *lock, unsigned long flags);
void read_lock_irq(rwlock_t *lock);
void read_lock_bin(rwlock_t *lock);读解锁
void read_unlock(rwlock_t *lock);
void read_unlock_irqrestore(rwlock_t *lock, unsigned long flags);
void read_unlock_irq(rwlock_t *lock);
void read_unlock_bh(rwlock_t *lock);在正式读取之前,应该先调用读锁定函数,完成之后应该调用读解锁函数。
写锁定
void write_lock(rwlock_t *lock);
void write_lock_irqsave(rwlock_t *lock, unsigned long flags);
void write_lock_irq(rwlock_t *lock);
void write_lock_bh(rwlock_t *lock);
int write_trylock(rwlock_t *lock);写解锁
void write_unlock(rwlock_t *lock);
void write_unlock_irqrestore(rwlock_t *lock, unsigned long flags);
void write_unlock_irq(rwlock_t *lock);
void write_unlock_bh(rwlock_t *lock);使用用例
rwlock_t lock; /* 定义rwlock */
rwlock_init(&lock); /* 初始化rwlock */
/* 读时获取锁*/
read_lock(&lock);
... /* 临界资源 */
read_unlock(&lock);
/* 写时获取锁*/
write_lock_irqsave(&lock, flags);
... /* 临界资源 */
write_unlock_irqrestore(&lock, flags);顺序锁
顺序锁是读写锁的优化,读执行单元就不会被写执行单元阻塞阻塞,写与写互斥,对于顺序锁,尽管读写之间不互相排斥,但是如果读执行单元在读期间,发生了写的操作,那么读执行单元就是重新进行调度操作,来保证数据的完整性,是可能发生反复读写才能读到正确的数据的情况的。
- 获取顺序锁
void write_seqlock(seqlock_t *sl);
int write_tryseqlock(seqlock_t *sl);
write_seqlock_irqsave(lock, flags)
write_seqlock_irq(lock)
write_seqlock_bh(lock)
write_seqlock_irqsave() = loal_irq_save() + write_seqlock()
write_seqlock_irq() = local_irq_disable() + write_seqlock()
write_seqlock_bh() = local_bh_disable() + write_seqlock()- 释放锁
void write_sequnlock(seqlock_t *sl);
write_sequnlock_irqrestore(lock, flags)
write_sequnlock_irq(lock)
write_sequnlock_bh(lock)
write_sequnlock_irqrestore() = write_sequnlock() + local_irq_restore()
write_sequnlock_irq() = write_sequnlock() + local_irq_enable()
write_sequnlock_bh() = write_sequnlock() + local_bh_enable()读执行单元涉及的顺序锁要复杂一些
- 读
unsigned read_seqbegin(const seqlock_t *sl);
read_seqbegin_irqsave(lock, flags)- 重读
int read_seqretry(const seqlock_t *sl, unsigned iv);
read_seqretry_irqrestore(lock, iv, flags)//示例
do {
seqnum = read_seqbegin(& seqlock_q);
...
}while (read_seqretry(&seqlock_a, seqnum));RCU
当写的时候,首先复制出一个副本,然后对副本进行修改,最后使用一个回调机制在适当的实际把原来的数据重新指向新的被修改的数据,这个时机就是所有引用该数据的 CPU都退出对共享数据读操作的时候,等待适当时机这一期限叫做宽限期。
rcu_read_lock()
rcu_read_lock_bh()
rcu_read_unlock()
rcu_read_unlock_bh()
rcu_read_lock()
.../* 读临界区*/
rcu_read_unlock()
synchronize_rcu()sync由RCU写执行单元调用,它将阻塞写执行单元,直到当前CPU上所有已经存在的读执行单元完成读的时候才能执行写的下一步动作。
void call_rcu(struct rcu_head *head,
void (*func)(struct rcu_head *rcu));
//该函数也由RCU写执行单元调用,与sync不同的是,它不会使写单元阻塞,可以用到中断或软中断上下文中。
//该函数会把func挂到RCU的回调函数链上,然后立即返回,挂的回调函数会在一个宽限期结束之后执行。
rcu_assign_pointer(p, v);// 给RCU保护的指针赋予一个新值
rcu_dereference(p);//获取一个由RCU保护的指针
rcu_access_pointer(p); // 获取由RCU保护的指针,但是不引用,可以用来判断这个指针是否有效,并不关心内容RCU相关原语已经内嵌了相关的编译屏障或内存屏障
对于链表,rcu有如API
static inline void list_add_rcu(strcut list_head *new, struct list_head *head);
static inline void list_add_tail_rcu(struct list_head *new, struct lis_head *head);
statict inline void list_del_rcu(struct list_head *entry);
static inline void list_replace_rcu(struct list_head *old, struct list_head *new);
list_for_each_entry_rcu(pos, head);//这是一个宏用来便利链表,只要在读执行单元临界区使用这个宏,就可以安全地和其他rcu保护的链表操作函数并发运行。代码示例
rcu_read_lock();
list_for_each_entry_rcu(p, head, list) {
do_something_with(p->a, p->b, p->c);
}
rcu_read_unlock();信号量
semaphore是操作系统最典型的用于同步和互斥的手段,信号量的值可以是0,1,信号量和操作系统中经典概念PV
p(s):将信号量s减一,即s = s - 1;如果s大于零继续执行,否则进入等待状态,排入等待队列。
v(s):信号量加一,即s = s + 1; 如果s大于零就唤醒队列中等待信号量的进程。
struct semaphore sem;
void sema_init(struct semphore *sem, int val);
void down(struct semphore *sem);// 获取信号量,该函数导致睡眠不能在中断中使用
int down_interruptible(struct semaphore * sem);// 该进程进入睡眠状态的进程可以被信号打断,接受到信号之后,函数会返回非零值
int down_trylock(struct semaphore *sem);//尝试获取信号量,不能的话立刻返回
void up(struct semaphore *sem);//释放信号量
//常用方法:
if (down_interruptible(&sem))
return -ERESTARTSYS;信号量与自旋锁不同之处在于,当获取不到信号量的时候并非原地打转而是进入休眠状态。
信号量用作互斥已经不再被推荐,而是用于同步等待。
互斥体
mutex
struct mutex my_mutex;
mutex_init(&my_mutex);
void mutex_lock(struct mutex *lock);
int mutex_lock_interruptible(struct mutex *lock);// 睡眠可以被信号打断
int mutex_trylock(struct mutex *lock);// 不陷入睡眠
void mutex_unlock(struct mutex *lock);- 当锁不能被获取到,互斥体开销在进程上下文切换,使用自旋锁开销是等待获取自旋锁,临界区小适合自旋锁。
- 互斥体保护的临界区可包含可能引起阻塞的代码,而自旋锁则绝对要避免用来保护包含这样代码的临界区,因为阻塞就要切换进程,用自旋锁,切换出去另一个进程要求获取自旋锁就会死锁。
- 互斥体存在于进程的上下文,如果被保护的资源要在中断或者软中断下使用,只能选择自旋锁,如果实在要用互斥体,只能用mutex-trylock()进行上锁
完成量
Completion:一个执行单元等待另一个执行单元执行完某事 。
struct completion my_completion;
init_completion(&my_completion);
reinit_completion(&my_completion);
void wait_for_completion(struct completion *c);
void complete(struct completion *c);
void complete_all(struct completion *c);阻塞与非阻塞io
- 阻塞:不能获得获得资源就会挂起进程,直到满足操作条件,被挂起的进程进入睡眠状态。
- 非阻塞:不能获得设备操作时,并不挂起,要么放弃要么轮询。
fd = open("path", O_WRDR | O_NONBLOCK);//非阻塞的形式
//文件打开后还可以通过ioctl()和fcntl()改变读写方式。
fcntl(fd, F_SETFL, O_NONBLOCK);等待队列
