
并发实战
c++并发编程实战
线程相关的知识
线程的操作
c++11背景下面的线程api
std::thread
#include<thread>
std::thread my_thread(do_some);
//参数传入可调用参数类型
class back_ground
{
public:
void operator() ()const
{
do_something();
}
}std::thread my_thread((back_ground()))//通过双重括号避免声明为函数的问题
std::thread my_thread{back_ground()}//可以通过大括号形式避免该问题
//lambda表达式也能解决这个问题
[]{}detach()、join、joinable
struct func;
void f()
{
int loacl_state=0;
func my_func(local_state);
std::thread t(my_func);
try
{
do_something_in_current_thread();
}
ctach(...)
{
t.join();
throw;
}
t.join();
}
//保证主线程即使出错,也能等待子线程结束再结束
//可以使用RAII的思想在创建一个类封装一个线程,在析构函数中释放线程,因为不管有没有抛出异常,栈上的类对象也是可以在推出抛出后销毁的
~threaad_guard(){
if(t.joinable())
{
t.join();
}
}detach之后成为守护进程:一般守护进程是一个完全独立的个体,比如多窗口下的单独窗口的设计,将启动一个窗口作为一个函数,每次点开窗口就创建这个线程并且把线程分离。
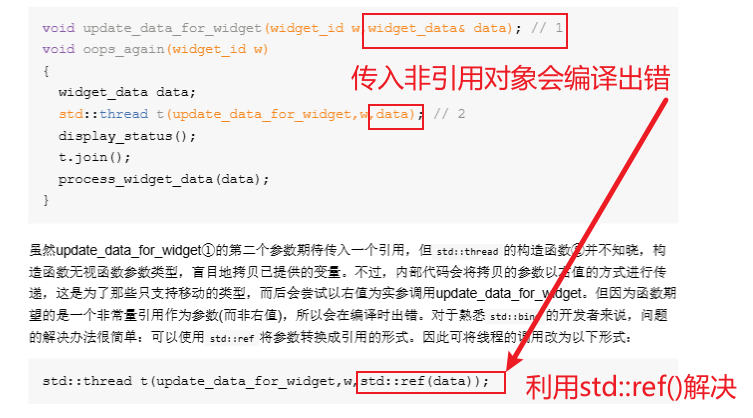
对于不可拷贝的类型可以使用std::move作为参数进行传递。
**所有权转移:**线程允许移动,一个线程只能同时拥有一个单位,如果一个线程已经有一个正在运行的线程,此时再通过移动给其赋值,会出现std::terminate()终止程序,并不会抛出异常。
thread的一些探究: scoped_thread:可以把线程作为参数,并确保线程是可以释放的线程、后续有std::jthread
自动化创造线程的可以使用vector存储thread,然后emplace_back()可以传入线程创建需要仿函数以及参数,就可以直接在vector上面构造
线程数量的确定:
std::thread::hard_concurrency():可以返回并发线程额数量,如果无法返回的时候就会返回0
线程的标识:stdid 有两种方式检索,stdthread没有关联数据就会返回std::thread::type的默认构造函数,这个返回值表示“无线程”。第二种,当前线程std::this_thread::get_id()
std::thread::id可以对比,作为例如set< stdid >的键值
共享数据
恶性竞争 不变量遭到修改,并发的修改就会有恶性竞争。
方法一:保证只有修改线程才能看到不变量的中间状态(保护机制,锁机制和条件变量)
方法二:保证数据结构和不变量能完成一系列不可分割的变化,就是无锁编程。(开销大)
方法三:利用事务的方式进行处理更新,所需的操作保存在日志之中,让后将操作进行合并统一一次性修改。(STM)软件事务内存,如果在数据结构被另一个线程修改之后,或者已经重启的情况下,提交无法进行。
互斥量:
std::mutex具有成员函数lock(),更好的有如下一些函数
#include<mutex>
//RAII的思想管理互斥量
std::lock_gurard<std::mutex> lock(some_mutex);//并不支持手动释放
//c++17提供了一些优化语法,当互斥量的类型简单时候可以直接std::lockguard lock(some_mutex),这是一种模版推导机制
std::unique_lock<std::mutex> lock(some_mutex);//可以手动释放可以自动释放互斥量并非绝对安全的,通过指针或者引用可以让保护的内容被修改,所以尽量不要在有锁的时候调用其他函数。
即使有互斥量,条件竞争也是存在的比如多线程下的栈结构判空和size()函数这是基于接口的条件竞争。
对于接口的比如pop()和top()的条件竞争,可以使用合二为一的方法解决,但是此时pop()需要进行拷贝,并且是深拷贝,可能存在空间大小不够抛出异常std::bad_alloc
解决办法:
1、将变量引用作为参数,传入pop()获取弹出值:缺点资源消耗,且受到类型定义的限制,有些类型不支持赋值
2、采用无异常抛出的拷贝构造或移动构造函数:缺点std::is_nothrow_copy_constructible和std::is_nothrow_move_constructible局限太大,因为往往有些类型需要抛出异常,这样的栈结构就不能具有泛用性。