阻塞的进程必须要唤醒,如果不唤醒可能陷入永久的沉睡,而在linux驱动程序中,可以使用等待队列(wait Queue ) 实现阻塞进程的唤醒。
//定义等待队列
wait_queue_head_t my_queue;
//wait_queue_head_t 是 __wait_queue_head 结构体的一个typedef
//初始化"等待队列头部”
init_waitqueue_head(&my_queue);
//同样可以使用DECLARE_WAIT_QUEUE_HEAD(name),这个宏来初始化等待队列的头部
//定义等待队列元素
DECLARE_WAITQUEUE(name, tsk);//这个宏可以定义并初始化一个等待队列
//增删
void add_wait_queue(wait_queue_head_t *q, wait_queue_t *wait);
void remove_wait_queue(wait_queue_head_t *q, wait_queue_t *wait);
//等待事件
wait_event(queue, condition)
wait_event_interruptible(queue, condition)//可以被信号打断
wait_event_timeout(queue, condition, timeout)//加入超时时间
wait_event_interruptible_timeout(queue, condition, timeout)
//等待第一个参数作为等待队列头部的队列被唤醒,并且第二个参数condition也必须满足否则会继续阻塞。
//唤醒队列
void wake_up(wait_queue_head_t *queue);//唤醒该等待队列头部的队列中所有的进程
void wake_up_interruptible(wait_queue_head_t *queue);
//第一个可以唤醒TASK_INTERRUPTIBLE 和TASK_UNINTERRUPTIBLE,第二个只能唤醒前面那个
//在等待队列睡眠
sleep_on(wait_queue_head_t *q );
interruptible_sleep_on(wait_queue_head_t *q );
//sleep_on()函数的作用就是将目前进程的状态置成TASK_UNINTERRUPTIBLE,并定义一个等待队列元素,之后把它挂到等待队列头部q指向的双向链表,直到资源可获得,q队列指向链接的进程被唤醒。interruptible_sleep_on()与sleep_on()函数类似,其作用是将目前进程的状态置成TASK_INTERRUPTIBLE,并定义一个等待队列元素,之后把它附属到q指向的队列,直到资源可获得(q指引的等待队列被唤醒)或者进程收到信号轮询
BSD UNIX 的select()系统调用
int select(int numfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
FD_ZERO(fd_set *set);
FD_SET(int fd,fd_set *set)
FD_CLR(int fd,fd_set *set)
FD_ISSET(int fd,fd_set *set)其中readfds、writefds、exceptfds分别是是表示读、写和异常处理的文件描述符集合。
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
int epoll_create(int size);
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);驱动中的轮询编码
unsigned int(*poll)(struct file * filp, struct poll_table* wait);
//对可能引起设备文件状态变化的等待队列调用poll_wait(),将对应的等待队列头部添加到poll_table中。
//返回表示是否可以对设备进行无阻塞读、写访问的掩码
void poll_wait(struct file *filp, wait_queue_heat_t *queue, poll_table * wait);
//将当前进程添加到wait参数指定的等待队列中,实际作用是让唤醒参数queue对应的等待队列可以唤醒因select而异步通知和异步io
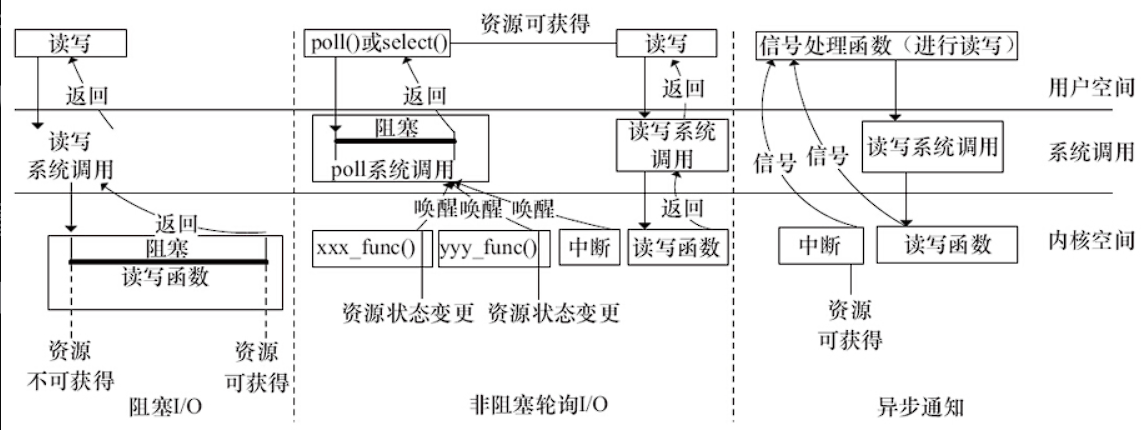
Linux异步通知编程
信号
进程间通信(IPC)是UNIX中的一种传统机制。
| 信号名称 | 值 | 默认含义说明 |
|---|---|---|
| SIGHUP | 1 | 终端连接断开或控制进程结束 |
| SIGINT | 2 | 键盘中断(通常是 Ctrl+C) |
| SIGQUIT | 3 | 键盘退出(通常是 Ctrl+\) |
| SIGILL | 4 | 非法指令(程序错误) |
| SIGTRAP | 5 | 调试陷阱(断点捕获) |
| SIGABRT | 6 | 程序调用 abort() 触发的异常终止 |
| SIGBUS | 7 | 内存访问错误(总线错误) |
| SIGFPE | 8 | 算术运算错误(如除零) |
| SIGKILL | 9 | 强制终止进程(不可捕获或忽略) |
| SIGUSR1 | 10 | 用户自定义信号 1 |
| SIGSEGV | 11 | 非法内存访问(段错误) |
| SIGUSR2 | 12 | 用户自定义信号 2 |
| SIGPIPE | 13 | 管道写入中断(读端已关闭) |
| SIGALRM | 14 | 定时器超时(由 alarm() 设置) |
| SIGTERM | 15 | 优雅终止进程(默认的 kill 命令信号) |
| SIGSTKFLT | 16 | 协处理器栈错误 |
| SIGCHLD | 17 | 子进程状态改变 |
| SIGCONT | 18 | 恢复已停止的进程 |
| SIGSTOP | 19 | 强制暂停进程(不可捕获或忽略) |
| SIGTSTP | 20 | 终端暂停信号(通常是 Ctrl+Z) |
| SIGTTIN | 21 | 后台进程尝试读终端 |
| SIGTTOU | 22 | 后台进程尝试写终端 |
| SIGURG | 23 | 套接字紧急数据 |
| SIGXCPU | 24 | CPU 时间超限 |
| SIGXFSZ | 25 | 文件大小超限 |
| SIGVTALRM | 26 | 虚拟定时器超时 |
| SIGPROF | 27 | 性能分析定时器超时 |
| SIGWINCH | 28 | 终端窗口大小改变 |
| SIGIO | 29 | 异步 I/O 事件 |
| SIGPWR | 30 | 电源故障(系统关机) |
| SIGSYS | 31 | 无效系统调用 |
| SIGRTMIN | 34 | 实时信号(最小值) |
| SIGRTMAX | 64 | 实时信号(最大值) |
信号的接收
void (*signal(int signum, void (*handler)(int)))(int);
void sigterm_handler(int signo)
{
exit(0);
}
int main(void)
{
signal(SIGINT, sigterm_handler);
signal(SIGTERM, sigterm_handler);
while(1);
return 0;
}
//除了signal()函数之外,sigaction()函数可用于改变进程接受到特定信号后的行为
int sigaction(int signum, const struct signaction *act, struct signaction *oldact);信号的释放
为了使设备支持异步通知机制,驱动程序中有三项工作:
- 支持F_SETOWN命令,能在这个控制命令处理中设置flip->f_owner对应进程ID
- 支持F_SETFL命令的处理,每当FASYNC标志改变时,驱动程序中的fasync()函数将得以执行。因此,驱动中应该实现fasync()函数。
- 在设备资源可获得时,调用kill_fasync()函数激发相应的信号。
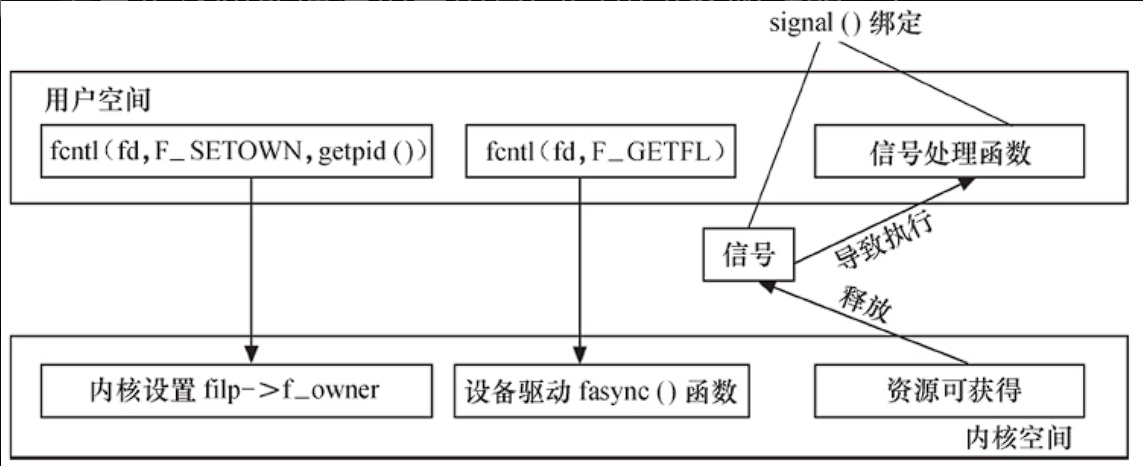
设备驱动中异步通知编程就是一个数据结构和两个函数,数据结构是fsaync_struct结构体,函数是
// 处理FASYNC标志变更的函数
int fasync_helper(int fd, struct file *filp, int mode, struct fasync_struct **fa);
//释放信号用函数
void kill_fasync(struct fasync_struct **fa, int sig, int band);struct xxx_dev {
struct cdev cdev; /* cdev结构体*/
...
struct fasync_struct *async_queue; /* 异步结构体指针 */
};
//结构体模板
static int xxx_fasync(int fd, struct file *filp, int mode)
{
struct xxx_dev *dev = filp->private_data;
return fasync_helper(fd, filp, mode, &dev->async_queue);
}
//支持异步通知的设备驱动fasync()函数模板
static ssize_t xxx_write(struct file *filp, const char __user *buf, size_t count, loff_t *f_pos)
{
struct xxx_dev *dev = filp->private_data;
...
/* 产生异步读信号 */
if (dev->async_queue)
kill_fasync(&dev->async_queue, SIGIO, POLL_IN);
...
}
//支持异步通知的设备驱动信号释放范例
static int xxx_release(struct inode *inode, struct file *filp)
{
/* 将文件从异步通知列表中删除 */
xxx_fasync(-1, filp, 0);
...
return 0;
}
// 支持异步通知的设备驱动release()函数模板lINUX异步IO
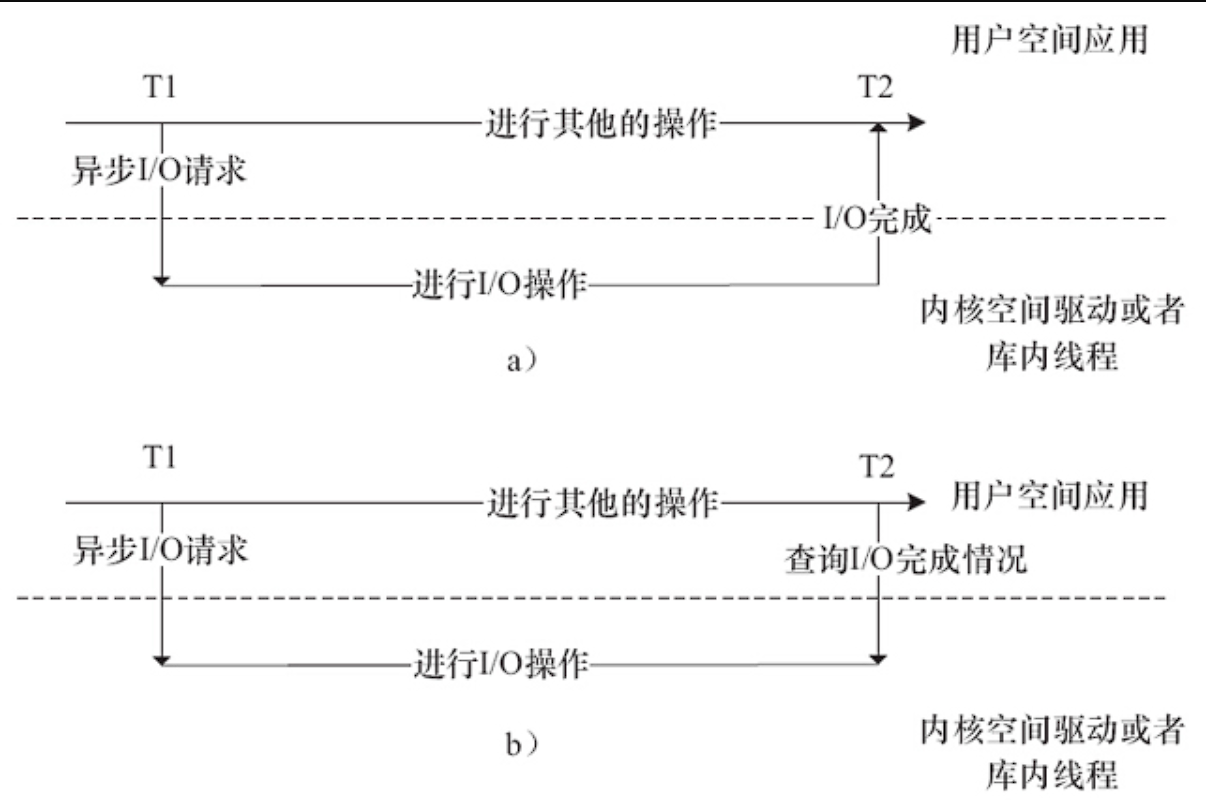
linux的一种实现是在用户空间glibc库实现,借用多线程模型,用开启新的线程以同步的方式做IO。
//aio_read()
int aio_read(struct aiocb *aiocbp);//请求对一个有效的文件描述进行异步读操作。可以表示文件、套接字、甚至是管道