3、返回指向弹出值的指针,对弹出数据进行处理放到堆上并用shared_ptr进行托管,通过enable_shaerd_from_this进行返回,这种方案的开销巨大。
4、采用上述几种方式组合的情况。

#include<exception>
#include<memory>
#include<mutex>
#Include<stack>
//继承自std::exception 并重写了exception的what()函数并且声明为noexcept即不抛出错误类型
struct empty_stack :std::exception
{
cosnt char* what() const noexcept override
{
return "empty stack!\n"
}
}
templa <typename T>
class threadsafe_stack
{
private:
std::stack<T> data;
mutable std::mutex m;
public:
//无参构造
threadsafe_stack()
:data(std::stack<t> ()){}
//拷贝构造函数,需要对被拷贝对象加锁
threadsafe_stack(const threadsafe_stack& other)
{
std::lock_guard<std::mutex> lock(other.m);
data = other.data;
}
//删除对象的赋值
threadsafe_stack & operator =(const threadsafe_stack&) =delete;
//放入栈
void push(T new_vale)
{
std::lock_guard<std::mutex> lock(m);
data.push(new_value);
}
std::shared_ptr<T> pop()
{
std:lock_gurard<std::mutex> lock(m);
if(data.empty()) throw empty_stack();
std::shared_ptr<T> const res(std::make_shared<T>(data.top()));
data.pop();
return res;
}
void pop(T& value)
{
std::lock_guard<std::mutex> lock(m);
if(data.empty()) throw rmpty_stack();
value = data.top();
data.pop();
}
bool empty() const
{
std::lock<std::mutex> lock(m);
return data.empty();
}
};大名鼎鼎的死锁,也就是哲学家就餐问题:
成因:互斥、占有、不可抢占、循环访问
一些解决锁的互斥的解决办法:
std::lock(std::mutex,std::mutex);
std::lock_guard<std::mutex>(std::mutex,std::adopt_lock);
//c++17
std::scoped_lock<std::mutex,std::mutex> //c++17允许的一种类型推导方法,支持对传递给的互斥量同时上锁,并且在析构函数钟释放,这是一种RAII的模式,可以替代上面两步做法的叠加
//避免死锁的升级:避免使用嵌套锁,比如不要依次获得锁,如果非要如此,优先通过lock去锁住之后再进行
//在持有锁的时候避免调用函数和外部代码
//通过保证锁创建的顺序一致性,比如双端链表,为了减少锁的粒度,通过对前后本节点进行加锁来操作,但是要保证避免的顺序一致性,避免访问每个节点访问的锁的顺序不一致
//使用层次锁的结构,加锁前检查每个互斥量对应的层数,以及每个线程使用的互斥量,检查枷锁操作是否可以进行。
//层次锁的示例
hierarchical_mutex high_level_mutex(10000);//1
hierachical_mutex low_level_mutex(5000);//2
hierarchical_mutex other_mutex(6000);//3
int do_low_level_stuff();
int low_level_func()
{
std::lock_guard<hierarchical_mutex> lk(low_level_mutex);//4
return do_low_level_stuff();
}
void high_level_stuff(int some_param);
void high_level_func()
{
std::lock_guard<hierarchial_mutex>lk(high_level_mutex);//6
high_level_stuff(low_level_func());//5
}
void thread_a ()//7
{
high_level_func();
}
void do_other_stuff();