//函数在请求进行排队之后就会立刻返回,执行成功返回是0,出现错误返回-1,设置errno
//aio_write
int aio_write(struct aiocb *aiocbp);
//函数用来请求一个异步写操作
//aio_error()
int aio_error(struct aiocb *aiocbp);
/*
EINPROGRESS:说明请求尚未完成。
ECANCELED:说明请求被应用程序取消了。
-1:说明发生了错误,具体错误原因由errno记录。
*/
aio_return()
//异步io并没有阻塞在read()调用上,在异步io种通过
ssize_t aio_return(struct aiocb *aiocbp);
//通过aio_error调用确认状态之后,调用aio_return
//aio_suspend()
int aio_suspend( const struct aiocb *const cblist[],int n, const struct timespec *timeout );
//可以阻塞调用进程,直到异步请求完成,提供了aiocb列表,完成任何一个都会导致返回。
//aio_cancel()
int aio_cancel(int fd, struct aiocb *aiocbp);
//取消一个请求,用户需提供文件描述符和aiocb指针
//lio_listio()函数可用于同时发起多个传输
int lio_listio( int mode, struct aiocb *list[], int nent, struct sigevent *sig );内核AIO提供的系统调用主要包括
int io_setup(int maxevents, io_context_t *ctxp);
int io_destroy(io_context_t ctx);
int io_submit(io_context_t ctx, long nr, struct iocb *ios[]);
int io_cancel(io_context_t ctx, struct iocb *iocb, struct io_event *evt);
int io_getevents(io_context_t ctx_id, long min_nr, long nr, struct io_event *events,
struct timespec *timeout);
void io_set_callback(struct iocb *iocb, io_callback_t cb);
void io_prep_pwrite(struct iocb *iocb, int fd, void *buf, size_t count, long long offset);
void io_prep_pread(struct iocb *iocb, int fd, void *buf, size_t count, long long offset);
void io_prep_pwritev(struct iocb *iocb, int fd, const struct iovec *iov, int iovcnt,
long long offset);
void io_prep_preadv(struct iocb *iocb, int fd, const struct iovec *iov, int iovcnt,
long long offset);中断
中断可以分为内部中断和外部中断,内部中断源自于CPU(软件中断指令、溢出、除法错误),外部中断来自于CPU外,由外设提出请求。
根据可不可屏蔽,分为可屏蔽中断与不可屏蔽中断,可屏蔽中断可以通过设置中断控制器寄存器等方法被屏蔽,屏蔽后中断不再等到响应。
根据中断入口的跳转方法,可分为向量中断和非向量中断,采用向量中断的cpu通常为不同的中断分配不同的中断号,当检测到某中断号的中断到来后,自动跳转到与该中断号对应的地址执行。而非向量中断的多个中断共享一个入口地址,进入入口之后再由软件判断中断标志来识别中断。
GIC:支持SGI软件产生的中断
SGI(Software Generated Interrupt):软件产生的中断,可以用于多核的核间通信,一个CPU可以通过写GIC的寄存器给另外一个CPU产生中断。多核调度用的IPI_WAKEUP、IPI_TIMER、IPI_RESCHEDULE、IPI_CALL_FUNC、IPI_CALL_FUNC_SINGLE、IPI_CPU_STOP、IPI_IRQ_WORK、IPI_COMPLETION都是由SGI产生的
PPI某个CPU私有外设的中断—》中断只能发给绑定CPU
SPI共享外设的中断,该中断可以路由到任何一个CPU
extern int irq_set_affinity (unsigned int irq, const struct cpumask *m);//内核可以通过该API设置中断除法的CPU核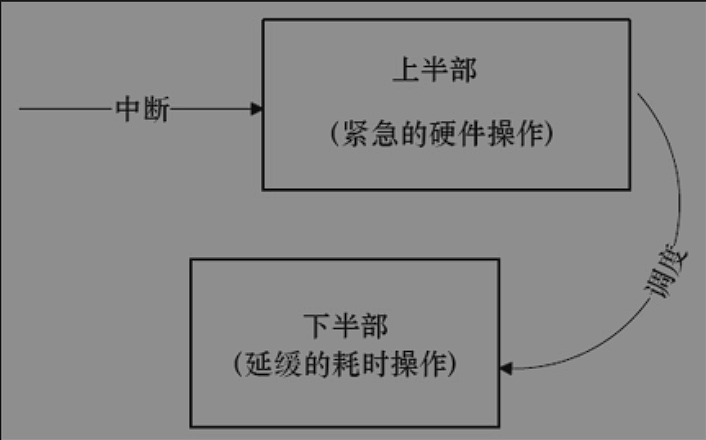
为了在中断执行时间尽可能短和尽量完成多的工作之间寻找平衡点将中断处理程序拆分成两个部分包括:顶半部、底半部。顶半部完成尽量少的紧急功能,简单读取寄存器的中断状态,并在清楚中断标志后就进行登记中断的工作。登记中断就是将底半部处理程序挂在该设备的底半部执行队列上面。
顶半部往往设计成不可以中断,而底半部允许被新的中断中断。
查看/proc/interrupts文件就可以获得系统中中断的统计信息
- 申请irq
int request_irq(unsigned int irq, irq_handler_t handler, unsigned long flags,const char *name, void *dev);
int devm_request_irq(struct device *dev, unsigned int irq, irq_handler_t handler, unsigned long irqflags, const char *devname, void *dev_id);
//此函数与request_irq()的区别是devm_开头的API申请的是内核“managed”的资源,一般不需要在出错处理和remove()接口里再显式的释放顶半部结构体定义
typedef irqreturn_t (*irq_handler_t)(int, void *);
typedef int irqreturn_t;- 释放irq
void free_irq(unsigned int irq,void *dev_id);屏蔽中断源
void disable_irq(int irq);//后者等待目前的中断处理完成
void disable_irq_nosync(int irq);//前者立即返回
void enable_irq(int irq);
# define local_irq_save(flags) ...//将目前的中断状态保留在flags中
void local_irq_disable(void);//后者禁止中断所以不保存中断状态
#define local_irq_restore(flags)...
void local_irq_enable(void);//对应上面的恢复函数底半部机制,实现有tasklet 、工作队列、软中断、线程化irq
- tasklet
//它的执行上下文是软中断,执行时机通常是顶半部返回的时候,定义tasklet及处理函数将二者关联即可
void my_tasklet_func(unsigned long); /*定义一个处理函数*/
DECLARE_TASKLET(my_tasklet, my_tasklet_func, data);
/*定义一个tasklet结构my_tasklet,与my_tasklet_func(data)函数相关联*/
//调度的时候使用
tasklet_schedule(&my_tasklet);- 工作队列
工作队列的使用方法和tasklet非常相似,但是工作队列的执行上下文是内核线程,因此可以调度和睡眠。
struct work_struct my_wq; /* 定义一个工作队列 */
void my_wq_func(struct work_struct *work); /* 定义一个处理函数 */
INIT_WORK(&my_wq, my_wq_func);
/* 初始化工作队列并将其与处理函数绑定 */
schedule_work(&my_wq); /* 调度工作队列执行 */
//使用cmwq实现,自动维护工作队列的线程池以提高并发性。- 软中断
//传统的底半部处理机制,内核中,使用softirq_action结构体表征一个软中断,这个结构体会包含中断处理函数指针和传递给函数的参数。使用Open_softirq()注册软中断对应的处理函数,raise_softirq()函数可以触发一个软中断。工作队列运行进程上下文,而软中断和tasklet运行于软中断上下文原子上下文的一种。
local_bh_disable()和local_bh_enable()是内核用于禁止和用能软中断以及tasklet底半部机制的函数。
内核中采用softirq的地方包括HI_SOFTIRQ、TIMER_SOFTIRQ、NET_TX_SOFTIRQ、NET_RX_SOFTIRQ、SCSI_SOFTIRQ、TASKLET_SOFTIRQ等。
硬中断:外部设备对CPU的中断。
软中断:中断底半部的一种处理机制。
信号:是内核对某个进程的中断。
软中断以及基于软中断的tasklet如果在某段时间内大量出现的话,内核会把后续软中断放入ksiftirqd内核线程中执行。
threaded_irq()
//除了可以通过request_irq()、devm_request_irq()申请中断以外,还可以通过request_threaded_irq()和devm_request_threaed_irq()申请。参数handler对应的函数执行中断上下文,thread_fn参数对应的函数则执行于内核线程。
request_thread_irq()和devm_request_thread_irq()支持在irqflags设置IRQF_ONESHOT标记,这样内核会自动帮助我们在中断上下文屏蔽对应的中断号,而在内核调度thread_fn执行后,重新使能该中断号。
handler参数可以设置为NULL,这种情况下,内核会用默认的irq_default_primary_handler()代替handler,并会使用IRQF_ONESHOT标记。
/*
* Default primary interrupt handler for threaded interrupts. Is
* assigned as primary handler when request_threaded_irq is called
* with handler == NULL. Useful for oneshot interrupts.