void do_other_stuff()
{
high_level_func();//10
do_other_stuff();
}
void thread_b()//8
{
std::lock_guard<hierarchical_mutex> lk(other_mutex);//9
other_stuff();
}
//hieraachical_mutex 创建了三个实例,通过逐层递减进行构造,如果hierachical_mutex 上锁那么只能获取低层锁。
//意思是如果在high_level_func 调用 low_level_func 是可以允许通过的因为他锁的层次更加的高,如果层级一样不能同时持有多个锁。
//这hierarchical_mutex 实现在上锁的时候都会进行层级的判断std::unique_lock
这个代价相对于lock_guard 的开销更大,但是允许示例不带互斥量。
stdadopt_lock
锁的粒度:
粗粒度的锁性能不好,但是细粒度的锁需要考虑的是并发访问状态下值在读取后的一瞬间就被修改的情况。
一种存粹保护共享数据初始化的机制:
延迟初始化:在初始化之前进行判断,转换为多线程代码的时候要注意:
std::shared_ptr<some_resource> resource_ptr;
void foo()
{
if(!resource_ptr)//1
{
std::unique_lock<std::mutex> lk(resource_mutex);//所有线程在这里进行序列化
if(!resource_ptr)
{
resource_ptr.reset(new some_resource);//当是多线程代码的时候需要对这个地方进行保护
}
//引入互斥量
}
resource_ptr->do_something();
}
//但是这个模式有问题,问题在于存在潜在的条件竞争,因为在1处的时候可以,此时的状态可能被其他些写的线程影响。引入了stdcall_once(可以安全的检测指针是否被其他线程修改,这样进行初始化),使用std::call_once 相较于显式使用互斥量开销更加小,特别是初始化完成之后。
std::shared_ptr<some_resource> resource_ptr;
std::once_flag resource_flag; //1
void init_resource()
{
resource_ptr.reset(new some_resource);
}
void foo()
{
std::call_once(resource_flag,init_resource);//可以完整的一次初始化 resource_ptr->do_something();
}
初次调用send_data和data_packet 完成初始化过程,静态成员变量也会村寨这种问题在c++11之后,这问题被解决,因为c++11规定所有的初始化以及定义完全发生在一个线程中,;并没有其他线程可以在初始化完成之前对其进行处理。
保护不常更新的数据结构,采用读写锁(比如DNS表的更新处理)
c++17中支持了两非常好的互斥量----std::shared_mutex和std::shared_timed_mutex,c++14只提供了std::shared_timed_mutex,而c++11就需要采用boost库提供的互斥量,shared_timed_mutex的操作方式更多,但是std::shared_mutex性能更好。
只要有一个非独占锁被锁住,那么所有的请求独占锁的线程就会被阻塞,但是非独占锁的请求不会受到限制,等所有其他的线程释放了非独占锁之后,才能拥有独占锁,拥有独占锁其他所有线程不能拿到任何锁,只有独占锁才能允许写操作。
非更新操作使用stdunique_lock<>()/std::lock_guard<>()
std::recursive_mutex类可以对同一个实例多次上锁,使用嵌套锁可以用在并发访问的类,使用互斥量保护其成员数据
同步操作
形式上表现为conditon \variables,future添加了许多新操作,并且可以和新工具,latches(轻量级锁资源)和barriers(栅栏)
等待事件或者条件
通过引入条件变量避免设置一个共享数据标志位来持续判断事件的就绪情况降低运行效率,尽管这个可以加上sleep_for()减少系统的开销,但是有一个更加优秀的方法那就是使用c++标准库里面的条件变量
等待条件达成
std::conditon_variable\ std::condition_variable-any两个条件变量,在互斥量的结合下就可以一起工作,前者只能和std::mutex工作,而后者se可以和合适的互斥量进行工作,但是在性能上的开销更大。通常选择的是第一个。
//condition.wait(mutex,verb(谓词))
//通过创建一个条件变量线程入口等待被条件变量唤醒并加入防备虚假唤醒机制,然后让一个线程结束的时候使用notify_one ,或者使用notify_all().
//tips:这个地方使用unique_lock的原因是因为要让锁拥有自动解锁的能力。构建线程安全队列
//类似实现了生产者消费者模式
//也存在条件竞争的问题
#include<queue>
#include<memory>
#include<mutex>
#include<condition_variable>
template<typename T>
class threadsafe_queue()
{
private:
mutable std::mutex mut;
std::queue<T>data_queue;
std::condition_variable data_cond;
public:
threadsafe_queue(threadsafe_queue const& other)
{
std::lock_fuard<std::mutex>lk(other.mut);
data_queue=other.data_queue;
}
void push(T new_value)
{
std::lock_guard<std::mutex> lk(mut);
data_queue.push(new_value);
data_cond.notify_one();
}
void wait_and_pop(T& value)
{
std::unique_lock<std::mutex> lk(mut);
data_cond.wait(lk,[this]{return !datra_queue.emoty();});
std::shared_ptr<T> res(std::make_shared<T> (data_queue.front()));
data_queue.pop();
return res;
}
std::shared_ptr<T> wait_and_pop()
{
std::unique_lcok<std::mutex> lk(mut);
data_cond.wait(lk,[this]{return !data_queue.empty();});
data_queue.pop();
return res;
}
bool try_pop(T& value)
{
std::lock_guard<std::mutex> lk(mut);
if(data_queue.empty())
return false;
value =data_queue.front();
data_queue.pop();
return true;
}
std::shared_ptr<T> try_pop()
{
std::lock_guard<std::mutex> lk(mut);
if(data_queue.empty())
{
return std::shared_ptr<T>();
}
std::shared_ptr<T> res(std::make_shared<T> (data_queue.front()));
data_queue.pop();
return res;
}
bool empty() const
{
std::lock_guard<std::mutex> lk(mut);
return data_queue.empty();
}
}future
与std::unique_ptr相似
这个可以同多个事件关联,这个接管的所有实例会在同一时间变为就绪。
所有模板参数都是相关类型。
当多个线程对一个std::shared_future<>副本进行访问的时候,即使用同一个异步结果,也不需要同步future。
这个只能与特定事件相关联,与数据无关只想执行任务可以用特化模板,std::future\<void \>,std::shared_future\<void\>,当多个线程同时访问一个独立future的时候也需要用互斥锁来保护。
这个是并行技术规范所扩展的,将来可能会扩展到标准里面。
在< future > 下面有一个stdfuture对象,这个对象里面存储的就是这个异步任务处理的数值,如果需要拿到这个数值,可以调用==get()==成员函数。
#include<future>
#include<iostream>
int find_the_answer_to_ltuae();
void do_other_stuff();
int main()
{
std::future<int>
//函数允许传入可调用参数类型并且给于参数。
thr_answer=std::async(find_the_ansert_to_ltuae);
do_other_stuff();
std::cout<<"The answer is "<<the_answer.get()<<std::endl;
}
#Include<string>
#include<future>
struct X
{
void foo(int,std::string const& );
std::string bar(str::string const &);
};
X x;
auto f1= std::async(&x::foom,&x,42,"hello");
auto f2= std::async(&X::bar,x,"goodbye");//这个是拷贝副本
struct Y
{
double operator()(double);
}
Y y;
auto f3 = std::async(Y(),3.14);//这个调用了移动构造创造了temp
auto f3 = std::async(std::red(y),2.718);//直接调用了本身
X baz(X&);
std::asynv(baz,std::red(x));
clss move_only
{
pinlic:
move_only();
nove_only(move_only&&);
move_only(move_only const & )=delete;
mocw_only& operator=(move_only&&);
move_only& operator==(move_only const & )=delete;
void operator()();
}
auto fs=std::async(move_only());//首先move_only()创建一个临时的对象,然后通过std::move进行构造的tmp,并调用tmp();//这个std::launch::async表示这函数必须在独立线程上面执行,std::launch::deferred,如果采用std::launch::deferred就表明这个函数必须要在延迟到调用wait()或者get()函数的时候再执行。
auto f6 = std::async(std::launch::async,Y(),1.2);
auto f7 = std::async(std::launch::deferred,baz,std::ref(x));// 等待调用wait(),get()的时候再执行。
auto f8 = std::async(std::launch::deferred | std::launch::async,baz ,std::ref(x));//实现自己选择执行方式
auto f9 = std::async(baz,std::ref(x));
f7.wait();备注
之后还会有stdpackage_task<>的高抽象模式.