*/
static irqreturn_t irq_default_primary_handler(int irq, void *dev_id)
{
return IRQ_WAKE_THREAD;
}- 中断共享
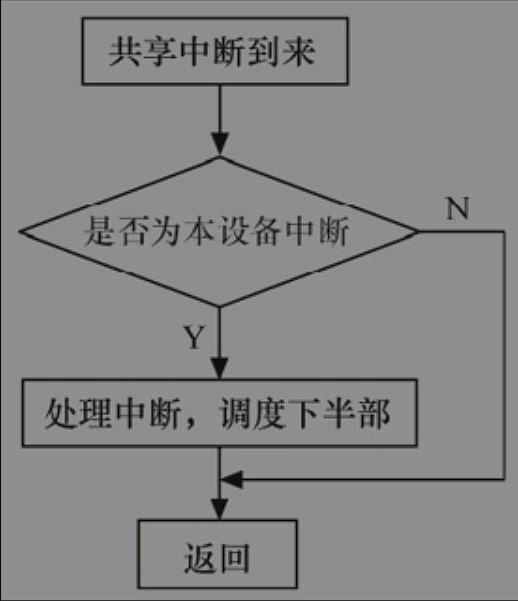
多个设备共享一根硬件中断线的情况在实际的硬件系统中广泛存在,Linux支持这种中断共享。
- 共享中断的多个设备在申请中断,都应该使用IRQF_SHARED标志,而且一个设备以IRQF_SHARED申请某中断成功的前提是该中断未被申请。
- 尽管内核模块可访问的全局地址都可以作为
request_irq(.., void *dev_id),但是设备结构体指针显然是可传入的最佳参数。 - 在中断到来,会便利执行共享此中断的所有中断处理程序,直到某一个函数返回IRQ_HANDLED。在中断处理程序的顶半部中,应根据硬件寄存器中的信息比照传入的dev_id参数,迅速地判断是否为本设备的中断,不是则返回IRQ_NONE
内核会在时钟中断发生后检测各定时器是否到期,到期后的定时器处理函数将作为软中断在底半部执行。时钟中断处理程序会唤起TIMER_SOFTIRQ软中断,运行当前处理器上到期的所有定时器。
定时器期满,就会执行成员函数。
struct timer_list {
/*
* All fields that change during normal runtime grouped to the
* same cacheline
*/
struct list_head entry;
unsigned long expires;
struct tvec_base *base;
void (*function)(unsigned long);
unsigned long data;
int slack;
#ifdef CONFIG_TIMER_STATS
int start_pid;
void *start_site;
char start_comm[16];
#endif
#ifdef CONFIG_LOCKDEP
struct lockdep_map lockdep_map;
#endif
23 };- 初始化定时器
- 增加定时器
- 删除定时器
内核中延迟的工作delayed_work
本质是利用工作队列和定时器实现,这套快捷机制就是delayed_work
struct delayed_work {
struct work_struct work;
struct timer_list timer;
/* target workqueue and CPU ->timer uses to queue ->work */
struct workqueue_struct *wq;
int cpu;
};
int schedul_delayed_work(struct delayed_work *work, unsigned long delay);
//当指定的delay到来时,delayed_work结构体中的work成员work_func_t 类型成员func()会被执行。
typedef void (*work_func_t)(struct work_struct *work);
schedule_delayed_work(&work, msecs_to_jiffies(poll_interval));
//msecs_to_jiffies()用于将毫秒转化为jiffies。内核延时
void ndelay(unsigned long nsecs);
void udelay(unsigned long usecs);
void mdelay(unsigned long msecs);
//分别以纳秒、微秒和毫秒延迟,上述实现原理本质是忙等待,它根据cpu频率进行一定次数的循环。
//内核启动时,会运行一个延迟循环标准,计算出lpj(loops per jiffy),然后打打印信息,如果直接在bootloader传递给内核的boottargs中设置,就可以省去校准的时间。毫秒级延时,对于内核来说比较大,会耗费cpu资源,对于毫秒级以上
void msleep(unsigned int millisecs);
unsigned long msleep_interruptible(unsigned int millisecs);
void ssleep(unsigned int seconds);上述函数将使用调用它的进程睡眠参数指定的时间为millisecs,msleep()、ssleep()不能打断,而msleep_interruptible()可以打断。
受限于系统HZ以及进程调度的影响,msleep()类似函数的精度是有限的。
内核进行延迟的直观方法是比较当前的jiffies和目标jiffies,直到达到jiffies。
#define time_after(a,b) \
(typecheck(unsigned long, a) && \
typecheck(unsigned long, b) && \
((long)(b) - (long)(a) < 0))
#define time_before(a,b) time_after(b,a)睡着延迟:在等待时间到达位置处于睡眠状态,转让CPU。
schedule_timeout()可以让当前任务休眠到指定的jiffies之后再重新被调度执行
void msleep(unsigned int msecs)
{
unsigned long timeout = msecs_to_jiffies(msecs) + 1;
while (timeout)
timeout = schedule_timeout_uninterruptible(timeout);
}
unsigned long msleep_interruptible(unsigned int msecs)
{
unsigned long timeout = msecs_to_jiffies(msecs) + 1;
while (timeout && !signal_pending(current))
timeout = schedule_timeout_interruptible(timeout);
return jiffies_to_msecs(timeout);
}
sleep_on_timeout(wait_queue_head_t *q, unsigned long timeout);
interruptible_sleep_on_timeout(wait_queue_head_t*q, unsigned long timeout);//当前两个函数可以将当前进程添加到等待队列中,在等待队列上睡眠。schedule_timeout()实现原理是向系统添加一个定时器,在定时器处理函数中唤醒与参数对应的进程。
内存与IO
x86处理器存在IO空间的概念,它通过特定的指令in、out访问。端口号表示了外设的寄存器地址。
指令格式类似
IN 累加器, {端口号│DX}
OUT {端口号│DX},累加器大多数嵌入式微控制器并不提供IO空间,而是通过指针、地址等操作内存空间。
186处理中(16位段地址、16位偏移地址)
unsigned char *p = (unsigned char *)0xF000FF00;
*p=11;在ARM、POWERPC等未采用段地址的处理器中,p指向的内存空间就是0xF0000xFF00
注
因为186处理器启动之后会在绝对地址0XFFFF0(对应指针地址是0xF000FFF0),所以可以有以下代码
typedef void (*lpFunction) ( ); /* 定义一个无参数、无返回类型的函数指针类型 */
lpFunction lpReset = (lpFunction)0xF000FFF0; /* 定义一个函数指针,指向 */
/* CPU启动后所执行的第一条指令的位置 */
lpReset(); /* 调用函数 */以上代码相当于执行了软重启。
x86的IO空间的使用也是可选的,设计电路板的时候外设仍然可以只挂接在内存空间。
MMU,该内存管理单元辅助操作系统进行内存管理,提供虚拟地址和物理地址的映射、内存访问权限保护以及Cache缓存控制等硬件支持。
- TLB:转换旁路缓存,缓存少量的虚拟地址与物理地址的转换关系,是转换表的Cache,也叫做快表。
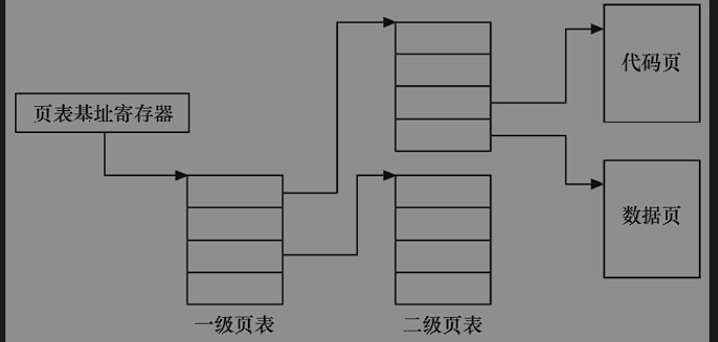
- TTW:转换表漫游,当TLB中没有缓冲对应的地址转换关系时,需要通过对内存中转换表的访问来获得虚拟地址和物理地址的对应关系,TTW成功之后,就会将结果写到TLB里面。(大多数处理器的转换表为多级页表)
当ARM要访问存储器时,MMU先查找TLB中的虚拟地址表。如果ARM的结构支持分开的数据TLB(DTLB)和指令TLB(ITLB),则除了取指令使用ITLB外,其他的都使用DTLB。
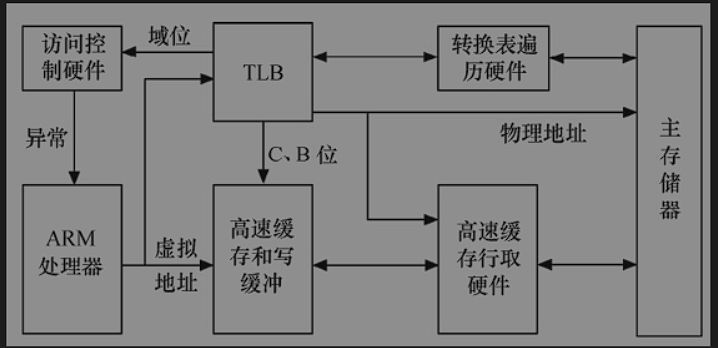
TLB中没有虚拟地址的入口,则转换表遍历硬件并从存放于主存储器内的转换表中获取地址转换信息和访问权限(即执行TTW),同时将这些信息放入TLB,它或者被放在一个没有使用的入口或者替换一个已经存在的入口。之后,在TLB条目中控制信息的控制下,当访问权限允许时,对真实物理地址的访问将在Cache或者在内存中发生
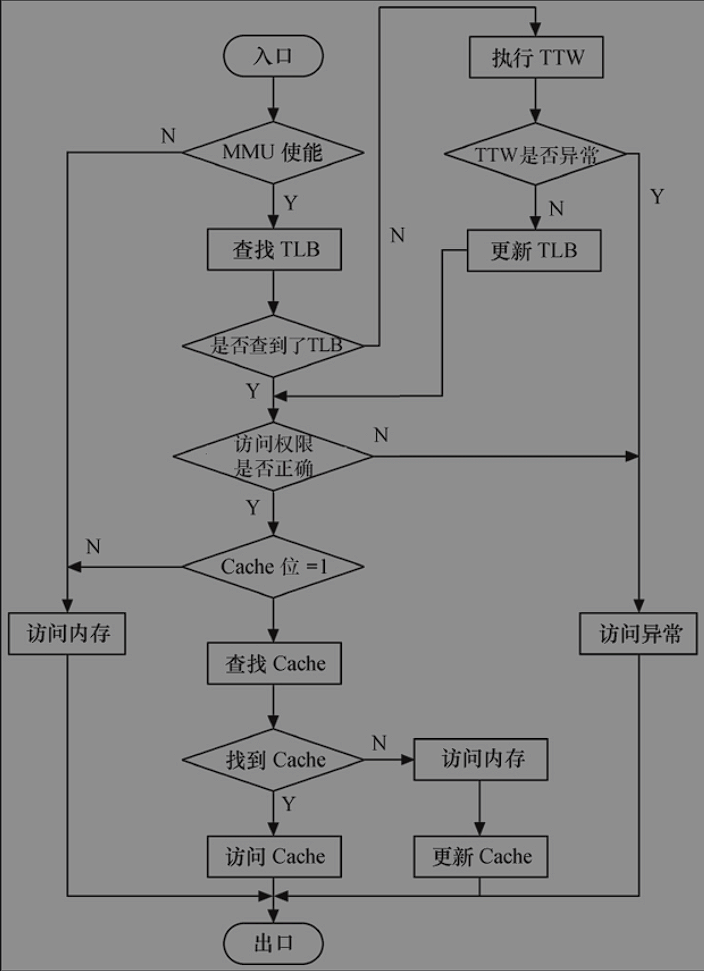
ARM内TLB条目的控制信息用于控制对对应地址的访问权限以及Cache的操作。
C高速缓存和B(缓冲)位被用来控制对应地址的高速缓存和写缓存,并决定是否进行高速缓存。
访问权限和域位用来控制读写访问是否被允许。如果不允许,MMU则向ARM处理器发送一个存储器异常,否则访问被运行进行。
MMU具有虚拟地址和物理地址转换、内存访问权限保护等功能,这将使得Linux操作系统能单独为系统的每个用户进程分配独立的内存空间并保证用户空间不能访问内核空间的地址,为操作系统的虚拟内存管理模块提供硬件基础。
在Linux 2.6.11之前,Linux内核硬件无关层使用了三级页表PGD、PMD和PTE;从Linux 2.6.11开始,为了配合64位CPU的体系结构,硬件无关层则使用了4级页表目录管理的方式,即PGD、PUD、PMD和PTE。注意这仅仅是一种软件意义上的抽象,实际硬件的页表级数可能少于4。
新版的Linux 2.6支持不带MMU的处理器。在嵌入式系统中,仍存在大量无MMU的处理器,Linux 2.6为了更广泛地应用于嵌入式系统,融合了mClinux,以支持这些无MMU系统,如Dragonball、ColdFire、Hitachi H8/300、Blackfin等
在Linux系统中,进程的4GB内存空间被分为两个部分—用户空间与内核空间。用户空间的地址一般分布为0~3GB(即PAGE_OFFSET,在0x86中它等于0xC0000000),这样,剩下的34GB为内核空间.