std::package_task\<\>会将std::future<>与函数或者可调用对象进行绑定,当调用std::package_task\<\>的时候就会执行相关函数或者可调用对象,并返回存储值。 比如在线程池中实现对于粗粒度任务的分割以及抽象。 这个std::package_task\<\>返回值是std::future\<\>template<> class packaged_task<std::string(std::vector<char>*,int)> { public: template<typename callable> std::future<std::string> get_future(); void operator()(std::vector<char>*,int); } //package_task本身又可以作为一个可调用参数,可以以这个作为线程入口函数,然后适当时候拿回future里面的内容

注解
std::packaged_task\<void()\>创建任务,包含了一个无参无返回值的函数,或者可调用对象,当这个函数有返回值的时候,返回值将被丢弃,std::package_task\<\>可以给定不同的函数签名作为模版参数,可以改变其返回类型,也可以改变函数操作符的参数类型。
promise & packaged_task
std::promise
例子
在处理大量网络连接的时候,如果使用多线程去处理链接并不合适,因为线程频繁的上下文切换会造成较大开销。(极端情况下会消耗完所有的系统资源) 优秀的方法应该是少量的线程,允许一个线程同时处理多个链接。这里面引入stdpromise\<T> 提供设定值的方法,future可以阻塞等待线程,提供数据的线程可以使用promise对相关值进行设置,并且修改future的状态。
#include<future>
void process_connections(connection_set& connections)
{
while(!done(connextions))//每次循环检查链接
{
for(connection_iterator
connection = connections.begin(),end = connections.end();
connextion!=end;
++connection)//依次检索链接
{
if(connection->has_incoming_data())//检索是否有数据
{
data_packet data = connection->incoming;
std::promise<payload_type>& p =
connection->get_promise(data.id);//映射id
p.set_value(data.payload);
}
if(connection->has_outgoing_queue())//是否有传出数据
{
outgoing_packet data =
connection->top_of_outgoind_queue();
conection->send(data.payload);
data.promise.set_value(true);
}
}
}
//这个代码id作为promise映射(比如vector的下标),利用set_value更新data
//有个小问题,这个问题并没有进行检错,需要报告当系统磁盘空间不足或者说网络环境波动,数据库异常的时候可能产生的错误进行报告。double square_root (double root )
{
if(x<0)
{
throw std::out-of_range("x<0");
}
return sqrt(x);
}
//采用异步调用的方式
std::future<double> f=std::async(square_root,-1);
double y =f.get();
//标准没有指定存储的抛出对象是原始对象还是拷贝,根据编译器不多有所区别,
//这个地方在打包函数会抛出异常,get()之后还会再次抛出异常。
//同样采用std::promise 也是可以的,但是这个地方给promise的是set_exception
extern std::promise<double> some_promise;
try
{
some_promise.set_value(calculate_value());
}
catch (...)