每个进程的用户空间完全独立、互不相干的,用户进程各自有不同的页表。内核空间由内核负责映射,并不会跟着进程改变,是固定的。内核空间的虚拟地址到物理地址映射是被所有进程共享的,内核的虚拟空间独立于其他程序。
Linux中1GB的内核地址空间又被划分为物理内存映射区、虚拟内存分配区、高端页面映射区、专用页面映射区和系统保留映射区这几个区域。
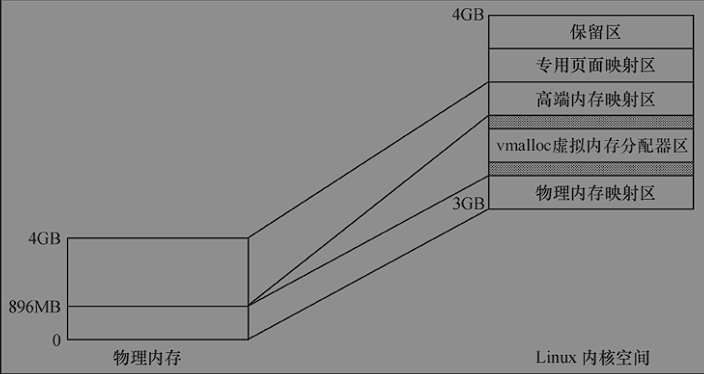
对于x86系统而言,一般情况下,物理内存映射区最大长度为896MB,系统的物理内存被顺序映射在内核空间的这个区域中。当系统物理内存大于896MB时,超过物理内存映射区的那部分内存称为高端内存(而未超过物理内存映射区的内存通常被称为常规内存),内核在存取高端内存时必须将它们映射到高端页面映射区。
LInux保留内核空间最顶部FIXADDR_TOP~ 4GB的区域作为保留区,紧接着最顶端的保留区以下的一段区域为专用页面映射区(FIXADDR_START~FIXADDR_TOP),它的总尺寸和每一页的用途由fixed_address枚举结构在编译时候预定义,用__fix_to_virt(index)可获取专用区内预定义页面的逻辑地址
efine FIXADDR_START (FIXADDR_TOP - _ _FIXADDR_SIZE)
#define FIXADDR_TOP ((unsigned long)_ _FIXADDR_TOP)
#define _ _FIXADDR_TOP 0xfffff000
//如果有高端内存,则位于专用页面映射区之下的高端内存映射区,起始地址为PK
#define PKMAP_BASE ( (FIXADDR_BOOT_START - PAGE_SIZE*(LAST_PKMAP + 1)) & PMD_MASK )
#define FIXADDR_BOOT_START (FIXADDR_TOP - _ _FIXADDR_BOOT_SIZE)
#define LAST_PKMAP PTRS_PER_PTE
#define PTRS_PER_PTE 512
#define PMD_MASK (~(PMD_SIZE-1))
# define PMD_SIZE (1UL << PMD_SHIFT)
#define PMD_SHIFT 21在物理区和高端映射区之间为虚拟内存分配器区(VMALLOC_START~~VMALLOC_END),用于vmalloc()函数,它的前部与物理内存映射区有一个隔离带,后部与高端映射区也有一个隔离带,vmalloc区域定义如下:
#define VMALLOC_OFFSET (8*1024*1024)
#define VMALLOC_START (((unsigned long) high_memory +
vmalloc_earlyreserve + 2*VMALLOC_OFFSET-1) & ~(VMALLOC_OFFSET-1))
#ifdef CONFIG_HIGHMEM /* 支持高端内存 */
# define VMALLOC_END (PKMAP_BASE-2*PAGE_SIZE)
#else /* 不支持高端内存 */
# define VMALLOC_END (FIXADDR_START-2*PAGE_SIZE)
#endif当系统物理内存超过4gb,必须使用CPU的扩展分页(PAE)模式所提供的64页目录项才能取到4GB以上的物理内存,这需要cpu的支持,假如PAE功能的Intel Pentinum Pro 以及以后的CPU允许最大内存配置到64GB,它们具备36位物理地址空间寻址能力。
在32位的x86而言,在3-4GB之间的内核空间中,从低地址到高地址依次为:物理内存映射区->隔离带->vmalloc虚拟内存分配器->隔离带->高端内存映射区->专用页面映射区->保留区。
直接进行的映射的896MB物理内存其实又分为两个区域,在16MB的区域,ISA设备可以作为DMA,所以该区域为DMA区域(内核为了保证ISA驱动在申请DMA缓冲区的时候,通过GFP_DMA标记可以确保申请到16MB以内的内存,所以必须把这个区域列为一个单独的区域管理)16-896MB之间的常规区域,高于就是高端内存区域。
32ARM内核映射和X86有所区别,0xffff0000~0xffff0fff是“CPU vector page”,即向量表的地址。0xffc00000。0xffefffff是DMA内存映射区域。dma_alloc_xxx族函数把DMA缓冲区映射在这一段,VMALLOC_START----VMALLOC_END-1是vmalloc和ioremap区域(在vmalloc区域的大小可以配置,通过“vmalloc=”这个启动参数可以指定),PAGE_OFFSET---high_memory-1是DMA和正常区域的映射区域,MODULES_VADDR---MODULES_END-1是内核模块区域,PKMAP_BASE---PAGE_OFFSET-1是高端内存映射区。假设我们把PAGE_OFFSET定义为3GB,实际上Linux内核模块位于3GB-16MB~3GB-2MB,高端内存映射区则通常位于3GB-2MB---3GB。
给出了32位ARM系统Linux内核地址空间中的内核模块区域、高端内存映射区、vmalloc、向量表区域等。我们假定编译内核的时候选择的是VMSPLIT_3G(3G/1G user/kernel split)。如果用户选择的是VMSPLIT_2G(2G/2G user/kernel split),则图11.7中的内核模块开始于2GB-16MB,DMA和常规内存区域映射区也开始于2GB。
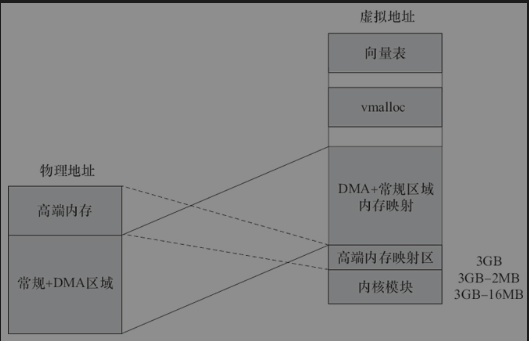
ARM系统的Linux之所以把内核模块安置在3GB或2GB附近的16MB范围内,主要是为了实现内核模块和内核本身的代码段之间的段跳转。
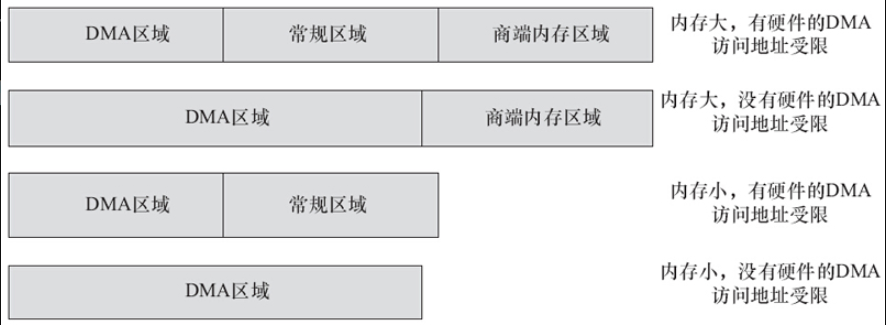
对于ARM soc而言,如果芯片内部有硬件组件的DMA引擎访问内存时有地址空间限制(某些空间访问不到),比如假设UART控制器的DMA只能访问32MB,那么这个低32MB就是DMA区域;32MB到高端内存地址的这段称为高端内存区域。
给出几种DMA、常规、高端内存区域可能的分布,在第一种情况,有硬件的DMA引擎不能访问全部地址,且内存较大而无法全部在内核空间虚拟地址映射下,存放有3个区域;第二种清况下,没有硬件的DMA引擎不能访问全部地址,且内存较大而无法全部在内核空间虚拟地址映射下,则常规区域实际退化为0;第三种情况下,有硬件的DMA引擎不能访问全部地址,且内存较小可以全部在内核空间虚拟地址映射下,则高端内存区域实际退化为0.第四种情况下,没有硬件的DMA引擎不能访问全部地址,且内存较小可以全部在内核空间虚拟地址映射下,则常规和高端内存区域实际退化为0.
malloc函数与free函数
//c库的malloc()函数一般通过brk()和mmap()两个系统调用从内核申请内存
//malloc算法实际上具备一个二次管理能力,并不是每次申请和释放内存都一定伴随着内核的系统调用'
mlockall(MCL_CURRENT | MCL_FUTURE);
mallopt(M_TRIM_THRESHOLD, -1);
mallopt(M_MMAP_MAX, 0);另外,Linux内核总是采用按需调页,因此当malloc()返回的时候,虽然成功返回,但是内核并没有真正给这个进程内存,这个时候申请内存,内存内容全是0,页面映射是只读,只有当写到某个页面的时候,内存才在页错误后,真正把这个页面给这个进程。
内核空间申请内存函数包括kmalloc()、__get_free_pages()和vmalloc()等。kmalloc()和__get_free_pages()申请的内存位于DMA和常规区域的映射区,而且在物理上也是连续的,它们与真实的物理地址只有一个固定的偏移,因此存在较简单的转换关系。而vmalloc()在虚拟内存空间给出一块连续的内存区,实质上这片连续的虚拟内存在物理内存中并不一定连续,而vmalloc()申请的虚拟内存和物理内存之间的也没有简单的换算关系。
- kmalloc()
void *kmalloc(size_t size, int flags);给kmalloc()的第一个参数是要分配的块的大小;第二个参数为分配标志,用于控制kmalloc()的行为。
最常用的分配标志GFP_KERNEL,其含义是在内核空间进程中申请内存。kmalloc()底层依赖__get_free_pages()来实现。
使用GFP_KERNEL标志申请内存时,若暂时不能满足,进程会睡眠等待页,即会引起阻塞,因此不能在中断上下文或持有自旋锁的时候使用GFP_KERNE申请内存。
由于在中断处理函数、tasklet和内核定时器等非进程上下文中不能阻塞,所以此时驱动应当选择GFP_ATOMIC标志申请内存,若不存在空闲页,就不等待,直接返回。
其他的申请标志还包括GFP_USER(用来为用户空间页分配内存,可能阻塞)、GFP_HIGHUSER(类似GFP_USER,但是它从高端内存分配)、GFP_DMA(从DMA区域分配内存)、GFP_NOIO(不允许任何I/O初始化)、GFP_NOFS(不允许进行任何文件系统调用)、__GFP_HIGHMEM(指示分配的内存可以位于高端内存)、__GFP_COLD(请求一个较长时间不访问的页)、__GFP_NOWARN(当一个分配无法满足时,阻止内核发出警告)、__GFP_HIGH(高优先级请求,允许获得被内核保留给紧急状况使用的最后的内存页)、__GFP_REPEAT(分配失败,则尽力重复尝试)、__GFP_NOFAIL(标志只许申请成功,不推荐)和__GFP_NORETRY(若申请不到,则立即放弃)等。
释放对应的kfree()函数
__get_free_pages()
这个系列函数本质是Linux内核最底层用于获取空闲内存的方法,因为底层的buddy算法以2n为单位管理空闲内存,所以最底层的内存申请总是以2n页为单位。
get_zeroed_page(unsigned int flags);
_ _get_free_page(unsigned int flags);
#define _ _get_free_page(gfp_mask) \
_ _get_free_pages((gfp_mask),0)该函数可分配多个页并返回分配内存的首地址,分配的页数为2order,分配的页也不清零。order允许的最大值是10,这取决于具体的硬件平台。
struct page * alloc_pages(int gfp_mask, unsigned long order);//alloc_pages()可以在内核空间分配,也可以在用户空间分配。返回分配的第一个页的描述符而非首地址。
使用__get_free_page()系列函数/宏申请的内存应使用下列函数释放
void free_page(unsigned long addr);
void free_pages(unsigned long addr, unsinged long oredr);- vmalloc()
vmalloc()一般只为存在于软件中的较大的顺序缓冲区分配内存,vmalloc()远大于__get_free_pages()的开销,为了完成vmalloc(),新的页表项需要被建立。因此,只是调用vmalloc来分配少量的内存是不妥,vmalloc()使用vfree()释放。
vmalloc不能用在原子上下文中,内部使用的标志是GFP_KERNEL的kmalloc()。
vmalloc()在申请内存时,会进行内存的映射,改变页表项,不像kmalloc()实际用的是开机过程中就映射好的DMA和常规区域的页表项。因此vmalloc()的虚拟地址和物理地址不是一个简单的线性映射。
- slab与内存池
一方面,完全使用页为单元申请和释放内存容易导致浪费,一方面操作系统运作过程中,经常会涉及大量对象的重复生成、使用和释放内存问题。
slab是建立在buddy算法之上的,它从buddy算法拿到2n页面后进行二次管理。slab申请的内存以及基于slab的kmalloc()申请的内存,与物理内存之间也是一个简单的线性偏移。
- 创建缓存
struct kmem_cache *kmem_cache_create(const char *name, size_t size,
size_t align, unsigned long flags,
void (*ctor)(void*, struct kmem_cache *, unsigned long),
void (*dtor)(void*, struct kmem_cache *, unsigned long));
//kmem_cache_create()用于创建一个slab缓存,它是一个可以保留任意数目且全部同样大小的后备缓存。参数size是要分配的每个数据结构的大小,参数flags是控制如何进行分配的位掩码,包括SLAB_HWCACHE_ALIGN(每个数据对象被对齐到一个缓存行)、SLAB_CACHE_DMA(要求数据对象在DMA区域中分配)等。- 分配slab缓存
void *kmem_cache_alloc(struct kmem_cache *cachep, gfp_t flags);- 释放缓存
void kmem_cache_free(struct kmem_cache *cachep, void *objp);- 收回slab缓存
int kmem_cache_destroy(struct kmem_cache *cachep);slab缓存使用范例
/* 创建slab缓存 */
static kmem_cache_t *xxx_cachep;
xxx_cachep = kmem_cache_create("xxx", sizeof(struct xxx),
0, SLAB_HWCACHE_ALIGN|SLAB_PANIC, NULL, NULL);
/* 分配slab缓存 */
struct xxx *ctx;
ctx = kmem_cache_alloc(xxx_cachep, GFP_KERNEL);
.../* 使用slab缓存 */
/* 释放slab缓存 */
kmem_cache_free(xxx_cachep, ctx);
kmem_cache_destroy(xxx_cachep);slab在底层每次申请1页或多页,之后再分割这些页为更小的单元进行管理,从而节省了内存,也提高了slab缓冲对象的访问效率。
- 创建内存池
mempool_t *mempool_create(int min_nr, mempool_alloc_t *alloc_fn,
mempool_free_t *free_fn, void *pool_data);
typedef void *(mempool_alloc_t)(int gfp_mask, void *pool_data);
typedef void (mempool_free_t)(void *element, void *pool_data);- 分配和回收对象
void *mempool_alloc(mempool_t *pool, int gfp_mask);
void mempool_free(void *element, mempool_t *pool);- 回收内存池
void mempool_destroy(mempool_t *pool);设备IO端口以及IO内存
IO端口
- 读写字节端口(8位宽)
unsigned inb(unsigned port);
void outb(unsigned char byte, unsigned port);- 读写字端口(16端口)
unsigned inw(unsigned port);
void outw(unsigned short word, unsigned port);- 读写长字节端口(32位宽)
unsigned inl(unsigned port);
void outl(unsigned longword, unsigned port);- 读写一串字节
void insb(unsigned port, void *addr, unsigned long count);
void outsb(unsigned port, void *addr, unsigned long count);- 读写一串字
void insw(unsigned port, void *addr, unsigned long count);
void outsw(unsigned port, void *addr, unsigned long count);- 读写一串长字
void insl(unsigned port, void *addr, unsigned long count);
void outsl(unsigned port, void *addr, unsigned long count);io内存
内核访问IO内存之前,首先要使用ioremap()函数将设备所处的物理地址映射到虚拟地址上
void *ioremap(unsigned long offset, unsigned long size);ioremap()与vmalloc()类似,也需要建立新的页表,但是它并不进行vmalloc()中所执行的内存分配行为。ioremap()返回一个特殊的虚拟地址,该地址可用来存取特定的物理地址范围,这个虚拟地址位于vmalloc映射区域。通过ioremap()获得的虚拟地址应该被iounmap()函数释放.void iounmap(void *addr)
devm_opreamp()类似其他相同开口的函数,通过这个函数进行映射的通常不需要在驱动退出和出错处理的时候进行iounmap()
void __iomem *devm_ioremap(struct device *dev, resource_size_t offset, unsigned long size);设备的物理地址被映射到虚拟地址后,可以通过指针访问这些地址,但是linux内核更推荐使用一组标准的API完成设备内存映射的虚拟地址读写。
读寄存器用readb_relaxed()、readw_relaxed()、readl_relaxed()、readb()、readw()、readl()这一组API,以分别读8bit、16bit、32bit的寄存器,没有_relaxed后缀的版本与有_relaxed后缀的版本的区别是没有_relaxed后缀的版本包含一个内存屏障
写寄存器与读寄存器api相似。
IO端口申请
内核提供了一组函数用以申请和释放IO端口。
struct resource *request_region(unsigned long first, unsigned long n, const char *name);
//向内核申请N个端口,这些端口从first开始,返回NULL表示失败。
void release_region(unsigned long start, unsigned long n);io内存申请
类似于io端口申请,但是并不映射
struct resource *request_mem_region(unsigned long start, unsigned long len, char *name);
void release_mem_region(unsigned long start, unsigned long len);io端口访问的一种途径是直接使用io端口操作函数:在设备打开或驱动模块被加载时申请io端口区域,之后使用inb()、outb()等进行端口访问。
内存映射与VMA
mmap()必须以PAGE_SIZE为单位进行映射,实际上,内存只能以页为单位进行映射,若要映射非PAGE_SIZE整数倍的地址范围,要先进行页对齐,强行以PAGE_SIZE的倍数大小进行映射
int(*mmap)(struct file *, struct vm_area_struct*);
//在用户空间调用mmap的时候最终会调用上面这个驱动的mmap
//用户空间的mmap
caddr_t mmap (caddr_t addr, size_t len, int prot, int flags, int fd, off_t offset);
//fd可以填充-1,此时需指定flags参数中的MAP_ANON,表明进行的是匿名映射。
//prot参数指定访问权限,可取如下几个值的“或”:PROT_READ(可读)、PROT_WRITE(可写)、PROT_EXEC(可执行)和PROT_NONE(不可访问)当用户调用mmap()的时候,内核会进行如下处理。