{
some_promise.set_exception(std::current_exception());
}
//也可以用std::copy_exception(std::logic_error("foo ")),这个是直接存储不抛出
//当还没有就绪状态的future,此时调用std::promise 或者std::packaage_task的析构函数的时候将会存储一个std::future_errc::broken_promise错误状态。模板的一些小注意
如果是为模板里面的类型定义别名必须设置typename,如果要访问 模板里面的嵌套类型的时候,必须使用typename
template <typename T>
using RebindAlloc = typename std::allocator_traits<T>::template rebind_alloc<char>;多个线程等待: :::tips 提醒
//std::future<>是只移动的,虽然允许所有权在不同实例中互相传递但是,当第一次get()之后就不再能够获取数据。
//std::shared_future<>实例是可以拷贝的,多个对象可以引用同一关联期望的结果,每一个独立对象的成员函数的调用结果其实还是独立的,需要利用锁进行保护。
//优先使用的办法:为了替代只有一个拷贝对象的情况,让每个线程都拥有自己对应的拷贝对象。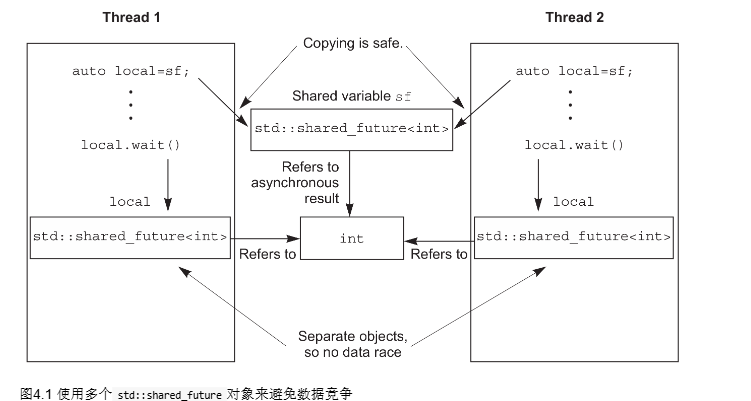
std::promise<int> p;
std::future<int> f(p.get_future());
assert(f.valid()); // 1 "期望" f 是合法的
std::shared_future<int> sf(std::move(f));
assert(!f.valid()); // 2 "期望" f 现在是不合法的
assert(sf.valid()); // 3 sf 现在是合法的
// 因为std::future 被移动了之后导致f失效了
//更好的方法
std::promise<type> p;
//std::promise<someindex,somedata,somecompare,someallocator>
std::shared_future<type> sf = p.get_future().share();限定等待时间
一般阻塞调用是设置由线程等待时间的。
有两种指定超时方式:一种叫做时间段、一种叫做时间点。
大部分这些标准的函数:时间段:_for(wait_for()) 时间点: _until(wait_until)
时钟:
信息
时钟是一个类提供了四种信息,包括:当前时间、时间类型、时钟节拍、稳定时钟。
当前时间可以通过静态成员函数now(),比如:stdsystem_clocknow()类型就是some_clock::time_point.
时钟节拍被指定为1/x秒,这是由时间周期所决定的,一个时钟一秒有25个节拍,可以表示为"std::ratio<1,25>",均匀分布且不能修改的时钟节拍叫做稳定时钟。
“std::chrono::steady_clock”是c++提供的一个稳定时钟。
“std::chrono::high_resolution_clock”是标准库里面提供的具有最小节拍周期的时钟。
时间段:
“std::chrono::duration<>”
第一个模板参数表示的是类型,第二个模板参数表示的是定制部分
std::chrono::duration<short,std::ratio<60,1>> //这个表示的以分钟时间记录,记录在short类型的数据之中 std::chrono::duration<double,std::ration<1,1000>> //表示要将毫秒级别的技术存在double类型之中
:::tips 小提示
标准库里面有一个预定义类型,可以直接使用.
#include<chrono>
//nanoseconds[纳秒]
//microseconds
//milliseconds
//seconds
//minutes
//hours
//c++14之后有了更多的预定义的后缀操作符
using namespace std::chrono_literals
auto one_day = 24h;
auto half_an_hour=30min;
auto max_time_between_messages=30ms;
//std::chrono::nanoseconds(15)=15ns;关于类型转换的方面的话,隐式转换方面,小时转换成秒是可以的但是秒转换成小时不太行。
//但是可以采用显式转换的方式进行
std::chrono::milliseconds ms(888);
std::chrono::seconds s = std::chrono::duration_cast<std::chrono::seconds>(ms);
//不过这个值是被截断的而不是四舍五入的计算值。
//时间段的类都是由count()函数的可以获取当前时间单位的数值。用法示例:
std::future<int> f = std::async(some_task);
if(f.wait_for(std::chrono::milliseconds(35))==std::future_status::ready())
{
do_something_with(f.get());
}
//future完成的三种状态std::future_status::ready(),std::future_status::timeout(),std::future_status::deferred:::
时间点:
“std::chrono::time_point<>”
注
第一个参数指定使用的时钟,第二个函数参数表示单位(特化的stdduration)
auto st = std::chrono::high+resolution_clock::now();//返回时间点
do_something();
auto stop = std::chrono::high_resolution_clock::now();
std::cout<<"do_something() took"
<<std:::chrono::duration<double,std::chrono::seconds>(stop-st).count()<<"seconds"<<std::endl;注
锁存器和栅栏
锁存器是一种同步对象,当计数器减少为0的时候变成就绪状态,锁存器基于器输出特性,当处于就绪之后就会保持就绪转要只到被销毁为止,是一种轻量级的同步机制。
栅栏锁一种可以复用的同步机制,用于一组线程之间的内部同步,虽然锁存器不在乎哪个线程是的计数器递减,同一个线程可以对计数器递减多次,但是对于栅栏来说每个线程在每个周期之内只能到达栅栏一次。每当线程到达栅栏的时候,就会对线程进行阻塞。直到所有线程都到达栅栏,阻塞就会被解除。
stdlatch-》基础的锁存器类型
:::tips 相关
声明在头文件<experimental/latch>,将计数器作为构造函数的唯一参数。递减就调用函数count_down当计数器为0的时候,锁存器就处于就绪状态。可以调用wait()进行阻塞,is_ready函数可用来检查是否就绪。有一个函数可以将前两者和一count_down_and_wait
:::
栅栏
::: tips 相关
提供了两种栅栏机制,在头文件<experimental/barrier>,分别是std::experimental::barrier和std::experimental::flex_barrier
std::experimental::barrier这种栅栏使用arrive_and_wait等待所有栅栏的到达。
std::experimental::flex_barrier这个栅栏在完成阶段,一旦参与线程集合中所有线程都到达同步点,由参与线程之一去执行完成阶段。
二者之间,第一个的构造函数:只需要传入需要构造的集合的大小,第二个有一个额外的构造函数,需要传入完整的函数和线程数量,当所有线程都到达栅栏之后,就由其中一个线程执行对应的函数,而且还支持修改下一周期的线程数量不像之前那个二u过要修改只能调用arrive_and_drop来让当前线程退出集合。
std::experimental::flex_barrier sync (n,[&]
{
//doeome;
return -1;//-1表示不更改线程数目,0或者其他数值就指定的是下一个周期中参与迭代的线程数量。
});:::
内存模型以及原子操作
简单介绍
主要内容包括:
- 内存模型
- 标准库里面的原子类型
- 如何使用原子类型
- 使用原子操作同步线程
c++标准中有一个重要特性就是多线程感知内存模型。
原子操作以及原子类型
- 一方面是内存布局
- 一方面是并发
原子操作
原子操作并没有指定访问的顺序,反而是将程序拉回定义行为的区域内。
原子操作是一个不可分割的操作。
标准原子类型:
标准原子类型定义在<atomic>,其中类型的操作都是原子的。(标准的实现可能是拥有一份is_lock_free()函数,然后这个函数可以让用户直接查询原子类型的操作是直接用的原子指令(x.is_lock_free()返回true,还是内部使用了一个锁结构(x.is_lock_free()返回false)).
原子类型要可以替代互斥量,就最好不用互斥量实现,因为用互斥量实现不可能有任何的提升,标准库提供了一组宏用来在编译的时候对各种整形原子操作是否无锁进行判断。c++17里面有一个static constexpr 成员变量,如果相应的硬件上的原子类型是无锁类型,那么X::is_always_lock_free将返回true。
通常标准院子类型不支持拷贝和复制,他们没有拷贝构造函数以及拷贝赋值操作符。但是可以隐式转化,所以这些类型支持赋值,通过调用load()、store()、exchange()、compare_exchange_weak()、compare_exchange_strong()。他们都支持使用复合运算符:+=、 -= 、*= 、|=等等在指针以及整型的特化类型下面支持++和--(对应了函数fetch_add()、fetch_or()等等。
以上的哪些函数都有一种叫做内存序参数的变量,这个参数可以用来指定存储的顺序。
重要
store: memory_order_relaxed、memory_order_relaxed、memory_order_seq_cst;
load : memory_order_relaxed 、memory_order_consume、memory_order_acquire、memory_order_seq_cst
Read-modify-write(读-改-写):memory_order_relaxed、memory_order_consume、memory_order_acquire、
memory_order_release、memory_order_acq_rel、memory_order_seq_cst