1)在进程的虚拟空间查找一块VMA。
2)将这块VMA进行映射。
3)如果设备驱动程序或者文件系统的file_operations定义了mmap()操作,则调用它
4)将这个VMA插入进程的VMA链表中。file_operations中mmap()函数的第一个参数就是步骤1)找到的VMA。
驱动程序中mmap()的实现机制是建立页表,并填充VMA结构体vm_operations_struct指针。VMA就是vm_area_struct,用于描述一个虚拟内存区域。
里面有结构体起始和结束以及操作集等成员。
int remap_pfn_range(struct vm_area_struct *vma, unsigned long addr,unsigned long pfn, unsigned long size, pgprot_t prot);
//pfn是虚拟地址应该映射到的物理地址的页帧号,实际上就是物理地址右移PAGE_SHIFT位。若PAGE_SIZE为4KB,则PAGE_SHIFT为12,因为PAGE_SIZE等于1<<PAGE_SHIFT通常io内存被映射需要是nocache,需要对vma->vm_page_port设置nocache标志
static int xxx_nocache_mmap(struct file *filp, struct vm_area_struct *vma)
{
vma->vm_page_prot = pgprot_noncached(vma->vm_page_prot);/* 赋nocache标志 */
vma->vm_pgoff = ((u32)map_start >> PAGE_SHIFT);
/* 映射 */
if (remap_pfn_range(vma, vma->vm_start, vma->vm_pgoff, vma->vm_end - vma
->vm_start, vma->vm_page_prot))
return -EAGAIN;
return 0;
}
//arm下面
#define pgprot_noncached(prot) \
__pgprot_modify(prot, L_PTE_MT_MASK, L_PTE_MT_UNCACHED)noncached()禁止了相关页的cache和写缓冲,pgprot_writecombine()没有禁止写缓冲。
#define pgprot_writecombine(prot) \
__pgprot_modify(prot, L_PTE_MT_MASK, L_PTE_MT_BUFFERABLE)ARM的写缓冲是一个非常小的FIFO存储器,在处理器核和主存之间。写缓冲区与Cache在存储层次上处于同一层次,但是它只作用于写主存。
处理remap_pfn_range()以外,在驱动程序中实现VMA的fault()函数通常为设备提供更加灵活的内存映射途径。
访问的页不在内存里,即发生缺页异常时,fault()会被内核自动调用,而fault()的具体行为可以自定义。
当缺页异常发生时:
- 找到缺页的虚拟地址所在VMA
- 如果必要,分别中间页目录表和页表
- 如果页表项对应的物理页面不存在,调用这个VMA的fault()方法,它返回物理页面的页描述符
- 将物理页面的地址填充到页表中
静态映射 建立外设I/O内存物理地址到虚拟地址的静态映射,这个映射通过在与电路板对应的map_desc结构体数组中添加新的成员来完成
struct map_desc {
unsigned long virtual; /* 虚拟地址 */
unsigned long pfn ; /* __phys_to_pfn(phy_addr) */
unsigned long length; /* 大小 */
unsigned int type; /* 类型 */
};DMA
如果DMA目标地址和Cache缓存的内存地址之间有所重叠,DMA操作,Cache中的对应数据已经过时,但是CPU不知情,使用Cache中过时的数据,会产生Cache与内存不一致问题。
DMA是一种外设与内存交互数据的方式。内存中用于与外设交互数据的一块区域称为DMA缓冲区,在设备不支持scatter/gather(分散/聚集,简称SG)操作的情况下,DMA缓冲区在物理上必须是连续的。
- DMA区域
对于x86系统的ISA设备而言,其DMA操作只能在16MB以下的内存中进行,因此,在使用kmalloc()、__get_free_pages()及其类似函数申请DMA缓冲区时应使用GFP_DMA标志,这样能保证获得的内存位于DMA区域中,并具备DMA能力。
在内核中定义了__get_free_pages()针对DMA的“快捷方式”__get_dma_pages(),它在申请标志中添加了GFP_DMA
#define _ _get_dma_pages(gfp_mask, order) \
__get_free_pages((gfp_mask) | GFP_DMA,(order))还可以使用dma_mem_alloc()进行申请,这个函数可以不用指数进行申请而是用大小
static unsigned long dma_mem_alloc(int size)
{
int order = get_order(size); /* 大小->指数 */
return _ _get_dma_pages(GFP_KERNEL, order);
}基于DMA的硬件使用的是总线地址而不是物理地址,总线地址是从设备角度上看到的内存地址,物理地址是从CPU MMU控制器外围角度上看到的内存地址。
有时候总线地址会通过桥接电路连接,桥接电路会将IO地址映射为不同的物理地址
例如,在PReP(PowerPC Reference Platform)系统中,物理地址0在设备端看起来是0x80000000,而0通常又被映射为虚拟地址0xC0000000,所以同一地址就具备了三重身份:物理地址0、总线地址0x80000000及虚拟地址0xC0000000。还有一些系统提供了页面映射机制,它能将任意的页面映射为连续的外设总线地址。
例如有如下函数:
unsigned long virt_to_bus(volatile void *address);
void *bus_to_virt(unsigned long address);
//进行简单的虚拟地址、总线地址转换在使用IOMMU或反弹缓冲区的情况下,上述函数一般不会正常工作。而且,这两个函数并不建议使用。由于IOMMU可以使得外设DMA引擎看到“虚拟地址”,因此在使用IOMMU的情况下,在修改映射寄存器后,可以使得SG中分段的缓冲区地址对外设变得连续。
DMA掩码
设备会存在有些内存地址可能不能执行DMA操作
int dma_set_mask(struct device *dev, u64 mask);
//这个API本质就是修改device结构体中的dma_mask成员在device结构体中,除了有dma_mask以外,还有一个coherent_dma_mask成员。dma_mask是设备DMA可以寻址的范围,而coherent_dma_mask作用于申请一致性的DMA缓冲区。
DMA映射包括两个方面的工作:分配一片DMA缓冲区;为这片缓冲区产生设备可访问的地址。同时,DMA映射也必须考虑Cache一致性问题
void * dma_alloc_coherent(struct device *dev, size_t size, dma_addr_t *handle, gfp_t gfp);
//申请函数还有像dma_free_coherent、dma_alloc_writecombine
pci设备申请DMA缓冲区的函数pci_alloc_consistent()
void * pci_alloc_consistent(struct pci_dev *pdev, size_t size, dma_addr_t *dma_addrp);
当coherent_dma_mask小于0xffffffff时,才会设置GFP_DMA标记,并从DMA区域去申请内存,意识是申请函数并不一定在DMA区域
相对于一致性DMA映射而言,流式DMA映射的接口较为复杂。对于单个已经分配的缓冲区而言,使用dma_map_single()可实现流式DMA映射。
dma_addr_t dma_map_single(struct device *dev, void *buffer, size_t size,
enum dma_data_direction direction);
//映射成功返回总线地址,第四个参数是DMA方向DMA_TO_DEVICE、DMA_FROM_DEVICE、DMA_BIDIRECTIONAL和DMA_NONE
void dma_unmap_single(struct device *dev, dma_addr_t dma_addr, size_t size,
enum dma_data_direction direction);通常情况下,设备驱动不应该访问unmap的流式DMA缓冲区,如果一定要这么做,可先使用如下函数获得DMA缓冲区的拥有权
void dma_sync_single_for_cpu(struct device *dev, dma_handle_t bus_addr,
size_t size, enum dma_data_direction direction);在驱动访问完DMA缓冲区后,应该将其所有权返还给设备,这可通过如下函数完成
void dma_sync_single_for_device(struct device *dev, dma_handle_t bus_addr,
size_t size, enum dma_data_direction direction);如果设备要求较大的DMA缓冲区,在其支持SG模式的情况下,申请多个相对较小的不连续的DMA缓冲区通常是防止申请太大的连续物理空间的方法
int dma_map_sg(struct device *dev, struct scatterlist *sg, int nents,
enum dma_data_direction direction);nents是散列表(scatterlist)入口的数量,该函数的返回值是DMA缓冲区的数量,可能小于nents。对于scatterlist中的每个项目,dma_map_sg()为设备产生恰当的总线地址,它会合并物理上临近的内存区域。
dma_addr_t sg_dma_address(struct scatterlist *sg);
unsigned int sg_dma_len(struct scatterlist *sg);执行dma_map_sg()后,通过sg_dma_address()可返回scatterlist对应缓冲区的总线地址,sg_dma_len()可返回scatterlist对应缓冲区的长度
SG映射属于流式DMA映射,与单一缓冲区情况下的流式DMA映射类似,如果设备驱动一定要访问映射情况下的SG缓冲区,应该先调用如下函数
void dma_sync_sg_for_cpu(struct device *dev, struct scatterlist *sg,
int nents, enum dma_data_direction direction);访问完成之后也要通过如下函数将所有权返回
void dma_sync_sg_for_device(struct device *dev, struct scatterlist *sg,
int nents, enum dma_data_direction direction);在Linux系统中可以用一个相对简单的方法预先分配缓冲区,那就是同步“mem=”参数预留内存。例如,对于内存为64MB的系统,通过给其传递mem=62MB命令行参数可以使得顶部的2MB内存被预留出来作为I/O内存使用,这2MB内存可以被静态映射,也可以被执行ioremap()。
标准API
Linux内核目前推荐使用dmaengine的驱动架构来编写DMA控制器的驱动,同时外设的驱动使用标准的dmaengine API进行DMA的准备、发起和完成时的回调工作。
struct dma_chan *dma_request_slave_channel(struct device *dev, const char *name);
struct dma_chan *__dma_request_channel(const dma_cap_mask_t *mask,
dma_filter_fn fn, void *fn_param);//使用DMA前,设备驱动程序首先向dmaengine系统申请DMA通道
//使用完成通道后
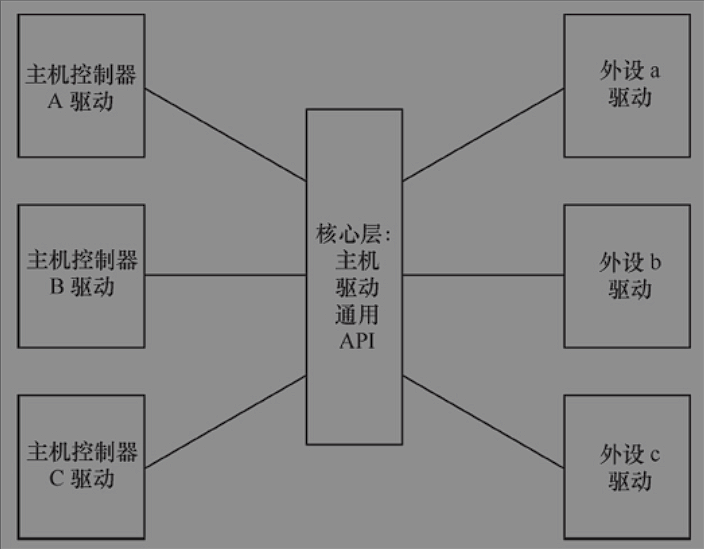
void dma_release_channel(struct dma_chan *chan);软件架构
struct platform_device {
const char *name;
int id;
boo id_auto;
struct devicedev;
u32 num_resources;
struct resource *resource;
const struct platform_device_id *id_entry;
char *driver_override; /* Driver name to force a match */
/* MFD cell pointer */
struct mfd_cell *mfd_cell;
/* arch specific additions */
struct pdev_archdata archdata;
};
//platform_driver这个结构体中包含probe()、remove()、一个device_driver实例、电源管理函数suspend()、resume(),
struct platform_driver {
int (*probe)(struct platform_device *);
int (*remove)(struct platform_device *);
void (*shutdown)(struct platform_device *);
int (*suspend)(struct platform_device *, pm_message_t state);
int (*resume)(struct platform_device *);
struct device_driver driver;
const struct platform_device_id *id_table;
bool prevent_deferred_probe;
};
//新的做法是实现platform_driver的device_driver的dev_pm_ops结构体成员
//与platform_driver地位对等的i2c_driver、spi_driver、usb_driver、pci_driver中都包含了device_driver结构体实例成员。它其实描述了各种xxx_driver(xxx是总线名)在驱动意义上的一些共性platform总线定义了一个bus_type的实例platform_bus_type
struct bus_type platform_bus_type = {
.name = "platform",
.dev_groups = platform_dev_groups,
.match = platform_match,
.uevent = platform_uevent,
.pm = &platform_dev_pm_ops,
};一是基于设备树风格的匹配;二是基于ACPI风格的匹配;三是匹配ID表(即platform_device设备名是否出现在platform_driver的ID表内);第四种是匹配platform_device设备名和驱动的名字。
为完成将globalfifo移植到platform驱动的工作,需要在原始的globalfifo字符设备驱动中套一层platform_driver的外壳。
struct resource {
resource__size_t start;
resource_size_t end;
const char *name;
unsigned long flags;
struct resource *parent, *sibling, *child;
};我们通常关心start、end和flags这3个字段,它们分别标明了资源的开始值、结束值和类型,flags可以为IORESOURCE_IO、IORESOURCE_MEM、IORESOURCE_IRQ、IORE-SOURCE_DMA等。
使得设备被挂接在一个总线上,符合Linux 2.6以后内核的设备模型。其结果是使配套的sysfs节点、设备电源管理都成为可能
隔离BSP和驱动。在BSP中定义platform设备和设备使用的资源、设备的具体配置信息,而在驱动中,只需要通过通用API去获取资源和数据,做到了板相关代码和驱动代码的分离,使得驱动具有更好的可扩展性和跨平台性
让一个驱动支持多个设备实例。譬如DM9000的驱动只有一份,但是我们可以在板级添加多份DM9000的platform_device,它们都可以与唯一的驱动匹配
y有一些字符设备无法准确辨别其类型,可以采用miscdevice框架结构。miscdevice本质上也是字符设备,只是在miscdevice核心层的misc_init()函数中,通过register_chrdev(MISC_MAJOR,"misc",&misc_fops)注册了字符设备,而具体miscdevice实例调用misc_register()的时候又自动完成了device_create()、获取动态次设备号的动作。
miscdevice的主设备号是固定的,MISC_MAJOR定义为10。miscdevice结构体里面有一个file_operations的结构体,miscdevice结构体内的file_operations中的成员函数实际上是有deriver/char/misc.c中misc驱动核心层的misc_fops成员函数间接调用的,比如misc_open()就会间接调用底层注册的miscdevice的fops->open
struct miscdevice {
int minor;
//如果上面为MISC_DYNAMIC_MINOR,会自动找一个空闲的次设备号,否则用minor指定的次设备号
const char *name;
const struct file_operations *fops;
struct list_head list;
struct device *parent;
struct device *this_device;
const char *nodename;
umode_t mode;
};驱动核心层
核心层有三大责任:
- 对上提供接口,file_operations的读、写、ioctl都被中间层处理
- 中间层实现通用逻辑,可以被底层各种实例共享的代码都被中间层搞定,避免底层重复实现。
- 对下定义框架,底层的驱动不再需要关心linux内核VFS的接口以及各种可能的IO模型,只需要处理与硬件相关的访问。
Linux的SPI、I2C、USB等子系统都利用了典型的把主机驱动和外设驱动分离的想法,让主机端只负责产生总线上的传输波形,而外设端只是通过标准的API让主机端以适当的波形访问自身。
- 主机端的驱动。根据具体的I2C、SPI、USB等控制器的硬件手册,操作具体的I2C、SPI、USB等控制器,产生总线的各种波形。
- 连接主机和外设的纽带,外设不直接调用主机端的驱动来产生波形,而是调用标准API。
- 外设端的驱动。外设接在I2C、SPI、USB这样的总线上,但是它们本身是触摸屏、网卡、声卡或者任意一种类型的设备。
- 板级逻辑,板级逻辑用来描述主机和外设是如何互联的,相当于路由表。
LINUX SPI主机和设备驱动
spi_master结构体可以用来描述一个SPI主机控制器驱动,主要的成员是主机控制器的序号、片选数量、SPI模式、时钟设置用到的和数据传输用到的函数。
像分配、注销、注册SPI主机的API由SPI核心提供。
spi_driver结构体用来描述一个SPI外设驱动。
probe()、remove()、suspend()、resume()这样的接口几乎是一切客户端驱动的常用模板。
在SPI外设驱动中,当通过SPI总线进行数据传输的时候,使用了一套与CPU无关的统一的接口。这套接口的第1个关键数据结构就是spi_transfer,它用于描述SPI传输。
一次完整的SPI传输流程可能不是只包含一次spi_transfer,可能包含一个或多个spi_transfer,这些spi_transfer最终通过spi_message组织在一起。
spi_message的传输有同步和异步两种方式,使用同步API,会阻塞到处理完成
int spi_sync(struct spi_device *spi, struct spi_message *message);使用异步API时,不会阻塞等待这个消息被处理完,但是可以在spi_message的complete字段挂接一个回调函数,当消息被处理完成后,该函数会被调用。
int spi_async(struct spi_device *spi, struct spi_message *message);设备树语法
&mcspi1 {
pinctrl-names = "default";
pinctrl-0 = <&mcspi1_pins>;
/* touch controller */
ads7846@0 {
pinctrl-names = "default";
pinctrl-0 = <&ads7846_pins>;
compatible = "ti,ads7846";
vcc-supply = <&ads7846reg>;
reg = <0>; /* CS0 */
spi-max-frequency = <1500000>;
interrupt-parent = <&gpio4>;
interrupts = <180>; /* gpio_114 */
pendown-gpio = <&gpio4 180>;
ti,x-min = /bits/ 16 <0x0>;
ti,x-max = /bits/ 16 <0x0fff>;
ti,y-min = /bits/ 16 <0x0>;
ti,y-max = /bits/ 16 <0x0fff>;
ti,x-plate-ohms = /bits/ 16 <180>;
ti,pressure-max = /bits/ 16 <255>;
linux,wakeup;
};
};输入设备驱动
字符设备、动作触发中断(或驱动通过TIMER定时查询),然后通过SPI、I2C或外部存储总线读取键值、坐标等数据,放入缓冲区,字符设备管理驱动负责管理,驱动的read()接口让用户获取键值、坐标等。
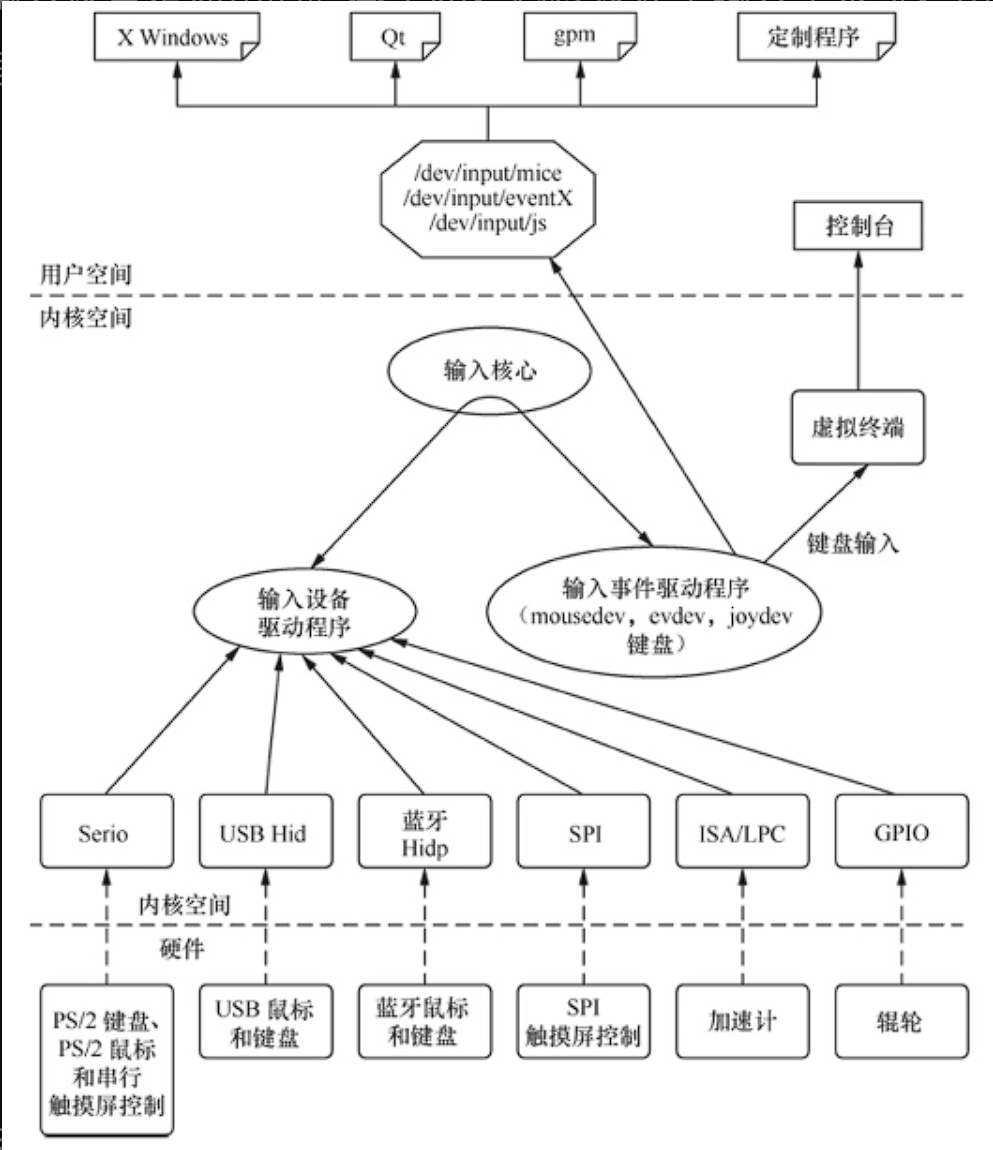
//输入核心层提供了底层输入设备驱动需要的api
struct input_dev *input_allocate_device(void);
void input_free_device(struct input_dev *dev);
int __must_check input_register_device(struct input_dev *);
void input_unregister_device(struct input_dev *);
/* 报告指定type、code的输入事件 */
void input_event(struct input_dev *dev, unsigned int type, unsigned int code, int value);
/* 报告键值 */
void input_report_key(struct input_dev *dev, unsigned int code, int value);
/* 报告相对坐标 */
void input_report_rel(struct input_dev *dev, unsigned int code, int value);
/* 报告绝对坐标 */
void input_report_abs(struct input_dev *dev, unsigned int code, int value);
/* 报告同步事件 */
void input_sync(struct input_dev *dev);RTC设备驱动
RTC借助电池供电,在系统掉电情况下依然可以正常计时。
周期性中断以及闹钟中断的能力,是一种典型的字符设备。
drivers/rtc/rtc-dev.c实现了RTC驱动通用的字符设备驱动层,它实现了file_opearations的成员函数以及一些通用的关于RTC的控制代码,并向底层导出rtc_device_register()、rtc_device_unregister()以注册和注销RTC;导出rtc_class_ops结构体以描述底层的RTC硬件操作
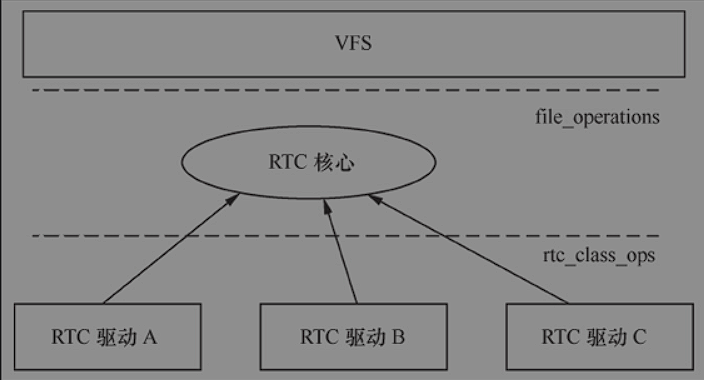
FRAMEBUFFER设备驱动
framebuffer(帧缓冲)是Linux系统为显示设备提供的一个接口,将显示缓冲区抽象,屏蔽图像硬件的底层差异,允许上层应用程序在图形模式下,直接对显示缓冲区进行读写操作。
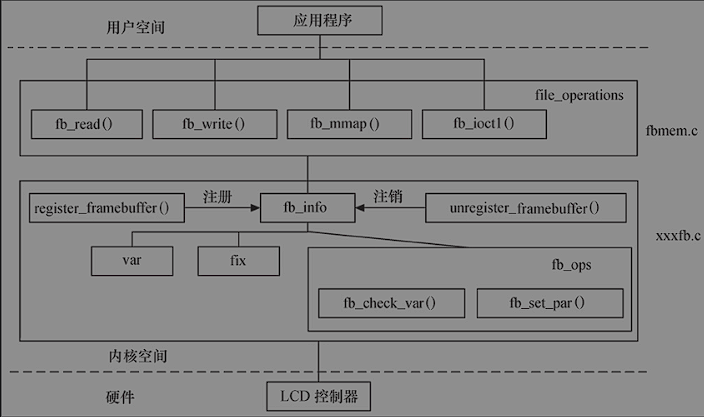
如果在遇到一些显存写法特殊的情况,核心层drivers/video/fbdev/core/fbmem.c实现的fb_write()中,给底层提供了一个重写自己的机会。
misc设备驱动
miscdevice本质上也是字符设备,只是在miscdevice核心层的misc_init()函数中,通过register_chrdev(MISC_MAJOR,"misc",&misc_fops)注册了字符设备,而具体miscdevice实例调用misc_register()的时候又自动完成了device_create()、获取动态次设备号的动作。
主设备号固定是10。
static const struct file_operations xxx_fops = {
.unlocked_ioctl = xxx_ioctl,
.mmap = xxx_mmap,
…
};
static struct miscdevice xxx_dev = {
.minor = MISC_DYNAMIC_MINOR,
.name = "xxx",
.fops = &xxx_fops
};
static int __init xxx_init(void)
{
pr_info("ARC Hostlink driver mmap at 0x%p\n", __HOSTLINK__);
return misc_register(&xxx_dev);
}在调用misc_register(&xxx_dev)时,该函数内部会自动调用device_create(),而device_create()会以xxx_dev作为drvdata参数。其次,在miscdevice核心层misc_open()函数的帮助下,在file_operations的成员函数中,xxx_dev会自动成为file的private_data(misc_open会完成file->private_data的赋值操作)。